20200119 什么问题
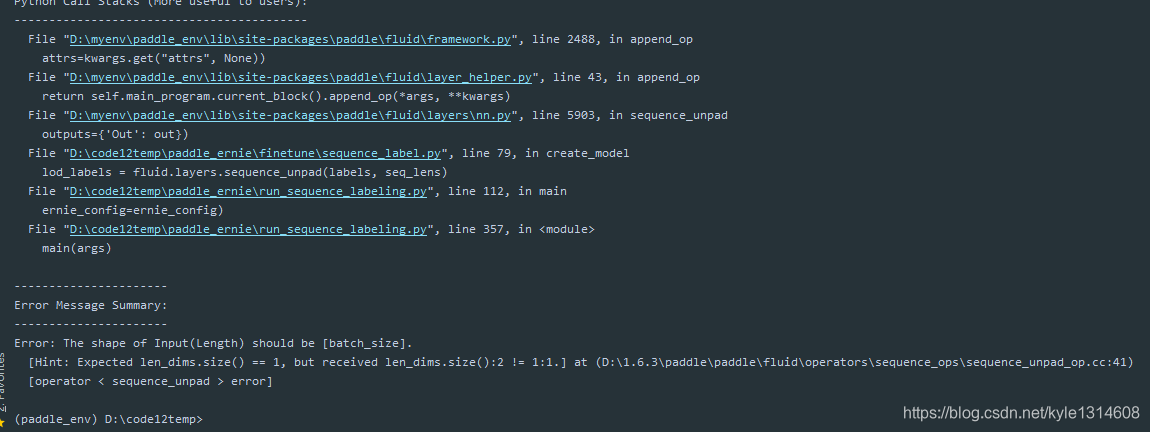
换成1.5版本
-1 表示大小不固定?
序列标注任务 tiny快4倍 ernie
这个跟框架没关系 paddle也有很多支持重训的:https://github.com/PaddlePaddle/models
PaddleHub-金宣-百度 2020/1/15 15:37:02
tiny的开源计划还需在群里问下ernie运营 我不是太清楚
15:37:56
劲风的味道 2020/1/15 15:37:56
pytorch 我试过是可以的 修改的
15:42:00
PaddleHub-金宣-百度 2020/1/15 15:42:00
可以试下https://github.com/PaddlePaddle/ERNIE ,也是可以修改的
劲风的味道 2020/1/15 15:42:47
好的 谢谢
PaddleHub-金宣-百度 2020/1/15 15:43:28
客气~
paddle 的安装是 paddlepaddle
docstrings:文档注释
gen:生成器
Profling 指发现性能瓶颈。系统中的瓶颈可能和程序员开发过程中想象的瓶颈相去甚远。Tuning 指消除瓶颈。性能优化的过程通常是不断重复地 profiling 和 tuning。
模型存储和预测
当特征数量达到千亿的时候,参数量很大,单机已经无法存下,所以模型的存储和加载都和普通模式不同:
普通模式下,参数是在trainer端保存和加载的;
分布式模式下,参数的保存和加载,都是在pserver端进行,每个pserver只保存和加载该pserver自身对应部分的参数
prefetch:预先载入
异步训练和 同步训练 的主要差异在于:异步训练每个trainer的梯度是单独更新到参数上的, 而同步训练是所有trainer的梯度合并之后统一更新到参数上,因此,同步训练和异步训练的超参数需要分别调节。
enable_dc_asgd : 是否开启 DC-ASGD 此选项在异步训练中生效,启用异步训练补偿算法
slice_var_up : 配置是否切分一个参数到多个pserver上进行优化,默认开启。此选项适用于模型参数个数少,但需要使用大量节点的场景,有利于提升pserver端计算并行度
learning_rate (float) - 参数的学习率。实际参数的学习率等于全局学习率乘以参数的学习率,再乘以learning rate schedule的系数。
share_vars_from (CompiledProgram) - 如果设置了share_vars_from,当前的CompiledProgram将与share_vars_from指定的CompiledProgram共享参数值 从某个位置共享参数 比如测试阶段从训练模型里面获取共享参数
num_iteration_per_drop_scope:该选项表示间隔多少次迭代之后清理一次临时变量
fuse:融合 a 和 b
ParallelExecutor 允许你修改执行器的相关参数,例如线程池的规模( num_threads ) 一个cpu核心一个线程
AllReduce 模式下, ParallelExecutor 调用AllReduce操作使多个节点上参数梯度完全相等,然后各个节点独立进行参数的更新;
allreduce:所有节点
Reduce 模式下, ParallelExecutor 会预先将所有参数的更新分派到不同的节点上,在执行过程中 ParallelExecutor 调用Reduce操作将参数梯度在预先指定的节点上进行聚合,并进行参数更新,最后调用Broadcast操作将更新后的参数发送到其他节点。
reduce 专有节点
通过设置 CUDA_VISIBLE_DEVICES 环境变量来指定执行器可使用的 GPU
序列标注任务中,token的分组称为语块(chunk)
AUC: Area Under Curve 曲线下面积
正确率:分母为实际的值
召回率:分母为预测为真的值
召回真值:预测真值 预测为正确的值?
Fluid 使用 fill_constant 创建一个具有特定形状和类型的 Tensor。可以通过 value 设置该变量的初始值
Fluid 使用 fill_constant_batch_size_like 创建一个具有特定形状、类型和 batch_size 的 Tensor
cast:转换数据类型
Tensor ,ndarray 就是多维数组
decorate:布置,放置
https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/fluid_cn/DataFeeder_cn.html#cn-api-fluid-datafeeder
数据并行处理重点
线性学习率热身(warm up)对学习率进行初步调整。在正常调整学习率之前,先逐步增大学习率 热身的意思
Layer-wise :按层,分层
Scaling:缩放
piecewise_decay:分段衰减
稀疏更新:即梯度以sparse tensor 结构存储,只保存梯度不为0的行。
reduce 按维度进行处理
# 在Paddle Fluid中我们会通过同样的变量名来共享权重.
# 训练和测试程序的所有参数将会拥有同样的名字,这将会使训练和测试程序实现参数的共享,
# 所以我们使用训练程序的 startup_program .并且由于测试的 startup_program 什么也没有,
# 因此它是一个新的程序.
https://www.paddlepaddle.org.cn/documentation/docs/zh/api_guides/low_level/parallel_executor.html#api-guide-parallel-executor
数据并行API
PaddlePaddle 中使用的 Tensor 为 LoD-Tensor(Level-of-Detail Tensor)。它是 Fluid 中特有的概念,在普通 Tensor 的基础上附加了序列信息。Fluid中可传输的数据包括:输入、输出、网络中的可学习参数,全部统一使用 LoD-Tensor 表示。


从上复制到下面就可以了
https://aistudio.baidu.com/aistudio/index
百度开源项目地址
我们测试过 tiny是会快很多的
建议use_pyreader、use_data_parallel、use_gpu都设置为True
速度
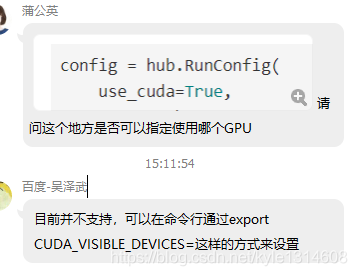
设置指定gpu
aistudio 里面数据 在启动在线环境后可以看到
模型进阶:如何序列标注任务中加入CRF层?
目前序列标注任务的finetune代码中,以softmax ce作为损失函数,该损失函数较为简单,没有考虑到序列中词与词之间的联系,如何加入 CRF 层让模型变得更强大呢?
