常见的多模型融合算法
多模型融合算法可以比单一模型算法有极为明显的效果提升。但是怎样进行有效的融合,充分发挥各个算法的长处?这里总结一些常见的融合方法:
1. 线性加权融合法
线性加权是最简单易用的融合算法,工程实现非常方便,只需要汇总单一模型的结果,然后按不同算法赋予不同的权重,将多个推荐算法的结果进行加权,即可得到结果:
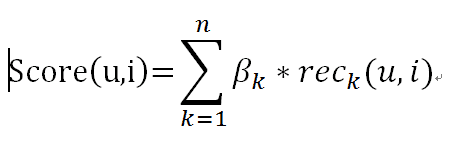
是给用户(user)推荐商品(item)的得分, 是算法K的权重,是算法k得到的用户(user)对商品item的推荐得分。这种融合方式实现简单,但效果较差。因为线性加权的参数是固定的,实践中参数的选取通常依赖对全局结果升降的总结,一旦设定后,无法灵活的按照不同的推荐场景来自动变换。比如如果某个场景用算法A效果较好,另外一种场景用算法B效果较好,线性融合的方式在这种情况下不能取得好的效果。为了解决这个问题,达观数据进行了改进,通过引入动态参数的机制,通过训练用户对推荐结果的评价、与系统的预测是否相符生成加权模型,动态的调整权重使得效果大幅提升。
2. 交叉融合法
交叉融合常被称为Blending方法,其思路是在推荐结果中,穿插不同推荐模型的结果,以确保结果的多样性。
这种方式将不同算法的结果组合在一起推荐给用户。
交叉融合法的思路是“各花入各眼”,不同算法的结果着眼点不同,能满足不同用户的需求,直接穿插在一起进行展示。这种融合方式适用于同时能够展示较多条结果的推荐场景,并且往往用于算法间区别较大,如分别基于用户长期兴趣和短期兴趣计算获得的结果。
3. 瀑布融合法
瀑布型(Waterfall Model)融合方法采用了将多个模型串联的方法。每个推荐算法被视为一个过滤器,通过将不同粒度的过滤器前后衔接的方法来进行:
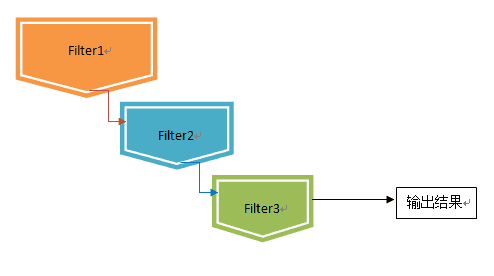
在瀑布型混合技术中,前一个推荐方法过滤的结果,将作为后一个推荐方法的候选集合输入,层层递进,候选结果在此过程中会被逐步遴选,最终得到一个量少质高的结果集合。这样设计通常用于存在大量候选集合的推荐场景上。
设计瀑布型混合系统中,通常会将运算速度快、区分度低的算法排在前列,逐步过渡为重量级的算法,让宝贵的运算资源集中在少量较高候选结果的运算上。在面对候选推荐对象(Item)数量庞大,而可曝光的推荐结果较少,要求精度较高、且运算时间有限的场景下,往往非常适用。
4. 特征融合法
不同的原始数据质量,对推荐计算的结果有很大的影响。以用户兴趣模型为例,我们既可以从用户的实际购买行为中,挖掘出用户的“显式”兴趣,又可以用用户的点击行为中,挖掘用户“隐式”兴趣;另外从用户分类、人口统计学分析中,也可以推测用户偏好;如果有用户的社交网络,那么也可以了解周围用户对该用户兴趣的影响。
所以通过使用不同的数据来源,抽取不同的特征,输入到推荐模型中进行训练,然后将结果合并。这种思路能解决现实中经常遇到的数据缺失的问题,因为并非所有用户都有齐全的各类数据,例如有些用户就缺少交易信息,有些则没有社交关系数据等。通过特征融合的方法能确保模型不挑食,扩大适用面。
5.预测融合法
推荐算法也可以被视为一种“预测算法”,即我们为每个用户来预测他接下来最有可能喜欢的商品。而预测融合法的思想是,我们可以对每个预测算法再进行一次预测,即不同的算法的预测结果,我们可以训练第二层的预测算法去再次进行预测,并生成最终的预测结果。
如下图所示,我们把各个推荐算法的预测结果作为特征,将用户对商品的反馈数据作为训练样本,形成了第二层预测模型的训练集合,具体流程如下
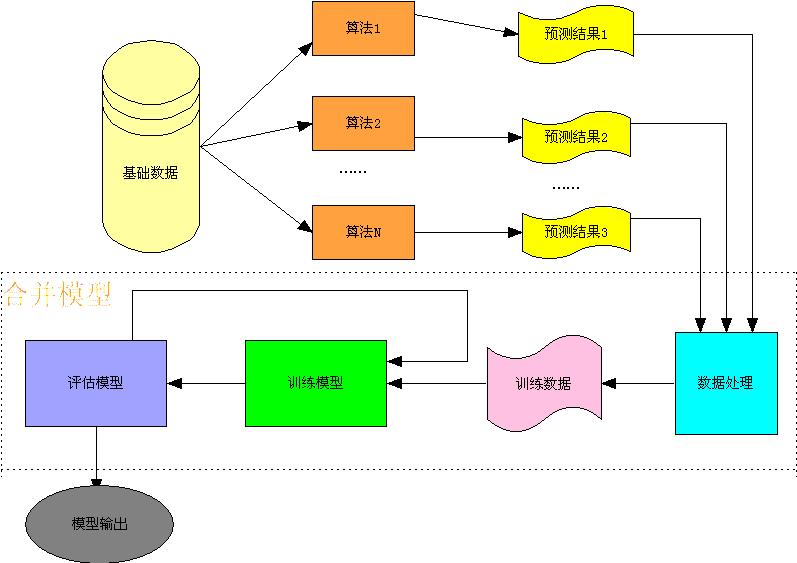
图中的二层预测模型可以使用常用的分类算法,如SVM、随机森林、较大熵等,但达观实践中,融合效果较好的是GBDT(Gradient Boosting Decision Tree)方法。
6.分类器Boosting思想
推荐问题有时也可以转化为模式分类(Pattern Classification)问题去看待,我们将候选集合是否值得推荐划分为几个不同的集合,然后通过设计分类器的方法去解决。
这样一来我们就可以用到分类算法中的Boosting思想,即将若干个弱分类器,组合成一个强分类器的方法。Boosting的核心思想是每轮训练后对预测错误的样本赋以较大的权重,加入后续训练集合,也就是让学习算法在后续的训练集中对较难的判例进行强化学习,从而得到一个带权重的预测函数序列h,预测效果好的预测函数权重较大,反之较小。
最终的预测函数H对分类问题采用有权重的投票方式,对回归问题采用加权平均的方法对新示例进行判别。算法的流程如下:(参考自treeBoost论文)

通过模型进行融合往往效果较好,但实现代价和计算开销也比较大。