1.Range Loss for Deep Face Recognition with Long-Tailed Training Data,ICCV 2017,商汤科技
论文链接
1. 概要:
长尾分布,举个例子说就是80%的财富掌握在20%的手里,尾巴的部分虽然掌握财富较少,但胜在数量多,对模型训练有很大的影响,而现有的做法大多是简单裁剪尾巴,只保留样本数量充足的类别。
本文的贡献:
- 研究长尾分布对人脸 CNNs 模型训练的影响,并想办法缓解
- 开发出新loss —— Range loss(宗旨仍然是减小类内距离,增大类间距离)
- 使用数据集LFW(Labeled Faces in theWild)、YTF(YouTube Faces)证明了损失函数克服长尾分布的有效性
2.方法
2.2 问题的表述
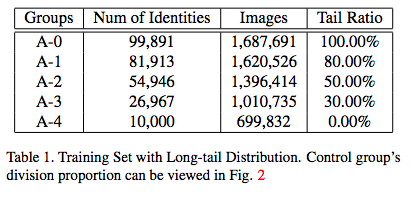
1.训练。首先从MS-Celeb-1M中构建了一个长尾分布训练集,包含了10w个身份,170w张图片,定义小于20张图片的身份为“尾巴”。按尾部的比例,分成了5组:

2.验证。使用LFW、YTF数据集来验证,使用VGG16+softmax loss
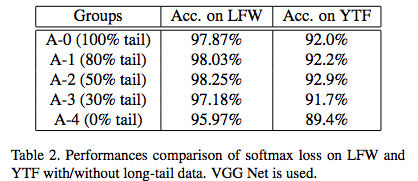
实验证明,在大规模数据集和深层网络中,50% tail数据取得了更高的准确率
3.以上实验表现得好,可能是因为我们使用深层的网络和大的数据集,如果使用更浅的网络和较小的数据集尾部的影响会有什么表现呢?
于是,我们使用AlexNet(8层)+softmax loss,并构建了新的数据集:先从A-0的10w个身份中随机抽取4k个身份作为B-0,因此B-0和A-0具有相似的分布,再从B-0的尾部数据中删除1k,2k,3k, 得到训练集B-1,B-2,B-3。

这次结果反过来,随着尾部数据的增大,反而验证准确率更低,这说明了长尾数据对浅层小训练集的负面影响明显。
2.2 探索使用 contrastive, triplet and center三种损失是否能缓解长尾分布的影响
1) contrastive loss

d表示两个样本特征的欧式距离,y为label。
y = 1,正例样本,最小化欧式距离,即最小化类内距离;
y = 0,负例样本,把欧式距离控制在阈值margin以内,即最大化类间距离。
2) triplet loss
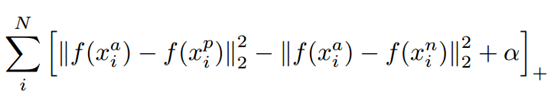

控制正例样本到anchor的距离比负例样本衡大出一个阈值α
通过学习,使得正例样本靠近anchor,负例样本远离anchor
3)center loss
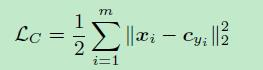
使同类的所有样本到类中心样本的距离越近越好,但是缺乏类间距离的优化。

可以观察到:
- 随着尾部数据的减少,准确率都有所下降;
- A-2,cut 50% tail,表现是最好的。
实验证明: 尽管这三种loss都比softmax loss的表现好,但是仍然受到长尾分布的影响,没有解决我们的问题。
2.3 深层特征向量分析
1)从测试集中随机选10个身份,每个身份选20张图像,使用VGG-Nets把每张图像映射到4096维特征,使用t-SNE降维。

t-SNE 通过仿射(affinitie)变换将数据点映射到概率分布上,主要包括两个步骤:
① SNE构建一个高维对象之间的概率分布,使得相似的对象有更高的概率被选择,而不相似的对象有较低的概率被选择。
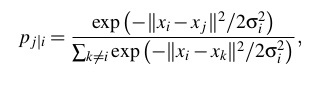
σi表示以高维数据点xi为中心的正态分布的方差。
② SNE在低维空间里在构建这些点的概率分布,使低维点yi、yj分别对应于高维点xi、yi,让这两个概率分布之间尽可能的相似。
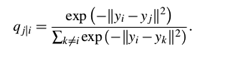
2)我们还要计算 standard deviation (SD), average Euclidean metric (EM) 和 2-D 特征向量的峰度(kurtosis)。
峰度反应的是图像的尖锐程度:峰度越大,表现在图像上面是中心点越尖锐,表明存在不常见的极端样本的程度,旨在优化类内距离。
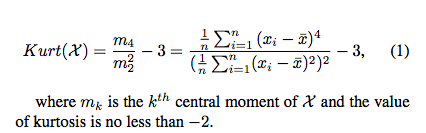

由此可见,Range loss的峰度很低了,对于优化类内距离,缓解长尾分布的影响是肯定有帮助。
SD和EM表示了样本的变化情况,旨在优化类间距离。
2.4 Range Loss 定义
受到对比损失的启发,对比损失是定义在单个样本对上,范围损失定义在小批量的样本对总体上。
具体来讲,对于类内距离,我们识别出类内对的K个最大的距离(range),并使用它们的调和平均值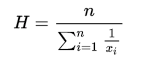 作为类内损失的度量,最终的range由最远的类内对决定;对于类间距离,最小化类中心的距离。
作为类内损失的度量,最终的range由最远的类内对决定;对于类间距离,最小化类中心的距离。
Range loss 总损失:
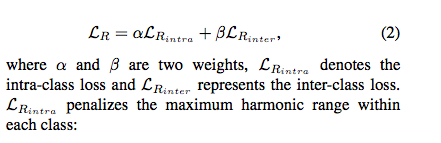
① 类内距离惩罚了最大的类内对的距离(range),I为身份类别数,K为同身份中前K个最大距离。
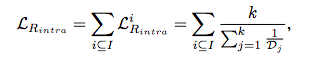
对K值的选取:
K=2表现得还不错,K=3只提升了0.03%的准确率,K=4或5表现得比前面糟糕,而且K越大计算量就越大,因此选择K=2。
② 类间距离,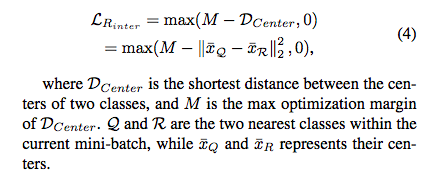
其中Q和R是当前小批量中最近的类
为了增大不同类别的判别能力,引入softmax loss作为监督信号,所以最终损失为:
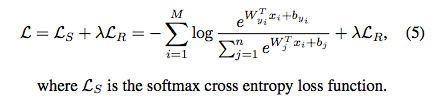
M是批量的身份类别,n是全部身份类别数。 xi是提取到的特征向量,W和b都是softmax的参数。
经过试验,λ = 1, α = 5 × 10−5 , β = 1 × 10−4
而且加入range loss,只需要额外的0.2422%的时间,成本可以接受。
M 取256,首先选择16个身份类别,并分别为其选择16张图像,批量类别计算损失而不是单独类别计算损失,原因是:确保模型优化方向相对平衡。

真实效果见 fig. 3 c
3.实验
1)

Table 6 可以看出range loss比其他loss的准确率高,而且用更多的长尾数据可以提升准确率(其它的都是在下降的)
2)

训练数据用 MS-Celeb-1M [6]和CASIA-WebFace 的1.5M过滤后的数据,此实验用更深的网络和更清洁的数据来检验使用range loss训练的模型的潜在能力和泛化性。

Table 7 证明了range loss的泛化能力可以。
虽然FaceNet性能更好,但它是在超大型数据集上训练的,规模是我们的133倍。