目录
1.ArrayList是什么?可以用来干嘛?2.ArrayList数组的初始大小长度是怎样的?长度不够时怎么办.3.为什么说数组增删速度慢,增删时ArrayList是怎么实现的?4.ArrayList(int initialCapacity)是初始化数组大小吗?5.ArrayList是线程安全的么?怎样线程安全的使用ArrayList呢?6.ArrayList适合用来做队列么?7.removeAll, retrain, clean三个方法有什么不同?8.ArrayList的浅复制和深复制有什么不同?分别怎样实现?总结:
1.ArrayList是什么?可以用来干嘛?
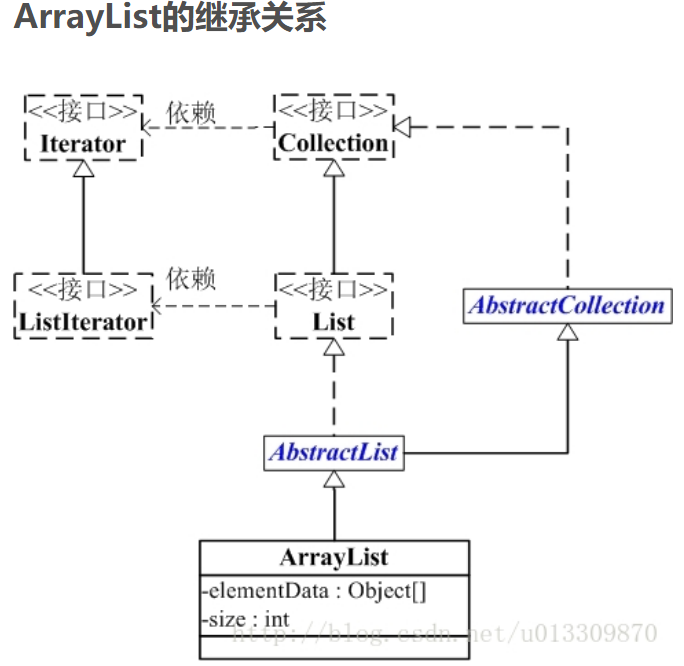
ArrayList就是数组列表,主要用来装载数据,当我们装载的是基本类型的数据时int,long,boolean,short,byte…的时候我们只能存储他们对应的包装类,它的主要底层实现是数组Object[] elementData。
与它类似的是LinkedList,和LinkedList相比,它的查找和访问元素的速度较快,但新增,删除的速度较慢。
小结:ArrayList底层是用数组实现的存储。
特点:查询效率高,增删效率低,线程不安全。使用频率很高。
正常使用的场景中,都是用来查询,不会涉及太频繁的增删,如果涉及频繁的增删,可以使用LinkedList,如果你需要线程安全就使用Vector,这就是三者的区别了,实际开发过程中还是ArrayList使用最多的。
补充:
| 基本类型 | 包装器类型 |
|---|---|
| boolean | Boolean |
| char | Character |
| int | Integer |
| byte | Byte |
| short | Short |
| long | Long |
| float | Float |
| double | Double |
1ArrayList<Boolean> list1 = new ArrayList<Boolean>();
2ArrayList<Character> list2 = new ArrayList<Character>();
3ArrayList<Integer> list3 = new ArrayList<Integer>();
4ArrayList<Byte> list4 = new ArrayList<Byte>();
5ArrayList<Short> list5 = new ArrayList<Short>();
6ArrayList<Long> list6 = new ArrayList<Long>();
7ArrayList<Float> list7 = new ArrayList<Float>();
8ArrayList<Double> list8 = new ArrayList<Double>();
2.ArrayList数组的初始大小长度是怎样的?长度不够时怎么办.
ArrayList可以通过构造方法在初始化的时候指定底层数组的大小。
通过无参构造方法的方式ArrayList()初始化,则赋值底层数Object[] elementData为一个默认空数组Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}所以数组容量为0,只有真正对数据进行添加add时,才分配默认DEFAULT_CAPACITY = 10的初始容量。
源码中可以看到它的构造器,无参就是默认大小,有参会判断参数。
1public ArrayList() {
2this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
3}
1/**
2* Default initial capacity.
3*/
4private static final int DEFAULT_CAPACITY = 10;
5
6public ArrayList(int initialCapacity) {
7if (initialCapacity > 0) {
8this.elementData = new Object[initialCapacity];
9} else if (initialCapacity == 0) {
10this.elementData = EMPTY_ELEMENTDATA;
11} else {
12throw new IllegalArgumentException("Illegal Capacity: "+
13initialCapacity);
14}
15}
当长度不够时,自动增长原来长度的0.5倍。
比如我们现在有一个长度为10的数组,现在我们要新增一个元素,发现已经满了,那ArrayList会怎么做呢?

首先会重新定义一个长度为(原来数组长度)10+10/2的长度的新数组.

然后把原数组的数据复制到新数组中,把指向原数组的地址重新指向新数组.
在实际场景中,尽量开始就定义好大致准确的数组长度,避免扩容带来的消耗.
3.为什么说数组增删速度慢,增删时ArrayList是怎么实现的?
首先新增元素时数组的扩容问题,扩容的时候,老版本的jdk和8以后的版本是有区别的,8之后的效率更高了,采用了位运算,右移一位,其实就是除以2这个操作。1.7的时候3/2+1 ,1.8直接就是3/2。
其次新增插入元素时, 在插入元素后面的数据的索引需要顺位向后移动,比如下面这样一个数组我需要在index 5的位置去新增一个元素A.

插入元素从index 5的位置开始的,然后把它放在了index 5+1的位置,腾出一个空位,后面元素依次向后移动.

所以为什么说它效率低了, 插入一个元素,需要移动后面所有的元素, 涉及到数组扩容还得全部复制一遍. 能不慢嘛.
插入的速度有多慢取决于插入元素距离末尾元素有多远,后面需要移动的元素越多它越慢.
ArrayList拿来作为堆栈来用还是挺合适的,push和pop操作完全不涉及数据移动操作。
删除元素道理也是一样, 和插入反向移动元素. 也需要复制数组(不包含删除的元素).一样的慢。
4.ArrayList(int initialCapacity)是初始化数组大小吗?
会, 但是打印数组的size仍然为0. 结合set()使用还会抛出异常,因为数组已经创建也设置了大小,但数组内部的值得数量始终是0啊.
1ArrayList<String> list = new ArrayList<String>(5);
2System.out.println(list.size());// 输出结果: 0
5.ArrayList是线程安全的么?怎样线程安全的使用ArrayList呢?
不是,线程安全版本的数组容器是Vector。
用Collections.synchronizedList把一个普通ArrayList包装成一个线程安全版本的数组容器也可以,原理同Vector是一样的,就是给所有的方法套上一层synchronized。
6.ArrayList适合用来做队列么?
队列是FIFO(先入先出)的,如果用ArrayList做队列,就需要在数组尾部追加数据,数组头部删除数组,反过来也可以。
但是无论如何总会有一个操作会涉及到数组的数据搬迁,这个是比较耗费性能的。所以ArrayList不适合做队列.
7.removeAll, retrain, clean三个方法有什么不同?
首先clean 是清空数组列表中所有的元素,容易理解.
boolean removeAll(Collection c);
removeAll 作用是在数组列表中删除参数集合c 中的所有出现的元素. 可以理解成求差集.
比如,原数组列表值是a,b,c,a,b,c; 传入的参数集合为a; removeAll后, 原数组列表只剩下b,c,b,c.
1// boolean removeAll(Collection<?> c);
2// 从列表中移除指定参数集合 c 中包含的其所有元素(删除交集元素,一个不留!);返回true|false.
3ArrayList<String> delList3 = new ArrayList<String>();
4delList3.add("a");
5delList3.add("b");
6delList3.add("c");
7delList3.add("a");
8delList3.add("b");
9delList3.add("c");
10
11System.out.println();
12for(String item: delList3) {
13System.out.print(item);//输出: abcabc
14}
15
16System.out.println();
17//比如删除数组中所有的a元素
18boolean retVal2 = delList3.removeAll(Arrays.asList("a"));
19System.out.println(retVal2);//输出: true
20for(String item: delList3) {
21System.out.print(item);//输出: bcbc
22}
boolean retainAll(Collection c)
retrain则相反,只保留数组列表中和传入集合c中相同的元素,可以理解成求交集.
比如,原数组列表是a,b,c,a,b,c; 传入的参数集合为a,b;retainAll后,原数组列表只剩下a,b,a,b.
1// boolean retainAll(Collection<?> c)
2// 和removeAll相反,retainAll只在原有数组中保留参数集合c中相等的元素;返回true|false.
3ArrayList<String> delList4 = new ArrayList<String>();
4delList4.add("a");
5delList4.add("b");
6delList4.add("c");
7delList4.add("a");
8delList4.add("b");
9delList4.add("c");
10System.out.println();
11for(String item: delList4) {
12System.out.print(item);//输出: abcabc
13}
14//比如,除了传入的a,b外,原数组a,b以外的元素(c)都删除.
15boolean retVal04 = delList4.retainAll(Arrays.asList("a","b"));
16System.out.println(retVal04);//输出结果
17
18System.out.println();
19for(String item: delList4) {
20System.out.print(item);//输出: abab
21}
8.ArrayList的浅复制和深复制有什么不同?分别怎样实现?
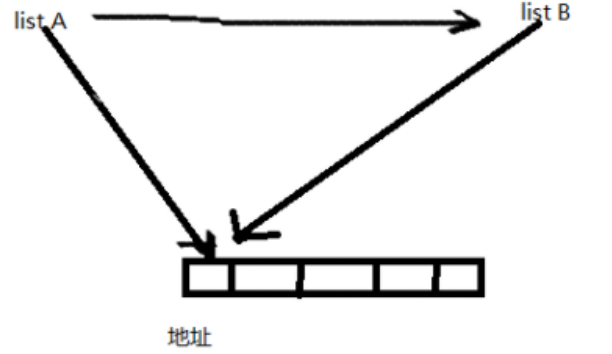
如图所示,将List A列表复制时,其实相当于A的内容复制给了B,java中相同内容的数组指向同一地址,即进行浅拷贝后A与B指向同一地址。
造成的后果就是,改变B的同时也会改变A,因为改变B就是改变B所指向地址的内容,由于A也指向同一地址,所以A与B一起改变。这也就是List的浅拷贝。

深拷贝就是将A复制给B的同时,给B创建新的地址,再将地址A的内容传递到地址B。ListA与ListB内容一致,但是由于所指向的地址不同,所以改变相互不受影响。
深复制和浅复制的概念是建立在对象的基础上的,对基本数据类型不通用. 开发者需要在概念上理解深度复制和浅复制.
举个例子:
创建一个User对象并添加到list1 中,通过clone 方法复制出list2. 通过修改list2的user对象, list1中也被修改了,
此处list1 和list2是浅复制关系.两者公用同一个User对象.指向地址相同.
1// 浅复制
2ArrayList<User> list1 = new ArrayList<User>();
3User user1 = new User("1","Tom");
4list1.add(user1);
5
6ArrayList<User> list2 = (ArrayList<User>) list1.clone();
7for(User item: list2) {
8System.out.print(item.toString());//输出: User [id=1, name=Tom]
9}
10System.out.println();
11list2.get(0).setName("Mike");
12System.out.println(list1);//输出: [User [id=1, name=Mike]]
13System.out.println(list2);//输出: [User [id=1, name=Mike]]
再来看下深复制概念的例子:
通过addAll 和Collections.copy 来实现. newList中新添加了元素10. 原来的list并未受影响,
1//深复制
2List<Integer> list = new ArrayList<>();
3for (int i = 0; i < 10; i++) {
4list.add(i);
5}
6
7// list深度拷贝
8List<Integer> newList = new ArrayList<>();
9newList.addAll(list);
10Collections.copy(newList, list);
11newList.set(0, 10);
12
13System.out.println("原list值:" + list);//原list值:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
14System.out.println("新list值:" + newList);//新list值:[10, 1, 2, 3, 4, 5, 6, 7, 8, 9]
总结:
ArrayList是动态数组,提供了动态的插入和删除元素, 面试时问的时候没HashMap,ConcurrentHashMap频率高, 但碰到"热情"的面试官时也会问到; 在阅读源码时,不需要全部搞懂里面的每一个含义,根据英文翻译读懂关键几行就好,用的时候知道为什么会用它, 而不是只做一个现成的API调用工程师.
