一、分表
1、垂直分割:就是将一个表按照字段来分,每张表保证有相同的主键就好。一般来说,将常用字段和大字段分表来放。
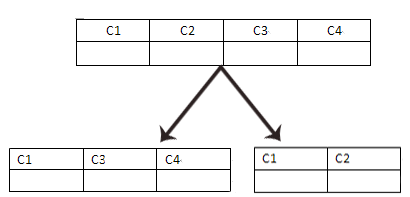
优势:比没有分表来说,提高了查询速度,降低了查询结果所用内存;
劣势:没有解决大量记录的问题,对于单表来说随着记录增多,性能还是下降很快;
2、水平分割:水平分割是企业最常用到的,水平拆分就是大表按照记录分为很多子表:
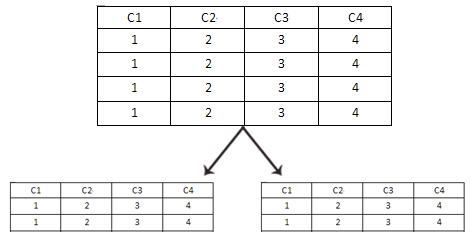
水平分的规则完全是自定义的,有以下几种参考设计:
1、hash、自增id取模:对某个字段进行hash来确定创建几张表,并根据hash结果存入不同的表;
2、按时间:根据业务可以按照天、月、年来进行拆分;
3、按每个表的固定记录数:一般按照自增ID进行拆表,一张表的数据行到了指定的数量,就自动保存到下一张表中。比如规定一张表只能存1-1000个记录;
4、将老数据迁移到一张历史表:比如日志表,一般只查询3个月之内的数据,对于超过3个月的记录将之迁移到历史子表中;
二、分区:
分区就是把一个数据表的文件和索引分散存储在不同的物理文件中。mysql支持的分区类型包括Range、List、Hash、Key,其中Range比较常用:
1、RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。
create table t_range(
id int(11),
money int(11) unsigned not null,
date datetime
)partition by range(year(date))(
partition p2007 values less than (2008),
partition p2008 values less than (2009),
partition p2009 values less than (2010)
partition p2010 values less than maxvalue #MAXVALUE 表示最大的可能的整数值
);
RANGE分区在如下场合特别有用:
1)、当需要删除一个分区上的“旧的”数据时,只删除分区即可。如果你使用上面最近的那个例子给出的分区方案,你只需简单地使用”ALTER TABLE employees DROP PARTITION p0;”
来删除所有在1991年前就已经停止工作的雇员相对应的所有行。对于有大量行的表,这比运行一个如”DELETE FROM employees WHERE YEAR (separated) <= 1990;”
这样的一个DELETE查询要有效得多。
2)、想要使用一个包含有日期或时间值,或包含有从一些其他级数开始增长的值的列。
3)、经常运行直接依赖于用于分割表的列的查询。
例如,当执行一个如”SELECT COUNT(*) FROM employees WHERE YEAR(separated) = 2000 GROUP BY store_id;”这样的查询时,
MySQL可以很迅速地确定只有分区p2需要扫描,这是因为余下的分区不可能包含有符合该WHERE子句的任何记录2、LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
create table t_list(
a int(11),
b int(11)
)(partition by list (b)
partition p0 values in (1,3,5,7,9),
partition p1 values in (2,4,6,8,0)
);
LIST分区没有类似如“VALUES LESS THAN MAXVALUE”这样的包含其他值在内的定义。将要匹配的任何值都必须在值列表中找到。3、HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
CREATE TABLE user (
id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY HASH (id) PARTITIONS 4 (
PARTITION p0 ,
PARTITION p1,
PARTITION p2,
PARTITION p3
);4、KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
CREATE TABLE user (
id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY KEY (id) PARTITIONS 4 (
PARTITION p0,
PARTITION p1,
PARTITION p2,
PARTITION p3
); 5、分区的限制:
1.主键或者唯一索引必须包含分区字段,如primary key (id,username),不过innoDB的大组建性能不好。
2.很多时候,使用分区就不要在使用主键了,否则可能影响性能。
3.只能通过int类型的字段或者返回int类型的表达式来分区,通常使用year或者to_days等函数(mysql 5.6 对限制开始放开了)。
4.每个表最多1024个分区,而且多分区会大量消耗内存。
5.分区的表不支持外键,相关的逻辑约束需要使用程序来实现。
6.分区后,可能会造成索引失效,需要验证分区可行性。
整理自: