2017-Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network(SRGAN/SRResNet)
基本信息
作者: Christian Ledig, Lucas Theis, Ferenc Husz´ar, Jose Caballero, Andrew Cunningham,
Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, Wenzhe Shi
Twitter
期刊: CVPR
引用: *
摘要: 尽管使用更快、更深的卷积神经网络在单幅图像的超分辨率方面取得了突破性的进展,但有一个核心问题在很大程度上仍未得到解决:当我们在大比例尺下进行超分辨率时,如何恢复更精细的纹理细节?基于优化的超级分辨率方法的行为主要是由目标函数的选择所驱动。最近的工作主要集中在最小化平均平方重建误差上。由此产生的估计值具有较高的峰值信噪比,但它们往往缺乏高频细节,并且在感知上不令人满意,因为它们无法与更高的分辨率下的预期保真度相匹配。在本文中,我们提出了SRGAN,一个用于图像超分辨率(SR)的生成对抗网络(GAN)。据我们所知,它是第一个能够推断出4个放大系数的照片般真实的自然图像的框架。为了实现这一目标,我们提出了一个由对抗性损失和内容损失组成的知觉损失函数。对抗性损失将我们的解决方案推向自然图像流形,使用一个判别器网络,该网络被训练来区分超分辨率图像和原始照片写实图像。此外,我们还使用了一个以感知相似性为动机的内容损失,而不是像素空间的相似性。我们的深度残差网络能够在公共基准上从严重降采样的图像中恢复照片般真实的纹理。一个广泛的平均意见分数(MOS)测试显示,使用SRGAN在感知质量上有巨大的提升。用SRGAN得到的MOS分数比用任何最先进的方法得到的分数都更接近原始的高分辨率图像的分数。
1.简介
- 现阶段SR的问题:
SR的不是适定性导致SR图像缺乏纹理细节,有监督的SR算法的优化目标通常是最小化恢复的HR图像和地面真实之间的平均平方误差(MSE)。这很方便,因为最小化MSE也能使峰值信噪比(PSNR)最大化,而峰值信噪比是用来评估和比较SR算法的一个常用指标。然而,MSE(和PSNR)捕捉感知上相关差异的能力是非常有限的,比如高纹理细节,因为它们是基于像素级的图像差异来定义的。最高的PSNR并不一定反映出感知上更好的SR结果。 - 本文的工作:
