1.前因后果
在网上看到了一种用Spark求平均值的算法,自己写了下,修改了一些错误,我这是能直接run起来的版本。我会在本文中对这段代码进行详细的讲解,以加强对reduceByKey用法的印象。耐心看完,保证你对reduceByKey算子理解且不会忘了。
首先把这位老哥测试的原始数据给大家:
FFF 578 GGG 839 EEE 566 AAA 815 AAA 334 FFF 268 BBB 963 FFF 173 EEE 160 EEE 309 AAA 131 AAA 312 GGG 472 BBB 78 AAA 80 FFF 968 EEE 774 GGG 960 FFF 226 CCC 725 GGG 671 CCC 155 AAA 927 BBB 41 EEE 622 BBB 4 BBB 715 CCC 201 GGG 131 EEE 16 EEE 872 GGG 44 EEE 71 AAA 303 FFF 39 BBB 410 CCC 349 CCC 401 AAA 53 EEE 189 GGG 411 EEE 580 AAA 215 CCC 355 EEE 470 FFF 227 GGG 501 AAA 753 CCC 385 DDD 239 BBB 146 CCC 897 CCC 670 DDD 778 AAA 993 CCC 757 CCC 802 FFF 159 AAA 841 BBB 273 DDD 317 DDD 483 FFF 482 FFF 620 CCC 415 FFF 142 EEE 462 AAA 783 GGG 452 BBB 258 AAA 752 EEE 483 BBB 0 BBB 242 DDD 743 GGG 175 EEE 308 AAA 516 BBB 971 BBB 280 DDD 774 FFF 791 GGG 479 CCC 647 DDD 548 CCC 253 DDD 493 FFF 678 CCC 81 AAA 258 FFF 436 BBB 658 DDD 350 GGG 418 BBB 229 FFF 834 CCC 74 DDD 398 GGG 561 FFF 813
然后开始写代码:
package com.imooc.bigdata.cp04
import org.apache.spark.{SparkConf, SparkContext}
object testApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test")
val sc = new SparkContext(sparkConf)
val data = sc.textFile("num.txt")
data.map(a => (a.split(" ")(0),(a.split(" ")(1).toInt,1)))
.reduceByKey((x,y) => (x._1 + y._1,x._2 + y._2))
.map(a => (a._1,a._2._1 / a._2._2)).sortByKey()
.collect().foreach(println)
}
}
run出来结果是这样的:
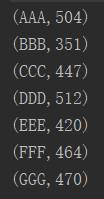
2.代码解释
首先是创建一个SparkConf,将其放在SparkContext中,然后利用SparkContext读取文件数据。坐下,常规操作。当然文件的地址你还得自己改一下。
val sparkConf = new SparkConf().setMaster("local").setAppName("test")
val sc = new SparkContext(sparkConf)
val data = sc.textFile("num.txt")接下来就是重头戏啦,一步步分析。首先理一下思路,我们的文件是一个“关键字(KEY)+空格+一个值(VALUE)”格式的,需要求平均值,只要把同样KEY的所有VALUE相加再除以KEY的个数就行啦,我们要处理得到的数据有关键字VALUE相加的总数及同一个VALUE出现的个数。
OK,来看第一行:
data.map(a => (a.split(" ")(0),(a.split(" ")(1).toInt,1)))以“FFF 578”为例,我们先将“FFF 578”通过空格拆开,将FFF放在第一个位置,578转成int(这里不转int之后会变成字符串的拼接而不是相加了)放在第二个位置,同时在第二个位置放了一个1。“FFF 578”就变成了“(FFF,(578,1))”,这个最后加上1是为了之后统计KEY的个数,MapReduce常规操作,坐下。截取一部分输出看看:

然后就轮到reduceByKey上场啦:
.reduceByKey((x,y) => (x._1 + y._1,x._2 + y._2))有点乱,没事,慢慢分析。
首先reduceByKey既然叫ByKey了,那就是按照关键字(KEY)进行归纳(reduce)呗,就是把相同的关键字里的VALUE进行归纳操作。既然是这样,潜台词就是KEY的操作我们不用管了,就是按照相同关键字做,所以我们在reduceByKey后面指定的仅是VALUE的操作。
我们怎么指定VALUE的操作呢?像map这种算子一次仅对一个对象操作,只要管一个就行了。但reduceByKey是归纳,肯定要涉及到两个或以上的对象,那我们就一次管两个对象,也就是你看到的(x,y)。举例来说,我们现在有:
(FFF,(578,1))
(FFF,(268,1))
那我们的x就是“(FFF,(578,1))”中的“(578,1)”,y就是“(FFF,(268,1))”中的“(268,1)”。为啥是这个不是“(FFF,(578,1))”?看看上面说的,我们在reduceByKey后面指定的仅是VALUE的操作。既然知道指代的是啥就好办了,“x._1”就是“578”,“y._1”就是“268”,把他两加上是为了求总数的,“x._2”就是“1”,“y._2”也是“1”,他两加上是为了计数的。
全部这样算完后,得到的结果是:

每个不同的KEY都给出了对应的总数和个数,我们只要除一下就可以啦:
.map(a => (a._1,a._2._1 / a._2._2)).sortByKey()这里的一个map操作和之前的reduceByKey不一样,是针对单个对象的,所以他们的称呼也得变回来。
以第一行“(EEE,(5882,14))”为例,“a._1”是“EEE”,“a._2”是“(5882,14)”,所以“5882”对应“a._2._1”,“14”对应“a._2._2”,把他两除一下就是平均数啦。
最后按Key排下序,好看些,结果就是:
OK~看懂的话加个关注吧

