Gan的基本介绍
GAN(Generative Adversarial Networks)被Lan Goodfellow提出以后,各种Gan遍地开花,GAN掀起了一场技术革命在各个领域的应用都取得了重大突破, 图灵奖得主Yann LeCun也称近Gan是20年来深度学习领域最棒的想法。身为小白的我也久仰Gan的大名,在寒假期间终于有时间能实操一下Gan的训练(期待的搓搓小手(ง˃̀ꄃ˂́)۶)

GAN的核心思想是博弈,将网络划分为生成器(Generator)和判别器(Discriminator),生成器并不直接接触真实数据生成一张Fake image企图骗过后面的判别器,而判别器则要不断提高自身的判别能力以判别出图像的真假,两个网络不断博弈最终就能得到一个能够生成逼真图像的Generator, 而Generator是没有直接看过真实图像的。

Gan的训练过程
训练Gan时首先训练判别器然后固定判别器的参数,再给generator输入低维噪声得到Fake Image交给判别器判别计算loss反向传播更新Generator的参数。当判别器的准确率不足或者说生成器的拟合能力已经达到了判别器判别能力的上限再用带真假标签的真图和假图训练更新判别器的参数,如此循环。
生成器主要从一个低维度的数据分布中不断拟合真实的高维数据分布,而判别器主要是为了区分数据是来源于真实数据还是生成器生成的数据,他们之间相互对抗,不断学习,最终达到Nash均衡,即任何一方的改进都不会导致总体的收益增加,这个时候判别器再也无法区分是生成器生成的数据还是真实数据。

Autoencoder
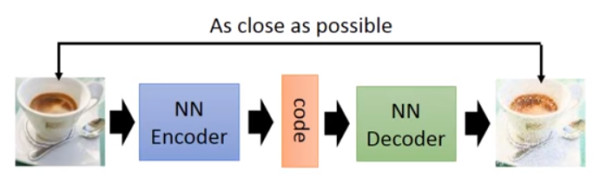
说到Gan就不得不提同样是寻找低维特征来表示高维数据分布的自编码器(Autoencoder)编码器通过选择和抽取特征将数据编码到低维隐层特征空间z中,解码器则相反。自编码器的损失函数就是编码时最大化信息保留和解码之后最小化重构损失。Autoencoder通过自学习的方式能够学习到由低维隐层空间解码到原图的方法,其中Decoder做的事情跟Gan的Generator的工作就很类似,所以Decoder也曾经被作为一种生成器但效果不好,目前Autoencoder主要用来进行数据降维和特征抽取(通过降低隐层特征空间(编码空间)的维度,达到降维的作用)。研究Autoencoder的意义在于更好的理解Generator在做些什么。
自己实现的加入噪声的deepAutoencoder效果还不错(第一行为原图+高斯噪声,第二行为Autoencoder输出,第三行为原图)

Vae
Vae(Variational Auto-Encoder)可以说是AE的豪华升级版,VAE的最大特点是模仿自动编码机的学习预测机制,在可测函数之间进行编码、解码。同GAN类似,其最重要的idea是基于一个令人惊叹的数学事实:对于一个目标概率分布,给定任何一种概率分布,总存在一个可微的可测函数,将其映射到另一种概率分布,使得这种概率分布与目标的概率分布任意的接近
对于未知的隐层空间z的分布Gan是采用暴力破解的方法直接通过对抗拟合到z的分布。而VAE的思想则不同,VAE假设z空间中的每一维特征都影响着真实空间的某个特征,例如下图中的结果中从左上到右下字符逐渐倾倒且圈圈逐渐消失,就可以认为x轴(z空间的某一维度)对应真实字符有没有圈圈,y轴(z空间的另一维度)对应字符的倾倒程度。对于GAN的暴力求解,VAE的建模思路无疑要复杂的多,它更能体现思维的艺术感。
由于VAE在训练过程中引入了噪声(下图中的e)使VAE具有了产生一些没有见过的图片的能力,比如训练集中只有半月和满月的图片VAE能够生成办满月的图片。另外VAE的损失函数由两部分构成:
1.重构损失函数(inputs和outputs的交叉熵)
2.学习到的隐分布和先验分布的kl距离
模型的loss为这两项的和

