目标跟踪从两个维度来展开: 基于视觉的目标跟踪和基于多传感器融合的目标跟踪。
1. 基于视觉的目标跟踪
一般将目标跟踪分为两个部分:特征提取、目标跟踪算法。目标跟踪的算法大致可以分为以下五种:
- 均值漂移算法,即meanshift算法,此方法可以通过较少的迭代次数快速找到与目标最相似的位置,效果也挺好的。但是其不能解决目标的遮挡问题并且不能适应运动目标的的形状和大小变化等。对其改进的算法有camshift算法,此方法可以适应运动目标的大小形状的改变,具有较好的跟踪效果,但当背景色和目标颜色接近时,容易使目标的区域变大,最终有可能导致目标跟踪丢失。
- 基于Kalman滤波的目标跟踪,该方法是认为物体的运动模型服从高斯模型,来对目标的运动状态进行预测,然后通过与观察模型进行对比,根据误差来更新运动目标的状态,该算法的精度不是特高。
- 基于粒子滤波的目标跟踪,每次通过当前的跟踪结果重采样粒子的分布,然后根据粒子的分布对粒子进行扩散,再通过扩散的结果来重新观察目标的状态,最后归一化更新目标的状态。此算法的特点是跟踪速度特别快,而且能解决目标的部分遮挡问题,在实际工程应用过程中越来越多的被使用。
- 基于对运动目标建模的方法。该方法需要提前通过先验知识知道所跟踪的目标对象是什么,比如车辆、行人、人脸等。通过对要跟踪的目标进行建模,然后再利用该模型来进行实际的跟踪。该方法必须提前知道要跟踪的目标对象是什么,然后再去跟踪指定的目标,这是它的局限性,因而其推广性相对比较差。
- 因为深度特征对目标拥有强大的表示能力,深度学习在计算机视觉的其他领域,如:检测,人脸识别中已经展现出巨大的潜力。把在分类图像数据集上训练的卷积神经网络迁移到目标跟踪中来,基于深度学习的目标跟踪方法才得到充分的发展。
a. 基于对称网络的多目标跟踪算法
一种检测匹配度量学习方法是采用Siamese对称卷积网络,以两个尺寸相同的检测图像块作为输入,输出为这两个图像块是否属于同一个目标的判别。通常有三种拓扑形式的Siamese网络结构:

三种Siamese网络拓扑结构。第一种结构,输入A和B经过相同参数的网络分支,对提取的特征计算他们的距离度量作为代价函数,以使得相同对象的距离接近,而不同对象的距离变大。第二种结构,输入A和B经过部分相同参数的网络分支,对生成的特征进行合并,新的特征进行多层卷积滤波之后输入代价函数作为,第三种网络结构能够生成更好的判别结果。第三种拓扑形式的Siamese网络训练并计算两个检测的匹配相似度,原始的检测特征包括正则化的LUV图像I1和I2,以及具有x,y方向分量的光流图像O1和O2,把这些图像缩放到121x53,并且叠加到一起构成10个通道的网络输入特征。卷积网络由3个卷积层(Conv-Layer)、4个全连接层(FC-Layer)以及2元分类损失层(binary-softmax-loss)组成.损失函数为:
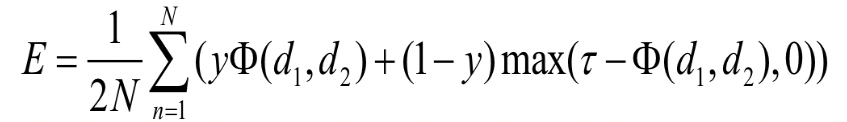
其中![]() 表示两个检测
表示两个检测![]() 和
和![]() ,经过卷积之后的输出特征。y表示是否对应相同目标,如果
,经过卷积之后的输出特征。y表示是否对应相同目标,如果![]() ,
,![]() 来自同一个目标的检测,y=1;否则y=0。
来自同一个目标的检测,y=1;否则y=0。
在Siamese网络学习完成之后,作者采用第六层全连接网络的输出作为表观特征,为了融合运动信息,作者又设计了6维运动上下文特征:尺寸相对变化,位置相对变化,以及速度相对变化。通过经典的梯度下降提升算法学习集成分类器。

多目标跟踪的过程采用全局最优算法框架,通过对每两个检测建立连接关系,生成匹配图,计算他们的匹配状态。通过最小代价网络流转化为线性规划进行求解。
b.基于最小多割图模型的多目标跟踪算法
上述算法中为了匹配两个检测采用LUV图像格式以及光流图像。Tang等人发现采用深度学习计算的类光流特征(DeepMatching),结合表示能力更强的模型也可以得到效果很好的多目标跟踪结果。通过观察目标跟踪问题中的检测结果,发现仅仅考虑两帧之间的检测匹配不是最佳的模型表示。由于存在很多检测不准确的情况,同时考虑图像之间以及图像内部的检测匹配关系,并建立相应的图模型比仅仅考滤帧间检测匹配的图模型具有更广泛的表示能力。

上图是三帧图像中的检测结果,为了建立更准确的匹配模型,除了建立两帧之间的匹配关系,还需要考虑同一幅图像内,是否存在同一个目标对应多个检测的情况。
下图是构造的帧间及帧内连接图模型。类似于最小代价流模型求解多目标跟踪算法,这种考虑了帧内匹配的图模型可以模型化为图的最小多割问题,如下公式所示:

上式中![]() 表示每个边的代价,这里用检测之间的相似度计算。x=0表示节点属于同一个目标,x=1反之。这个二元线性规划问题的约束条件表示,对于任何存在的环路,如果存在一个连接x=0,那么这个环上的其他路径都是x=0。即,对于优化结果中的0环路,他们都在同一个目标中。所以x=1表示了不同目标的分割,因此这个问题转化为了图的最小多割问题。对于最小代价多割问题的求解,可以采用KLj算法进行求解。
表示每个边的代价,这里用检测之间的相似度计算。x=0表示节点属于同一个目标,x=1反之。这个二元线性规划问题的约束条件表示,对于任何存在的环路,如果存在一个连接x=0,那么这个环上的其他路径都是x=0。即,对于优化结果中的0环路,他们都在同一个目标中。所以x=1表示了不同目标的分割,因此这个问题转化为了图的最小多割问题。对于最小代价多割问题的求解,可以采用KLj算法进行求解。
现在的问题是如何计算帧内及帧间检测配对的匹配度量特征。作者采用了深度学习算法框架计算的光流特征(DeepMatching)作为匹配特征,采用DeepMatching方法计算的深度光流特征示例。

利用DeepMatching算法计算的深度光流特征,蓝色箭头表示匹配上的点对。
基于DeepMatching特征,可以构造下列5维特征:

其中MI,MU表示检测矩形框中匹配的点的交集大小以及并集大小,ξv和ξw表示检测信任度。利用这5维特征可以学习一个逻辑回归分类器。并得到是相同目标的概率pe,从而计算代价函数:
为了连接长间隔的检测匹配,增强对遮挡的处理能力,同时避免表观形似但是不同目标检测之间的连接,Tang等人在最小代价多割图模型的基础上提出了基于提升边(lifted edges)的最小代价多割图模型。基本的思想是,扩展原来多割公式的约束条件,把图中节点的连接分为常规边和提升边,常规边记录短期匹配状态,提升边记录长期相似检测之间的匹配关系。除了原来公式中的约束,又增加了2个针对提升边的约束,即对于提升边是正确匹配的,应该有常规边上正确匹配的支持;对于提升边是割边的情况,也应该有常规边上连续的割边的支持。

(a)和(c)是传统的最小代价多割图模型。(b)和(d)是增加了提升边(绿色边)的最小多割图模型。通过增加提升边约束,图中(b)中的提升边可以被识别为割,而(d)中的边被识别为链接。
同样,为了计算边的匹配代价,需要设计匹配特征。这里,作者采用结合姿态对齐的叠加Siamese网络计算匹配相似度,采用的网络模型StackNetPose具有最好的重识别性能。

(a),(b),(c)分别为SiameseNet, StackNet, StackNetPose模型。(e)为这三种模型与ID-Net在行人重识别任务上对比。(d)为StackNetPose的结果示例。
综合StackNetPose网络匹配信任度、深度光流特征(deepMatching)和时空相关度,作者设计了新的匹配特征向量。类似于[2], 计算逻辑回归匹配概率。最终的跟踪结果取得了非常突出的进步。在MOT2016测试数据上的结果如下表:

基于提升边的最小代价多割算法在MOT2016测试数据集中的跟踪性能评测结果。
c. 通过时空域关注模型学习多目标跟踪算法
除了采用解决目标重识别问题的深度网络架构学习检测匹配特征,还可以根据多目标跟踪场景的特点,设计合适的深度网络模型来学习检测匹配特征。Chu等人对行人多目标跟踪问题中跟踪算法发生漂移进行统计分析,发现不同行人发生交互时,互相遮挡是跟踪算法产生漂移的重要原因。

当2个目标的运动发生交互的时候,被遮挡目标不能分辨正确匹配,导致跟踪漂移。
针对这个问题,提出了基于空间时间关注模型(STAM)用于学习遮挡情况,并判别可能出现的干扰目标。空间关注模型用于生成遮挡发生时的特征权重,当候选检测特征加权之后,通过分类器进行选择得到估计的目标跟踪结果,时间关注模型加权历史样本和当前样本,从而得到加权的损失函数,用于在线更新目标模型。

用于遮挡判别的STAM模型框架,采用空间注意模型加权检测结果的特征,通过历史样本、以及围绕当前跟踪结果采集的正、负样本,来在线更新目标模型。
在这个模型中每个目标独立管理并更新自己的空间时间关注模型以及特征模型,并选择候选检测进行跟踪,因此本质上,这种方法是对单目标跟踪算法在多目标跟踪中的扩展。为了区分不同的目标,关键的步骤是如何对遮挡状态进行建模和区分接近的不同目标。
这里空间注意模型用于对每个时刻的遮挡状态进行分析,空间关注模型如图12中下图所示。主要分为三个部分,第一步是学习特征可见图(visibility map):
这里 ![]() 是一个卷积层和全连接层的网络操作。
是一个卷积层和全连接层的网络操作。 ![]() 是需要学习的参数。第二步是根据特征可见图,计算空间关注图(Spatial Attention): 其中
是需要学习的参数。第二步是根据特征可见图,计算空间关注图(Spatial Attention): 其中 ![]() 是一个局部连接的卷积和打分操作。
是一个局部连接的卷积和打分操作。![]() 是学习到的参数。
是学习到的参数。

采用空间注意模型网络架构学习遮挡状态,并用于每个样本特征的加权和打分。
第三步根据空间注意图加权原特征图:![]()
对生成的加权特征图进行卷积和全连接网络操作,生成二元分类器判别是否是目标自身。最后用得到分类打分选择最优的跟踪结果。
d. 基于循环网络判别融合表观运动交互的多目标跟踪算法
上面介绍的算法采用的深度网络模型都是基于卷积网络结构,由于目标跟踪是通过历史轨迹信息来判断新的目标状态,因此,设计能够记忆历史信息并根据历史信息来学习匹配相似性度量的网络结构来增强多目标跟踪的性能也是比较可行的算法框架。
Sadeghian等人设计了基于长短期记忆循环网络模型(LSTM)的特征融合算法来学习轨迹历史信息与当前检测之间的匹配相似度。

轨迹目标与检测的匹配需要采用三种特征(表观特征、运动特征、交互特征)融合(左),为了融合三种特征采用分层的LSTM模型(中),最终匹配通过相似度的二部图匹配算法实现(右)。
考虑从三个方面特征计算轨迹历史信息与检测的匹配:表观特征,运动特征,以及交互模式特征。这三个方面的特征融合以分层方式计算。在底层的特征匹配计算中,三个特征都采用了长短期记忆模型(LSTM)。对于表观特征,首先采用VGG-16卷积网络生成500维的特征ϕtA,以这个特征作为LSTM的输入计算循环

基于CNN模型和LSTM模型的轨迹与检测表观特征匹配架构。
网络的输出特征ϕi,对于当前检测![]() ,计算同样维度的特征ϕj,连接这两个特征并通过全链接网络层计算500维特征ϕA,根据是否匹配学习分类器,并预训练这个网络。
,计算同样维度的特征ϕj,连接这两个特征并通过全链接网络层计算500维特征ϕA,根据是否匹配学习分类器,并预训练这个网络。
对于运动特征,取相对位移vit为基本输入特征,直接输入LSTM模型计算没时刻的输出ϕi,对于下一时刻的检测同样计算相对位移![]() ,通过全连接网络计算特征ϕj,类似于表观特征计算500维特征ϕM,并利用二元匹配分类器进行网络的预训练。
,通过全连接网络计算特征ϕj,类似于表观特征计算500维特征ϕM,并利用二元匹配分类器进行网络的预训练。

基于LSTM模型的轨迹运动特征匹配架构。
对于交互特征,取以目标中心位置周围矩形领域内其他目标所占的相对位置映射图作为LSTM模型的输入特征,计算输出特征ϕi,对于t+1时刻的检测计算类似的相对位置映射图为特征,通过全连接网络计算特征ϕj,类似于运动模型,通过全连接网络计算500维特征ϕI,进行同样的分类训练。

基于LSTM模型的目标交互特征匹配架构。
当三个特征ϕA,ϕM,ϕI都计算之后拼接为完整的特征,输入到上层的LSTM网络,对输出的向量进行全连接计算,然后用于匹配分类,匹配正确为1,否则为0。对于最后的网络结构,还需要进行微调,以优化整体网络性能。最后的分类打分看作为相似度用于检测与轨迹目标的匹配计算。最终的跟踪框架采用在线的检测与轨迹匹配方法进行计算。
e. 基于双线性长短期循环网络模型的多目标跟踪算法
在循环网络判别融合表观运动交互的多目标跟踪算法中,作者采用LSTM作为表观模型、运动模型以及交互模型的历史信息模型表示。在对LSTM中各个门函数的设计进行分析之后,Kim等人认为仅仅用基本的LSTM模型对于表观特征并不是最佳的方案,Kim等人设计了基于双线性LSTM的表观特征学习网络模型。
除了利用传统的LSTM进行匹配学习,或者类似[5]中的算法,拼接LSTM输出与输入特征,作者设计了基于乘法的双线性LSTM模型,利用LSTM的隐含层特征(记忆)信息与输入的乘积作为特征,进行匹配分类器的学习。

三种基于LSTM的匹配模型。(a)利用隐含层(记忆信息)与输入特征乘积作为分类特征。(b)直接拼接隐含层特征与输入特征作为新的特征进行分类学习。(c)使用传统LSTM模型的隐含层进行特征学习。这里对于隐含层特征ht-1,必须先进行重新排列(reshape)操作,然后才能乘以输入的特征向量xt,如下公式:
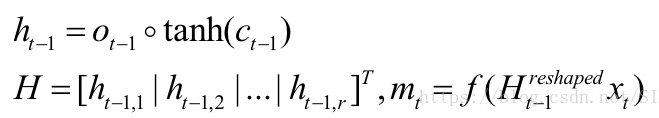
其中f表示非线性激活函数, ![]() 是新的特征输入。而原始的检测图像采用ResNet50提取2048维的特征,并通过全连接降为256维。下表中对于不同网络结构、网络特征维度、以及不同LSTM历史长度时,表观特征的学习对跟踪性能的影响做了验证。
是新的特征输入。而原始的检测图像采用ResNet50提取2048维的特征,并通过全连接降为256维。下表中对于不同网络结构、网络特征维度、以及不同LSTM历史长度时,表观特征的学习对跟踪性能的影响做了验证。
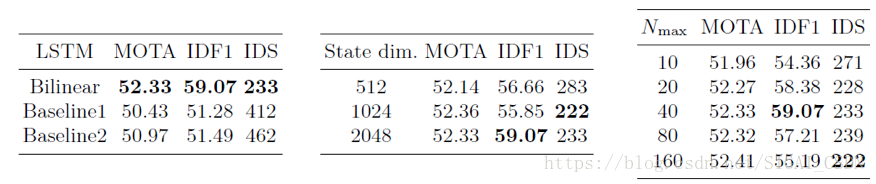
三种网络结构对跟踪性能的影响, Baseline1和Baseline2分别对应图17中的中间图结构和右图结构。(中)不同网络隐含层维度对性能的影响。(右)不同历史信息长度对跟踪性能的影响。
可以看出采用双线性LSTM(bilinear LSTM)的表观特征性能最好,此时的历史相关长度最佳为40,这个值远远超过2-4帧历史长度。相对来说40帧历史信息影响更接近人类的直觉。
作者通过对比递推最小二乘公式建模表观特征的结果,认为双线性LSTM模型对于表观模型的长期历史特征建模比简单的LSTM更具有可解释性,而对于运动特征,原始的LSTM特征表现的更好。综合双线性LSTM表观模型和LSTM运动模型,作者提出了新的基于MHT框架的跟踪算法MHT-bLSTM,得到的性能如下表:

表3:在MOT2017和MOT2016中多目标跟踪算法比较。在IDF1评测指标上,MHT-bLSTM的性能最佳。
