背景
企业开发中经常会遇见某个业务使用频繁,导致数据量特别大,而MySQL的单表承载的数据量有限,一般在1000万以内,字段多一些还会更少,我们解决这种业务就需要对数据进行拆分,也叫sharding ,将一个表拆分多个表,或者多个数据库,本次就介绍一下分表,知道分表逻辑分库也就不再是个难事。
几个概念
拆分因子:拆分因子也就是我们要按照什么维度拆分,比如,按照用户维度拆分,还是按照商户维度,还是其他,这里的用户和商户就是拆分因子,拆分因子的选取和业务强绑定,需要重点考虑。
哈希:也叫散列,百度百科中叫做将任意长度的输入,通过散列算法变换成固定长度的输入。
拆分因子选择
因子选择,要看这个表所支撑的业务
举例1、京东的京豆
京豆是属于用户维度的,我们的操作都是查询某个人的京豆,所以这个京豆库存流水信息就可以按照用户维度进行拆分,保证同一个人的京豆都存储在同一张表里面。
举例2、电商的商品信息
商品信息属于商家维度,我们一般都是进到一个店铺,查看这个店铺有哪些商品,商家查看自己的商品,所以这个商品信息就可以按照商家维度拆分,保证同一个商家的信息在同一表里面。
极端例子:订单表
订单表即属于商家,又属于用户,此时我们的选择是优先用户,可以按照用户维度进行拆分,其次通过冗余索引或冗余数据来为商户提供服务,比如创建一套商户维度的数据,然后商户维度数据采用异步非实时的机制进行同步数据,
拆分方法
如果你的业务是按照时间进行分表,每隔一段时间创建一个新表的话,就没有具体的拆分方式了,一定时间创建一个新表就可以了,但如果是有拆分因子,可以按照如下步骤考虑:
1、预估容量
预估该系统要支撑几年,大概的一个数据量,按照每个表1000w左右进行评估,如果未来5年可以达到1亿数据,那么拆分10张表即可,加上一定的上浮空间,一般用2的倍数,拆分成16张就够了。
2、考虑扩展性
如果我们16张表不够用的时候,该怎么办,那32张是否足够,如果提前做好扩展性。
实践
比如每个订单,都给用户发放一定的奖励金,我们要记录每次发放的奖励金信息,我们按照用户维度进行分表;
1、每天100w订单,也就100w条记录
2、系统支撑5年,5*365*100w 约等于 18.25亿
3、每张表最多存1000w数据,大约182张表
考虑到扩展性 我们准备最多分256张表(2的倍数)可以先拆分出16张表,随着业务扩展最多分256张
表的命名,bounty_001,bounty_016,bounty_032 ... bounty_240 累计16张表,选择等步长为了每个表之间可以做扩展(稍后讲到)
定位数据应该存储的表
一致性HASH的方式,大家可以自行百度一致性Hash算法
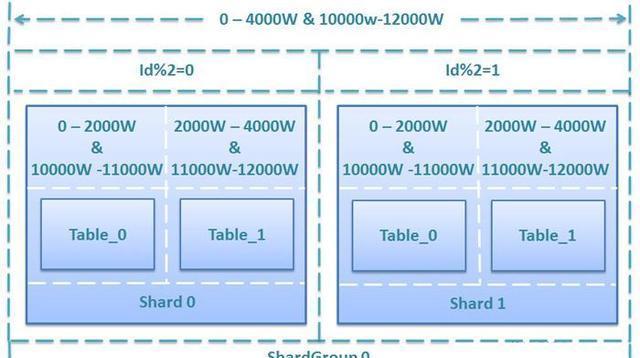
hash(userId)%256 = shardIndex ;对用户标识进行hash,然后除以256,取余数;
hash是哈希算法,推荐guava工具包有几个hash算法实现,
256是因为我们最多要拆分256张表,取余数就是为了定位数据需要存到那个后缀的表中。
可以维护一套余数与表之间的映射
1->bounty_001
2->bounty_001
.....
15->bounty_001
16->bounty_016
17->bounty_017
这样当计算出余数,就能从这个映射中知道应该存储到哪张表里面,通过动态组装SQL,变更表名,直接插入到对应的数据库即可。
扩容
当然我们可以直接一次性拆分256张表或者更多直接满足业务需求,但那样也会给我们的系统的维护带来一定的复杂度,毕竟每张表我们都要处理,所以常规都是按照上面的做法,先少分几张,保证业务应用,随着业务的增长再继续扩容。
上例中,如果我们需要扩容,我们可以在后缀为001和016之间,新建bounty_008,然后修改映射关系,将余数8-15的数据存储到bounty_008表中,同时将bounty_001表中的数据,复合余数8-15之间的数据,转移到bounty_008中,这就完成了数据表的扩容;
企业开发中经常会遇见某个业务使用频繁,导致数据量特别大,而MySQL的单表承载的数据量有限,一般在1000万以内,字段多一些还会更少,我们解决这种业务就需要对数据进行拆分,也叫sharding ,将一个表拆分多个表,或者多个数据库,本次就介绍一下分表,知道分表逻辑分库也就不再是个难事。
几个概念
拆分因子:拆分因子也就是我们要按照什么维度拆分,比如,按照用户维度拆分,还是按照商户维度,还是其他,这里的用户和商户就是拆分因子,拆分因子的选取和业务强绑定,需要重点考虑。
哈希:也叫散列,百度百科中叫做将任意长度的输入,通过散列算法变换成固定长度的输入。
拆分因子选择
因子选择,要看这个表所支撑的业务
举例1、京东的京豆
京豆是属于用户维度的,我们的操作都是查询某个人的京豆,所以这个京豆库存流水信息就可以按照用户维度进行拆分,保证同一个人的京豆都存储在同一张表里面。
举例2、电商的商品信息
商品信息属于商家维度,我们一般都是进到一个店铺,查看这个店铺有哪些商品,商家查看自己的商品,所以这个商品信息就可以按照商家维度拆分,保证同一个商家的信息在同一表里面。
极端例子:订单表
订单表即属于商家,又属于用户,此时我们的选择是优先用户,可以按照用户维度进行拆分,其次通过冗余索引或冗余数据来为商户提供服务,比如创建一套商户维度的数据,然后商户维度数据采用异步非实时的机制进行同步数据,
拆分方法
如果你的业务是按照时间进行分表,每隔一段时间创建一个新表的话,就没有具体的拆分方式了,一定时间创建一个新表就可以了,但如果是有拆分因子,可以按照如下步骤考虑:
1、预估容量
预估该系统要支撑几年,大概的一个数据量,按照每个表1000w左右进行评估,如果未来5年可以达到1亿数据,那么拆分10张表即可,加上一定的上浮空间,一般用2的倍数,拆分成16张就够了。
2、考虑扩展性
如果我们16张表不够用的时候,该怎么办,那32张是否足够,如果提前做好扩展性。
实践
比如每个订单,都给用户发放一定的奖励金,我们要记录每次发放的奖励金信息,我们按照用户维度进行分表;
1、每天100w订单,也就100w条记录
2、系统支撑5年,5*365*100w 约等于 18.25亿
3、每张表最多存1000w数据,大约182张表
考虑到扩展性 我们准备最多分256张表(2的倍数)可以先拆分出16张表,随着业务扩展最多分256张
表的命名,bounty_001,bounty_016,bounty_032 ... bounty_240 累计16张表,选择等步长为了每个表之间可以做扩展(稍后讲到)
定位数据应该存储的表
一致性HASH的方式,大家可以自行百度一致性Hash算法
hash(userId)%256 = shardIndex ;对用户标识进行hash,然后除以256,取余数;
hash是哈希算法,推荐guava工具包有几个hash算法实现,
256是因为我们最多要拆分256张表,取余数就是为了定位数据需要存到那个后缀的表中。
可以维护一套余数与表之间的映射
1->bounty_001
2->bounty_001
.....
15->bounty_001
16->bounty_016
17->bounty_017
这样当计算出余数,就能从这个映射中知道应该存储到哪张表里面,通过动态组装SQL,变更表名,直接插入到对应的数据库即可。
扩容
当然我们可以直接一次性拆分256张表或者更多直接满足业务需求,但那样也会给我们的系统的维护带来一定的复杂度,毕竟每张表我们都要处理,所以常规都是按照上面的做法,先少分几张,保证业务应用,随着业务的增长再继续扩容。
上例中,如果我们需要扩容,我们可以在后缀为001和016之间,新建bounty_008,然后修改映射关系,将余数8-15的数据存储到bounty_008表中,同时将bounty_001表中的数据,复合余数8-15之间的数据,转移到bounty_008中,这就完成了数据表的扩容;
以上就是简单的数据库分表实践,是不是很简单,实际业务可能会遇到更复杂的,就像举例3中的场景。那就需要附加索引或者异步冗余,或者借助其他方式如ES等来解决。写的不好大家多多指正
转载网址:https://baijiahao.baidu.com/s?id=1579607517769172507&wfr=spider&for=pc