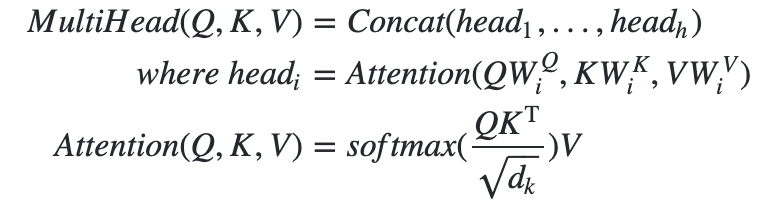一、数据源
InMemoryDataset,QueueDataset
加载数据并在训练前缓冲数据。此类由DatasetFactory创建。


import paddle.fluid as fluid dataset = fluid.DatasetFactory().create_dataset("InMemoryDataset") filelist = ["a.txt", "b.txt"] dataset.set_filelist(filelist) dataset.load_into_memory()
PyReader
在python中为数据输入创建一个reader对象。将使用python线程预取数据,并将其异步插入队列。当调用Executor.run时,将自动提取队列中的数据。
feed_list (list(Variable)|tuple(Variable)) - feed变量列表,由 fluid.layers.data() 创建。
capacity (int) - PyReader对象内部维护队列的容量大小。单位是batch数量。若reader读取速度较快,建议设置较大的capacity值。
use_double_buffer (bool) - 是否使用 double_buffer_reader 。若use_double_buffer=True,PyReader会异步地预读取下一个batch的数据,可加速数据读取过程,但同时会占用少量的CPU/GPU存储,即一个batch输入数据的存储空间。
iterable (bool) - 所创建的DataLoader对象是否可迭代。
return_list (bool) - 每个设备上的数据是否以list形式返回。仅在iterable = True模式下有效。若return_list = False,每个设备上的返回数据均是str -> LoDTensor的映射表,其中映射表的key是每个输入变量的名称。若return_list = True,则每个设备上的返回数据均是list(LoDTensor)。推荐在静态图模式下使用return_list = False,在动态图模式下使用return_list = True。
import paddle import paddle.fluid as fluid import numpy as np BATCH_SIZE = 10 def generator(): for i in range(5): yield np.random.uniform(low=0, high=255, size=[784, 784]), image = fluid.layers.data(name='image', shape=[784, 784], dtype='float32') reader = fluid.io.PyReader(feed_list=[image], capacity=4, iterable=False) reader.decorate_sample_list_generator( paddle.batch(generator, batch_size=BATCH_SIZE)) executor = fluid.Executor(fluid.CPUPlace()) executor.run(fluid.default_startup_program()) for i in range(3): reader.start() while True: try: executor.run(feed=None) except fluid.core.EOFException: reader.reset() break
数据加载通过paddle.fluid.io下的buffered,cache,chain用于批量导入数据
paddle.fluid.io下的first,map_readers,xmap_readers 用于变换数据。
二、神经网络参数
fluid.ParamAttr初始化神经网络的一个参数
BilinearInitializer:该接口为参数初始化函数,用于转置卷积函数中,对输入进行上采样。用户通过任意整型因子放大shape为(B,C,H,W)的特征图。
ConstantInitializer:该接口为常量初始化函数,用于权重初始化,通过输入的value值初始化输入变量;
force_init_on_cpu:
init_on_cpu
NormalInitializer:随机正态(高斯)分布初始化函数
NumpyArrayInitializer:该OP使用Numpy型数组来初始化参数变量。
UniformInitializer随机均匀分布初始化器
XavierInitializer
import paddle.fluid as fluid import math factor = 2 C = 2 H = W = 32 w_attr = fluid.ParamAttr( learning_rate=0., regularizer=fluid.regularizer.L2Decay(0.), initializer=fluid.initializer.BilinearInitializer()) x = fluid.layers.data(name="data", shape=[4, H, W], dtype="float32") conv_up = fluid.layers.conv2d_transpose( input=x, num_filters=C, output_size=None, filter_size=2 * factor - factor % 2, padding=int(math.ceil((factor - 1) / 2.)), stride=factor, groups=C, param_attr=w_attr, bias_attr=False)
三、作用域
paddle.fluid.executor.scope_guard(scope)
该接口通过 python 的 with 语句切换作用域(scope)。 作用域记录了变量名和变量 ( Variable ) 之间的映射关系,类似于编程语言中的大括号。 如果未调用此接口,所有的变量和变量名都会被记录在默认的全局作用域中。 当用户需要创建同名的变量时,如果不希望同名的变量映射关系被覆盖,则需要通过该接口切换作用域。 通过 with 语句切换后,with 语句块中所有创建的变量都将分配给新的作用域。
global_scope:获取全局/默认作用域实例。很多API使用默认 global_scope
import paddle.fluid as fluid import numpy new_scope = fluid.Scope() with fluid.scope_guard(new_scope): fluid.global_scope().var("data").get_tensor().set(numpy.ones((1, 2)), fluid.CPUPlace()) data = numpy.array(new_scope.find_var("data").get_tensor()) print(data)
四、动态图机制
PaddlePaddle的DyGraph模式是一种动态的图执行机制,可以立即执行结果,无需构建整个图。同时,和以往静态的执行计算图不同,DyGraph模式下您的所有操作可以立即获得执行结果,而不必等待所构建的计算图全部执行完成,这样可以让您更加直观地构建PaddlePaddle下的深度学习任务,以及进行模型的调试,同时还减少了大量用于构建静态计算图的代码,使得您编写、调试网络的过程变得更加便捷。
PaddlePaddle DyGraph是一个更加灵活易用的模式,可提供:
更加灵活便捷的代码组织结构:使用python的执行控制流程和面向对象的模型设计
更加便捷的调试功能:直接使用python的打印方法即时打印所需要的结果,从而检查正在运行的模型结果便于测试更改
和静态执行图通用的模型代码:同样的模型代码可以使用更加便捷的DyGraph调试,执行,同时也支持使用原有的静态图模式执行
fluid.dygraph下包括
Conv2D,Conv3D,Conv2DTranspose,Conv3DTranspose,FC,Pool2D
load_dygraph,save_graph
Layer对象用于存储一个动态图层
import paddle.fluid as fluid import numpy as np with fluid.dygraph.guard(): value = np.arange(26).reshape(2, 13).astype("float32") a = fluid.dygraph.to_variable(value) linear = fluid.Linear(13, 5, dtype="float32") adam = fluid.optimizer.Adam(learning_rate=0.01, parameter_list=linear.parameters()) out = linear(a) out.backward() adam.minimize(out) linear.clear_gradients() import paddle.fluid as fluid with fluid.dygraph.guard(): emb = fluid.dygraph.Embedding([10, 10]) state_dict = emb.state_dict() fluid.save_dygraph(state_dict, "paddle_dy")
create_parameter,full_name,sublayers,named_parameters,add_sublayer
五、模型
glu
门控线性单元 Gated Linear Units (GLU) 由 split ,sigmoid 和 elementwise_mul 组成。特定的,沿着给定维度将输入拆分成两个大小相同的部分,aa 和 bb ,按如下方式计算:
scaled_dot_product_attention
该接口实现了的基于点积(并进行了缩放)的多头注意力(Multi-Head Attention)机制。attention可以表述为将一个查询(query)和一组键值对(key-value pair)映射为一个输出;Multi-Head Attention则是使用多路进行attention,而且对attention的输入进行了线性变换。公式如下: