CVPR2017年的Best Paper, DenseNet脱离了加深网络层数(ResNet)和加宽网络结构(Inception)来提升网络性能的定式思维,从特征的角度考虑,通过特征重用和旁路(Bypass)设置,既大幅度减少了网络的参数量,又在一定程度上缓解了gradient vanishing问题的产生.结合信息流和特征复用的假设,DenseNet当之无愧成为2017年计算机视觉顶会的年度最佳论文.
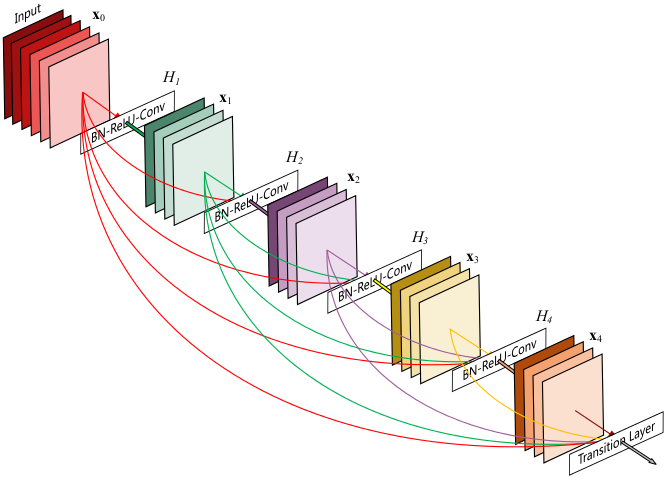
DenseNet
闪光点:
- 密集连接:缓解梯度消失问题,加强特征传播,鼓励特征复用,极大的减少了参数量
DenseNet 是一种具有密集连接的卷积神经网络。在该网络中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。由上图可知 在DenseNet 的一个dense block中一个block里面的结构如下,与ResNet中的BottleNeck基本一致:BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3) ,而一个DenseNet则由多个这种block组成。每个DenseBlock的之间层称为transition layers ,BN−>Conv(1×1)−>averagePooling(2×2)组成。
密集连接不会带来冗余吗?不会!密集连接这个词给人的第一感觉就是极大的增加了网络的参数量和计算量。但实际上 DenseNet 比其他网络效率更高,其关键就在于网络每层计算量的减少以及特征的重复利用。DenseNet则是让l层的输入直接影响到之后的所有层,它的输出为:xl=Hl([X0,X1,…,xl−1]),其中[x0,x1,...,xl−1]就是将之前的feature map以通道的维度进行合并。并且由于每一层都包含之前所有层的输出信息,因此其只需要很少的特征图就够了,这也是为什么DneseNet的参数量较其他模型大大减少的原因。这种dense connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题。
天底下没有免费的午餐,网络自然也不例外。在同层深度下获得更好的收敛率,自然是有额外代价的。其代价之一,就是其恐怖如斯的内存占用。
实现代码:github
参考链接:
