爬网页一定会有验证码出现。
最幸运的情况就是遇到下面图片中这种情况
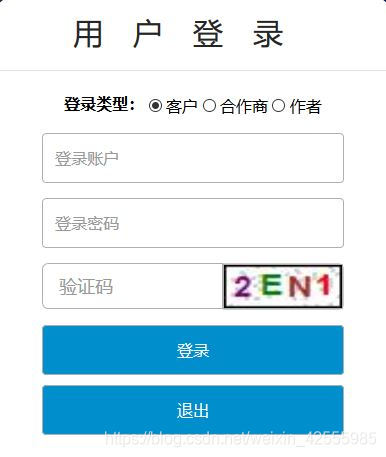
这种验证码式最最最最容易被识别的。
网上有介绍用pytesser来实现的,它是谷歌OCR开源项目。
我尝试了半天,不知道为什么就是不行。有兴趣的可以自行研究,界面如下
需要下载2个文件,自己百度吧,反正多年前的旧帖子很多都是用这种方法。
下面要说的是成功的方法。这种方法也是要利用Tesseract-OCR
我的环境64位Win10+py2.7
step1.安装PIL库
因为涉及图像识别,所以必须安装PIL(Python Imaging Library) 来进行图像处理
建议用下面的方法安装
pip install pillow
关于pillow介绍参见链接
step2.安装Tesseract-OCR
去这里下载https://github.com/UB-Mannheim/tesseract/wiki
我下载的是tesseract-ocr-w64-setup-v5.0.0-alpha.20191030.exe
默认安装就行
step3.配置
3-1.在计算机的环境变量path中追加你刚才安装tesseract-ocr的路径
如果正常,可以显示以下内容
C:\>tesseract -v
tesseract v5.0.0-alpha.20191030
leptonica-1.78.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0
Found AVX2
Found AVX
Found FMA
Found SSE
Found libarchive 3.3.2 zlib/1.2.11 liblzma/5.2.3 bz2lib/1.0.6 liblz4/1.7.5
3-2.在环境变量中追加一个环境变量TESSDATA_PREFIX,值就是你的Tesseract-OCR安装目录\tessdata。其实就是eng.traineddata这个文件所在目录
3-3.修改python安装目录Lib\site-packages\pytesseract中的pytesseract.py
这个文件中有下面这一行
tesseract_cmd = 'tesseract'
修改为
tesseract_cmd = 'C:/Program Files/Tesseract-OCR/tesseract.exe'
也就是tesseract.exe的所在目录。
注意:这里请用反斜杠,不然会出错。不信可以自己试一下。
step4.使用
我们来尝试一下下面这个验证码。

代码
#coding:utf-8
from PIL import Image,ImageEnhance
import pytesseract
im=Image.open("yzm.aspx.jfif")
image = im.convert('L')#图像加强,二值化
im2 =ImageEnhance.Contrast(image)#对比度增强
im3 = im2.enhance(2.0)
text = pytesseract.image_to_string(im3)
print text
yzm.aspx.jfif是网站上保存验证码图片的文件名称。
运行后结果
PFRD
补充
再换个网站的验证码试验一下(字符间隙不规则,字符是斜的)

结果6823,可以识别。
