java面试总结(二)
第二部分-集合类
1概述
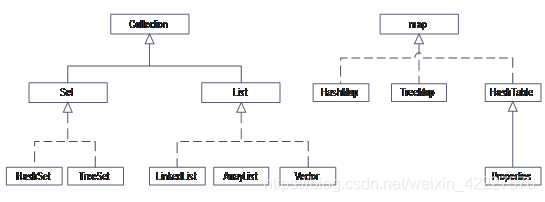
集合框架分为两部分:Collection(Set、List)和Map。(无序、唯一)
按照体系进行划分,集合类型可以分为三类:集(Set)列表(List)、映射(Map)。
1.1 Set
集合中不允许出现重复的元素;集合不区分元素顺序。
Set集合主要包括:HashSet、LinkedHashSet、TreeSet。
**HashSet:**此类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。
注意,此实现不是同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。
HashSet底层数据结构是哈希表(HashMap),哈希表依赖于哈希值存储,添加功能底层依赖两个方法:int hashCode(),boolean equals(Object obj)。
LinkedHashSet:具有可预知迭代顺序的 Set 接口的哈希表和链接列表实现。此实现与 HashSet 的不同之外在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,即按照将元素插入到 set 中的顺序(插入顺序)进行迭代。注意,插入顺序不 受在 set 中重新插入的 元素的影响。
哈希表保证元素的唯一性,链表保证元素有序,也就是存入顺序和取出顺序相同。
**TreeSet:**基于 TreeMap 的 NavigableSet 实现。使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。(底层结构是红黑树)
注意,此实现不是同步的。如果多个线程同时访问一个 TreeSet,而其中至少一个线程修改了该 set,那么它必须 外部同步。
有两种排序方式:A-自然排序,也是默认排序(实现Comparable),B-比较器排序。取决于构造方法。
1.2 List集合
List集合主要分为Arraylist、Linkedlist、Vector。(有序 可重复)
ArrayList集合底层是数组,而且是Object [] 类型;ArrayList集合查询数据很快,但是增删数据很慢;线程不安全。
LinkedList集合底层是链表,双向循环列表;非线性安全;LinkedList集合增删数据很快。但是查询数据很慢。
Vector实现了一个list接口,表示一个可变的对象数组,主要用于多线程环境下。线程安全。
1.3 Map集合
在存放的键值对中不允许有重复的键;每个键最多只能映射一个值。
实现方式有四种:HashMap,LinkedHashMap,Hashtable,TreeMap。
HashMap:基于hash表的Map接ロ的非同步实现,非线程安全,高效, 支持null値和null健,采用数组+链表+红黑树实现。存储数据采用哈希表结构,元素存取顺序不能保证一致。由于要保证键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。(基于散列表实现,采用对象的hashcode可以进行快速查询)
**HashTable:**线程安全,低效, 不支持null値和null健。
**LinkedHashMap:**是HashMap的一个子类,保存了记录的插入排序。存储数据采用的哈希表结构+链表结构。通过链表结构可以保证元素的存取顺序一致;通过哈希表结构可以保证的键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。采用列表来维护内部的顺序。
**SortMap:**TreeMap,能够把它保存的记录根据鍵排序,默认键值的升序排序。
2 Java中的HashMap的工作原理是什么?
Java中的HashMap是以键值对(key-value)的形式存储元素的。HashMap需要一个hash函数,它使用hashCode()和equals()方法来向集合/从集合添加和检索元素。当调用put()方法的时候,HashMap会计算key的hash值,然后把键值对存储在集合中合适的索引上。如果key已经存在了,value会被更新成新值。HashMap的一些重要的特性是它的容量(capacity),负载因子(load factor)和扩容极限(threshold resizing)。
**HashMap:**当程序试图将一个key-vlaue对放入HashMap中时,程序首先根据该key的hashCode()返回值决定该Entry的存储位置;如果两个Entry的key的hashCode()返回值相同,那它们的存储位置相同。如果这两个Entry的key通过equals比较返回true,新添加Entry的value将覆盖集合中原有Entry的value,但key不会覆盖。如果这两个Entry的key通过equals比较返回false,新添加的Entry将与集合中原有Entry形成Entry链,而且新添加的Entry位于Entry链的头部。
3 HashMap和HashTable,TreeMap的区别?
HashMap底层是数组加单项链表结构的,键是无序的不可重复的。允许Null键Null值。线程不同步,效率高
HashTable底层也是动态数组的数据结构。键是无序不可重复的。不允许Null键Null值。线程同步,效率低。
TreeMap底层是红黑树。自然排序,不能重复。
