1.Docker中镜像、容器和数据卷的概念
Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在构建之后也不会被改变。镜像并非是像一个 ISO 那样的打包文件,镜像只是一个虚拟的概念,其实际体现并非由一个文件组成,而是由一组文件系统组成,或者说,由多层文件系统联合组成。
Docker容器是一个开源的应用容器引擎,让开发者可以以统一的方式打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何安装了docker引擎的服务器上(包括流行的Linux机器、windows机器),也可以实现虚拟化。
Docker数据卷是用来解决数据持久化和数据共享的。它是一个可供一个或多个容器使用的特殊目录,多个容器可共享同一个Volume,实现数据共享,它绕过UFS,使得容器将数据直接存储到宿主机的硬盘上。
(下方答案太片面,可与上面答案结合)
容器(Containers):是独立运行的一个或一组应用,以及他们的运行态环境,是轻量级的,功能非常强悍,可读写,动态的。
镜像(Images):类似虚拟机中的快照,更轻量,只读,静态的。
数据卷(Data Volume):是一个可供一个或多个容器使用的特殊目录,多个容器可共享同一个Volume,实现数据共享。
2.大数据平台中将物理节点转化成虚拟节点的优缺点:
优点:解决物理节点维护繁琐的瓶颈,虚拟化具有备份、快照、双机热备等多种功能。
缺点:上述功能很多是以牺牲硬件性能为代价的。
3.分布式大数据与经典关系数据库的对比:
若图不够清晰,可私发

4.CDH的部署流程:(书P63)
第一步:Cloudera Manager安装
(1)下载CM安装包
(2)运行安装CM
第二步:添加服务
(1)添加Cloudera Management Service
(2)添加HDFS服务
(3)Zookeeper安装(对集群进行管理,如增添节点)
(4)YARN安装
(5)Hive安装
(6)Impala安装
(7)CDH状态一览
5.本课程大数据的三种定义(书P1)
(1)麦肯锡公司最早给出大数据定义:大数据是超过传统数据库工具的获取、存储、分析能力的数据集,并不是超过TB的才叫大数据。
(2)维基百科:大数据是指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集。
(3)本书编者:大数据是超过传统数据库工具、传统数据结构、传统程序设计语言、传统编程思想的获取、存储、分析能力的数据集。
6.大数据的四个V,并解释它们的含义:
Volume:数据容量巨大。大数据的起始计量单位至少是P、E、Z。
Velocity:处理速度快。
Variety:数据类型繁多。比如,网络日志、视频、图片、地理位置等。
Veracity:价值密度低,商业价值高。
7.大数据的三大核心技术,简要解释
(1)HDFS指被设计成适合运行在通用硬件上的分布式文件系统。HDFS是 一个高度容错性的系统,适合部署在廉价的机器上。
(2)MapReduce:处理海量数据的并行编程模型和计算框架。用于大规模数据集的并行运算。概念"Map"和"Reduce",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。
(3)HBase一个高可靠、高性能、面向列、可伸缩的分布式数据库,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
8.Docker,OpenStack,CDH,MapR,HDP等工具在大数据平台中的位置及作用,框架图。
Dokcer实现虚拟化,OpenStack、CDH、HDP,MapR是平台层,对集群进行管理和监控
Docker 可以让我们把一台物理机虚拟成多台来使用,在一台物理机上可以创建几百上千个容器,而虚拟机做不到。直接通过内核创建虚拟的操作系统实例,在其上进行平台搭建
openstack将硬件资源虚拟化出计算资源池,向上开放了一系列API,用于支持上层应用的开发,满足用户对计算资源的各种需求。
CDH提供了Hadoop的核心可扩展存储(HDFS)和分布式计算(MR),还提供了WEB页面进行管理、监控。
MapR是一款融合数据平台(Converged Data Platform),这种平台在同一个集群上支持数据流、交互式处理和批处理,实际上使Lambda架构扁平化。
(架构图是一张张照片,所写内容过多,可以适当放弃,如果想要可以私聊)
9.为什么需要HDFS?HDFS基本原理?节点类型和各自功能?
HDFS是hadoop分布式管理系统,它可以存储和管理PB级别以上数据,有大规模数据分布存储能力,有高并发访问能力,并通过构建廉价的机群实现文件的分发和存储,不仅增加存储的量而且增加了安全性。
HDFS的基本原理:用户把数据交给HDFS的Name结点,通过对文件的切分,然后Name接点把数据分发给各个数据接点进行存储和备份,实现把大量的数据进行存储和分发。
一个基本的Hadoop集群中的节点主要有
NameNode:负责协调集群中的数据存储.
DataNode:存储被拆分的数据块.
JobTracker:协调数据计算任务.
TaskTracker:负责执行由JobTracker指派的任务.
SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息
10.MapReduce编程模型,三个步骤,用WordCount举例。
三个步骤:Mapping,shuffle,Reducing

11.Spark和Hadoop的优缺点及各自应用场景。
Hadoop优点:(后4个是以前的考题答案)
1.处理超⼤⽂件:这⾥的超⼤⽂件通常指的是GB、 TB甚⾄PB⼤⼩
的⽂件。
2.运⾏于廉价的商⽤机器集群上: HDFS设计对硬件需求⽐较
低,只需运⾏在低廉的的商⽤机器集群上,⽽⽆须使⽤昂贵的⾼可⽤
机器。在设计HDFS时要充分考虑数据的可靠性、安全性和⾼可⽤性。
4.流式的访问数据
5.高可靠性。Hadoop具有按位存储和处理数据的能力。
6.高扩展性。Hadoop利用计算机集簇分配数据并完成计算任务,这些集簇可以扩展以千计的节点中。
7.高效性。Hadoop的处理速度非常快,这是因为他能够在节点之间动态地移动数据,让各个节点保证动态平衡。
8.高容错性。Hadoop是用来自动保存数据多个副本,而且将失败的任务自动进行重新分配,所以容错性在同类工具中绝对是出类拔萃的。
Hadoop缺点:
1.不适合低延迟数据访问:如果要处理⼀些⽤户要求时间⽐较短的低延迟应⽤请求(⽐如毫秒级、秒级的响应时间),则HDFS不适合。 HDFS是为了处理⼤型数据集⽽设计的,主要是为了达到⾼的数据吞吐量⽽设计的,延迟时间通常是在分钟乃⾄⼩时级别。
2.⽆法⾼效存储⼤量⼩⽂件
3.不⽀持多⽤户写⼊和随机⽂件修改:在HDFS的⼀个⽂件中只有⼀个写⼊者,⽽且写操作只能在⽂件末尾完成,即只能执⾏追加操作。
4.表达能力有限。计算都必须转换成Map和Reduce,并不适合所有情况,复杂数据难以处理
5.磁盘IO开销大。每次执行都需要从磁盘读取数据,计算完成后要将结果写会磁盘。
Haddop应用场景:
大数据量存储:分布式存储、日志处理、海量计算:并行计算
Spark主要具有如下优点:
1.Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活。
2.Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
3.Spark基于DAG ( Directed Acyclic Graph,有向无环图 )的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制
Spark应用场景:
同时支持批处理、交互式查询和流数据处理
二者的应用场景可结合下图再添加:

12.用Spark实现节点度统计,词频统计
实验指导书上有(自行打印)
13.使用Mahout进行K-means聚类分析
实验指导书上有(自行打印)
14.深度学习与机器学习,人工智能的关系
深度学习:由算法组成的机器学习子集,这些算法允许软件通过将多层神经网络暴露给大量数据来训练自己执行任务,如语音和图像识别。
机器学习:人工智能的一个子集,包括深奥的统计技术,使机器能够在有经验的任务中改进。这一类包括深度学习。
人工智能:任何使计算机能够模仿人类智能的技术,使用逻辑、if-then规则、决策树和机器学习(包括深度学习)。
***人工智能包含了机器学习,而机器学习包含了深度学习。也可以说是机器学习包含了深度学习,两者的组成应用到人工智能中。
(上边的想抄就抄吧,自行安排。自己提取名字写,存在包含关系)

15.深度学习训练的策略(三步走),训练中如何衡量训练结果(损失函数的原理),如何调整权值(梯度下降)
深度学习训练的策略:
(1) 随机选择一些初始参数,构建一个匹配函数
(2)检查所选参数是否足够好,(用拟合函数F(X)进行判断是否足够精确)
(3)优化参数,使函数更准确。
损失函数的原理:通过构建一个损失函数
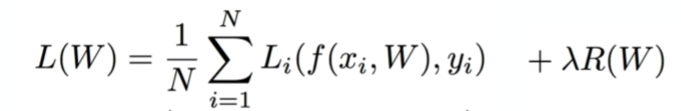
度量模型预测的好坏,用来估量模型的预测值f(x)与真实值Y的不一致程度。如果损失函数的值越小我们就说它的拟合程度就越好;相反,越大,拟合程度越差。
如何调整权值:采用梯度下降的方法,通过构建函数
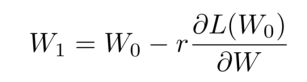
通过对拟合函数L(x)求一阶偏导判定来调整它的权值,使W达到最小。