提出了一个超级分辨率生成式对抗网络(SRGAN),为此我们采用了一个具有跳过连接的深度残差网络(ResNet),并将MSE作为唯一的优化目标。与以前的工作不同,我们使用VGG网络的高级特征图结合一个判别器来定义一个新的感知损失,鼓励从感知上难以与HR参考图像区分的解决方案。
1.1.相关工作
- 超分辨重建:介绍了SISR从传统算法到深度学习算法的发展历程及代表性作品
- 卷积神经网络的设计:越深的网络效果可能越好,但是训练比较困难,对此BN可以帮助有效训练更深的网络。残差块和跳连接也促进了超分辨的发展。此外上采样策略也是一个比较重要的网络设计方向。
- 损失函数:MSE 等像素损失难以处理恢复丢失的高频细节(如纹理)所固有的不确定性:最小化MSE鼓励寻找可信的解决方案的像素平均数,这些解决方案通常过于光滑,因此具有较差的感知质量。GAN网络、VGG特征损失等技术被提出用于解决该问题。
1.2.本文贡献
- 用16块深度ResNet(SRResNet)对MSE进行了优化,以PSNR和结构相似性(SSIM)衡量,起到了很好的结果
- 提出SRGAN,用感知损失而优化。用VGG网络的特征图计算的损失取代了基于MSE的内容损失,它对像素空间的变化更不敏感
- 通过对三个公共基准数据集的图像进行广泛的平均意见得分(MOS)测试,确认SRGAN在估计具有高放大系数(4)的照片般逼真的SR图像方面,以很大的优势成为最新的技术水平。
2.本文提出的方法
2.1.对抗网络框架
大致思路:允许人们训练一个生成模型G,目的是骗过一个可区分的鉴别器D,该鉴别器被训练用来区分超解图像和真实图像。通过这种方法,我们的生成器可以学习创造出与真实图像高度相似的解决方案,从而难以被D分类。这就鼓励了居住在自然图像的子空间,即流形中的感知上的优越解决方案。这与通过最小化像素误差测量(如MSE)获得的SR解决方案形成鲜明对比
min θ G max θ D E I H R ∼ p train ( I H R ) [ log D θ D ( I H R ) ] + E I L R ∼ p G ( I L R ) [ log ( 1 − D θ D ( G θ G ( I L R ) ) ] \begin{aligned} \min _{\theta_G} \max _{\theta_D} & \mathbb{E}_{I^{H R} \sim p_{\text {train }}\left(I^{H R}\right)}\left[\log D_{\theta_D}\left(I^{H R}\right)\right]+ \mathbb{E}_{I^{L R} \sim p_G\left(I^{L