手动实现的VAE结果展示:

Gan到DCGan
在我们的印象中: 卷积 = 对图像处理来说很有用, GANs = 适合生成一些东西, 所以 卷积+GANs = 适合生成图像? 于是DCGan(Deep Convolution Gan)应运而生。DCGan主要在一下几点对Gan进行了改进:
1、G,D网络不采取任何池化
2、G,D网络每一层均使用批标准化处理(Batch-Normalization)
3、在G网络中,激活函数除了最后一层外,都是用Relu函数,最后一层使用 tanh函数
4、D网络中,激活函数均使用Leaky Relu函数。
由于替换掉了全连接,DCGan中使用了反卷和卷积操作实现数据的升降维,其中反卷积操作本质上应该叫转置卷积(Transpose Convolution)除此之外DCGan与Gan并没有什么结构上的差异。
Gan(网图 有些过拟合):

实现DCGan:

Tip:在利用公式计算Generator中的转置卷积输出维度时可能会遇到与对应的卷积操作不对应的情况,这是由于计算卷积时如果遇到输出维度带小数一般会取整,导致计算转置卷积时得不到正确输出维度,这时可以先用Generator的Output进行卷积倒推出Input,这样得到的隐层空间维度就是正确的维度。
Gan到CGan(Conditional Gan)
原始的Gan只是学习到了输入一个噪声生成一个“数字”说生成一个看起来像“数字”的字符,但是Gan自己都不知道它生成的是哪个数字,Gan不像VAE能够控制Encoder的输入(z)获取到没有见过的图像,Gan由隐空间到真实空间的转换完全由Generator自行学习
为了能让Gan随心所欲的生成想要的结果,CGan的作者在Generator的输入层增加了由One hot 编码得到的label y, 同时在训练Discriminator的时候也引入label y
,这样就使得Generator不仅仅要生成一个数字而且还要像“y”。 条件生成对抗的思想使Gan有了更多的用武之地。

CGan在Mnist上训练3000轮结果:

CDCGan
我在CGan的基础上将网络中引入了卷积,并将ONE HOT替换为Embedding,优化了网络结构同时也增加了网络深度,得到的效果要比CGAN好的多。
CDCGan300轮训练结果:

Tips: 在搭建CGan时可能会遇到Conditional label与Generator Input或者Discriminator Input的拼接问题,建议使用Embedding即使Conditional label在Generator和Discriminator中输入的维度不同也能train,而且Embedding层的参数还能自动更新。
由于用到的模型较多这里只放CDCGan的核心代码 Github链接:答应给我star才能点(๐•̆ ·̭ •̆๐)
class CGan(object):
def __init__(self, config, weight_path = None):
"""
CGan初始化函数
:param config:配置文件
:param weight_path: 已有权重路径
"""
self.config = config
self.build_cgan_model()
if weight_path is not None:
self.cgan.load_weights(weight_path, by_name = True)
def build_cgan_model(self):
"""
build cgan model
:return:
"""
#初始化输入
self.generator_noise_input = Input(shape=(self.config.generator_noise_input_dim,))
self.discriminator_image_input = Input(shape=self.config.discriminator_image_input_dim)
self.contational_label_input = Input(shape=(1,), dtype='int32')
#定义优化器
self.optimizer = Adam(lr=2e-4, beta_1=0.5)
#构建生成器模型与判别器模型
self.discriminator_model = self.build_discriminator_model()
self.discriminator_model.compile(optimizer=self.optimizer, loss='binary_crossentropy', metrics=['accuracy'])
self.generator_model = self.build_generator()
#构建CGan
self.discriminator_model.trainable = False
self.cgan_input = [self.generator_noise_input, self.contational_label_input]
generator_output = self.generator_model(self.cgan_input)
self.discriminator_input = [generator_output, self.contational_label_input]
self.cgan_output = self.discriminator_model(self.discriminator_input)
self.cgan = Model(self.cgan_input, self.cgan_output)
self.cgan.compile(optimizer=self.optimizer, loss='binary_crossentropy')
plot_model(self.cgan, "./model/CDCGan_Model.png")
plot_model(self.generator_model, "./model/CDCGan_generator.png")
plot_model(self.discriminator_model, "./model/CDCGan_discriminator.png")
def build_discriminator_model(self):
"""
:return:
"""
model = Sequential()
model.add(Conv2D(64, kernel_size=3, strides=2, padding='same',
input_shape=self.config.discriminator_image_input_dim))
model.add(LeakyReLU(alpha=self.config.LeakyReLU_alpha))
model.add(Dropout(rate=self.config.dropout_prob))
model.add(Conv2D(128, kernel_size=3, strides=2, padding='same'))
model.add(LeakyReLU(alpha=self.config.LeakyReLU_alpha))
model.add(Dropout(rate=self.config.dropout_prob))
model.add(Conv2D(256, kernel_size=3, strides=2, padding='same'))
model.add(LeakyReLU(alpha=self.config.LeakyReLU_alpha))
model.add(Dropout(rate=self.config.dropout_prob))
model.add(Conv2D(512, kernel_size=3, strides=2, padding='same'))
model.add(LeakyReLU(alpha=self.config.LeakyReLU_alpha))
model.add(Dropout(rate=self.config.dropout_prob))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=self.config.discriminator_image_input_dim)
label = Input(shape=(1,), dtype='int32')
label_embedding = (Embedding(self.config.condational_label_num,
np.prod(self.config.discriminator_image_input_dim))(label))
label_embedding = Reshape(self.config.discriminator_image_input_dim)(label_embedding)
model_input = multiply([img, label_embedding])
validity = model(model_input)
return Model([img, label], validity)
def build_generator(self):
"""
这是构建生成器网络的函数
:return:返回生成器模型generotor_model
"""
model = Sequential()
model.add(Dense(7*7*256, input_shape=(self.config.generator_noise_input_dim, ), activation='relu'))
model.add(BatchNormalization(momentum=self.config.batchnormalization_momentum))
model.add(Reshape((7, 7, 256)))
model.add(Conv2DTranspose(128,kernel_size=3, strides=2, padding='same', activation='relu'))
model.add(BatchNormalization(momentum=self.config.batchnormalization_momentum))
model.add(Conv2DTranspose(64, kernel_size=3, strides=2, padding='same', activation='relu'))
model.add(BatchNormalization(momentum=self.config.batchnormalization_momentum))
model.add(Conv2DTranspose(32, kernel_size=3, padding='same', activation='relu'))
model.add(BatchNormalization(momentum=self.config.batchnormalization_momentum))
model.add(Conv2DTranspose(self.config.discriminator_image_input_dim[2], kernel_size=3,
padding='same', activation='tanh'))
model.summary()
noise = Input(shape=(self.config.generator_noise_input_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.config.condational_label_num, self.config.generator_noise_input_dim)(label))
model_input = multiply([noise, label_embedding])
img = model(model_input)
return Model([noise, label], img)
环境
操作系统:Windows 64 内存8g
显卡:GTX1050
python:3.6.9
tensorflow-gpu:1.12
keras: 2.24
参考文献:
https://www.sohu.com/a/325882199_114877
https://www.sohu.com/a/226209674_500659
结语
寒假一个月收获不少,明天开始就要全力准备考研了要跟瞎玩模型告一段落了hhh下次写博客可能就是一年后了 Fighting!!!
ps:深深体会到了穷人不配深度学习,一跑就是好几天 电脑快给我烤化了,立个flag:明年暑假赚到钱尝试在云上跑吼吼吼