R}\right)}\left[\log \left(1-D_{\theta_D}\left(G_{\theta_G}\left(I^{L R}\right)\right)\right]\right. \end{aligned} θGminθDmaxEIHR∼ptrain (IHR)[logDθD(IHR)]+EILR∼pG(ILR)[log(1−DθD(GθG(ILR))]
以下是网络结构
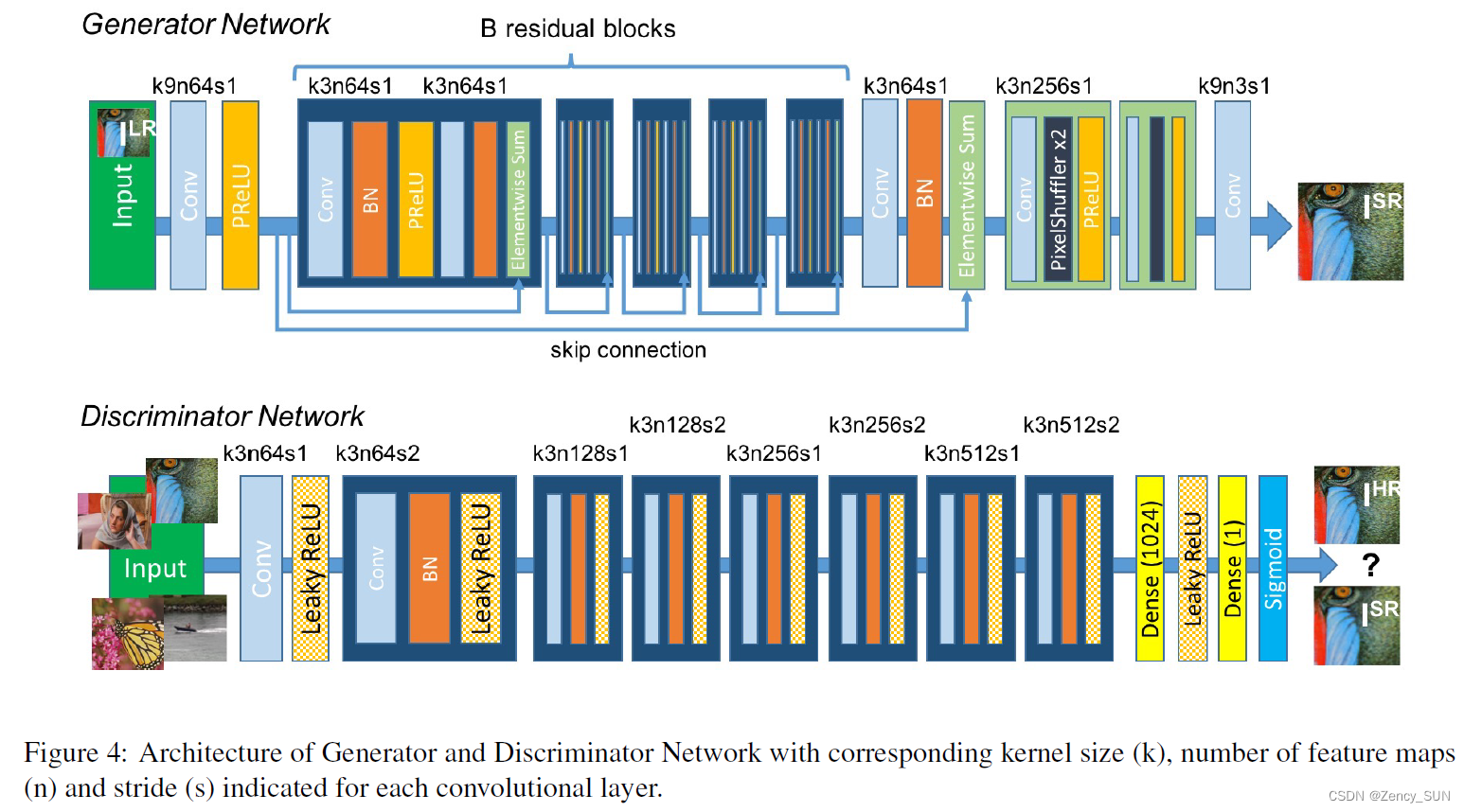
2.2.感知损失函数
本文定义感知损失为内容损失和对抗损失的加权
l S R = l X S R ⏟ content loss + 1 0 − 3 l G e n S R ⏟ adversarial loss ⏟ perceptual loss (for VGG based content losses) l^{S R}=\underbrace{\underbrace{l_{\mathrm{X}}^{S R}}_{\text {content loss }}+\underbrace{10^{-3} l_{G e n}^{S R}}_{\text {adversarial loss }}}_{\text {perceptual loss (for VGG based content losses) }} lSR=perceptual loss (for VGG based content losses)
content loss
lXSR+adversarial loss
10−3lGenSR
- 内容损失
本文没有使用MSE这类像素损失,而是使用更接近感知相似度的损失函数,使用Φij表示第i个池化层前的第j个卷积层,W,H分别表示特征图的宽高,内容损失表示为:
l V G G / i . j S R = 1 W i , j H i , j ∑ x = 1 W i , j ∑ y = 1 H i , j ( ϕ i , j ( I H R ) x , y − ϕ i , j ( G θ G ( I L R ) ) x , y ) 2 \begin{aligned} l_{V G G / i . j}^{S R}=\frac{1}{W_{i, j} H_{i, j}} & \sum_{x=1}^{W_{i, j}} \sum_{y=1}^{H_{i, j}}\left(\phi_{i, j}\left(I^{H R}\right)_{x, y}\right.\left.-\phi_{i, j}\left(G_{\theta_G}\left(I^{L R}\right)\right)_{x, y}\right)^2 \end{aligned} lVGG/i.jSR=Wi,jHi,j1x=1∑Wi,jy=1∑Hi,j(ϕi,j(IHR)x,y−ϕi,j(GθG(ILR))x,y)2 - 对抗损失
将GAN的生成成分添加到感知损失中,鼓励网络偏向于位于自然图像流形上的解决方案,试图欺骗鉴别器网络。对抗损失由判别器判别生成器生成的图像为HR的概率构成,如下:
l G e n S R = ∑ n = 1 N − log D θ D ( G θ G ( I L R ) ) l_{G e n}^{S R}=\sum_{n=1}^N-\log D_{\theta_D}\left(G_{\theta_G}\left(I^{L R}\right)\right) lGenSR=n=1∑N−logDθD(GθG(ILR))
3.实验
3.1.数据与预处理
本文在Set5,Set14,BSD100,BSD300数据集,均使用4倍超分辨实验(边缘减少16像素),PSNR均使用
通道计算(daala包,裁剪4像素),对比超分辨方法有NN,Bicubic,SRCNN,SelfExSR,DRCN等
3.2.训练细节和参数
训练接使用ImageNet(35W),训练集和验证集不同;对HR进行r=4进行双三次下采样得到LR。
每个Batch裁剪16个96x96子图像;LR的范围为[0,1],HR的范围为[-1,1],MSE的范围为[-1,1],VGG特征图也按照一定比例重新调整,从而获得与MSE相当的VGG损失。
使用MSE损失预训练的SRResNet作为生成网络,生成器和判别器交替更新参数,在测试时关闭BN模块。
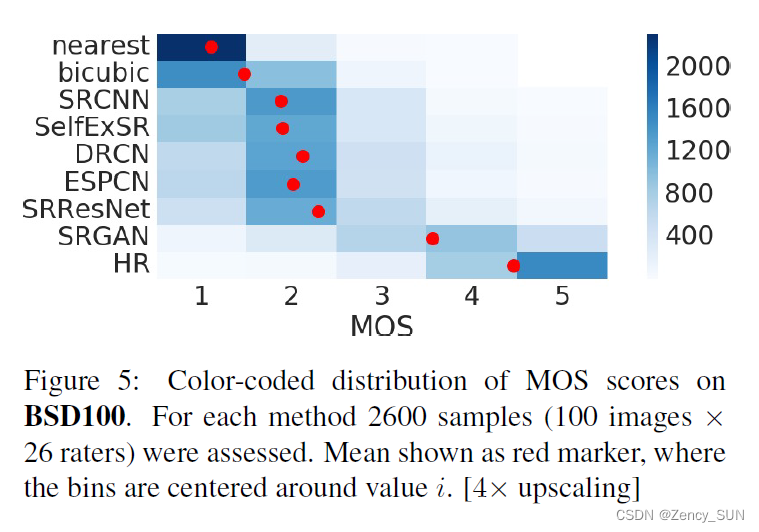
3.3.平均意见得分(MOS)测试
要求26位评分者对1000张照片进行评价(1-5分)
3.4.内容损失调查
使用以下三种损失作为内容损失进行调查:
- SRGAN-MSE:只使用MSE损失
- SRGAN-VGG22:使用VGG的Φ22作为底层特征的损失
- SRGAN-VGG54:使用VGG的Φ54作为高层特征的损失,该网络就是本文所谓的“SRGAN”
本文还评估了没有对抗成分的SRResNet-MSE(本文所谓的SRResNet),SRResNet-VGG22(添加TV损失)
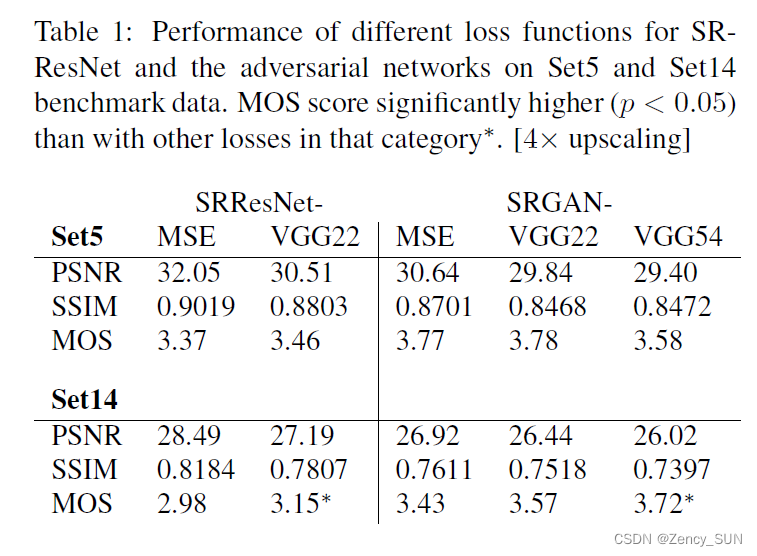
结论如下
- 即使与对抗性损失相结合,MSE也能提供具有最高PSNR值的解决方案,然而,与使用对视觉感知更敏感的损失成分所取得的结果相比,这些解决方案在感知上相当平滑,没有说服力。这是由基于MSE的内容损失和对抗性损失之间的竞争造成的。我们进一步将我们在少数基于SRGAN-MSE的重建中观察到的轻微重建伪影归因于这些竞争性目标。
- 使用更高级别的VGG特征图VGG54能产生更好的纹理细节
3.5.最终网络的性能
将最终的SRGAN、SRResNet和NN,Bicubic,SRCNN,SelfExSR,DRCN,ESPCN等SOTA算法比较。
(由于使用了一个统一的公开框架,所以获得的值有可能与原文有出入)
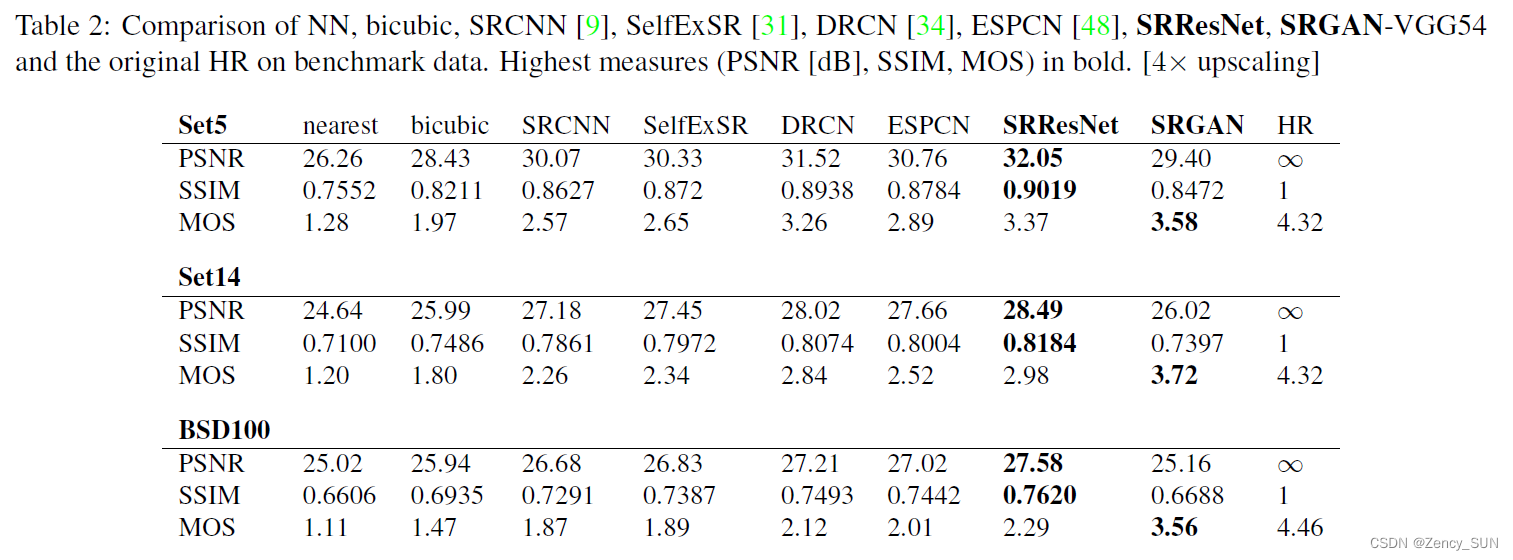
结论:SRResnet获得的PSNR达到了SOTA水平,SRGAN以很大的优势超过了所有的参考方法,并为逼真的图像SR设定了新的技术状态
4.讨论与未来工作
- 标准的定量测量方法(PSNR和SSIM)无法捕捉和准确评估人类视觉系统方面的图像质量。本文重点是超解图像的感知质量,而不是计算效率。
- 较浅的网络有可能在小幅降低质量性能的情况下提供非常有效的替代方案。更深的网络(B>16,详见附件)也能进一步提高SRResNet的性能,但是以更长的训练和测试时间为代价的。由于高频伪影的出现,更深的网络的SRGAN变体越来越难以训练。
- 若想在SR问题中旨在更真实地复原图像,特别重要的是对内容损失的选择。本文的SRGAN-VGG54产生了感知上最有说服力的结果,我们将其归因于更深的网络层有可能代表远离像素空间的更高抽象度的特征,这些更深层的特征图纯粹关注内容,而让对抗性损失关注纹理细节,这是没有对抗性损失的超解图像和照片现实图像之间的主要区别。
- 开发描述图像空间内容的内容损失函数,但对像素空间的变化更不敏感,这将进一步改善照片逼真的图像SR结果。
5.结论
- 本文设计了一个深度残差网络SRResNet,使用PSNR评价指标达到了SOTA效果。
- 本文强调了以PSNR为重点的图像超分辨率的一些局限性,并提出SRGAN,通过GAN网络最小化内容损失与对抗损失
- 通过MOS测试,本文的SRGAN在4倍放大的情况下占有巨大优势,更符合照片的真实性。
代码实现
本文未发布官方代码
个人总结
- SRResNet可以获得更高的PSNR值,但是视觉体验不如SRGAN;SRGAN的视觉体验更好,但是PSNR不高
- 使用MSE等像素损失可以获得更高的PSNR,使用对抗损失GAN/内容损失VGG可以获得更好的视觉与细节体验