HDFS架构
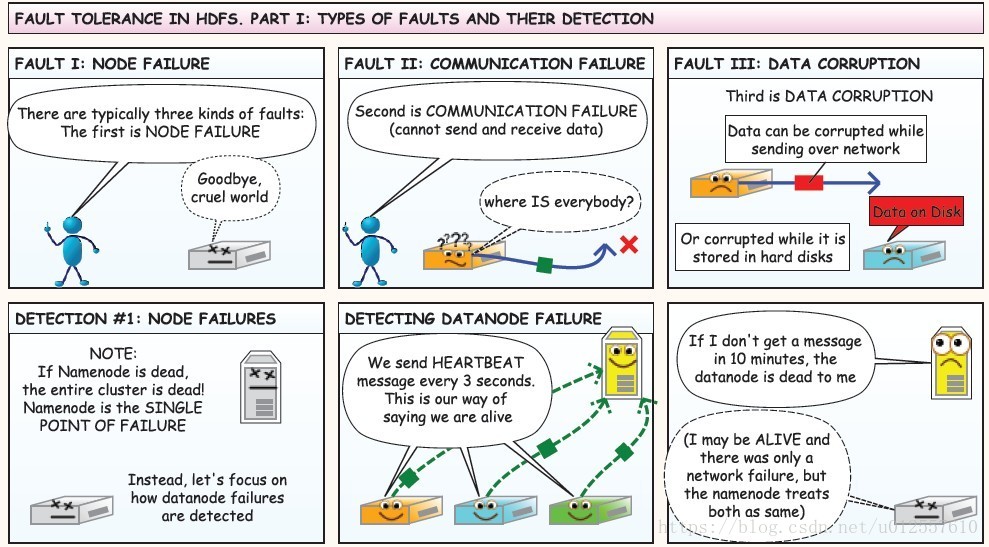
HDFS有两种节点,一种是NameNode,另一种是DataNode
NameNode (NN)
1.负责客户端请求的接收和相应
2.负责存储元数据,所谓元数据就是一些文件的名称,BlockId,Block所在的DataNode等信息DataNode(DN)
1.真正存储数据的地方,存储的是数据块,数据块的大小可以通过BlockSize来指定
2.定期向NN发送心跳信息,汇报block信息数据节点的健康状况等
通常情况下在一个集群中,会有一个Master节点,这个Master节点充当的就是NameNode,还会有多个Slaves,充当DataNode
一个文件会被拆成多个数据块,每个块的大小由blocksize来指定,默认情况下,blocksize是128M,也就说一个130M的文件会分成两个block,一个128M的block和一个2M的block
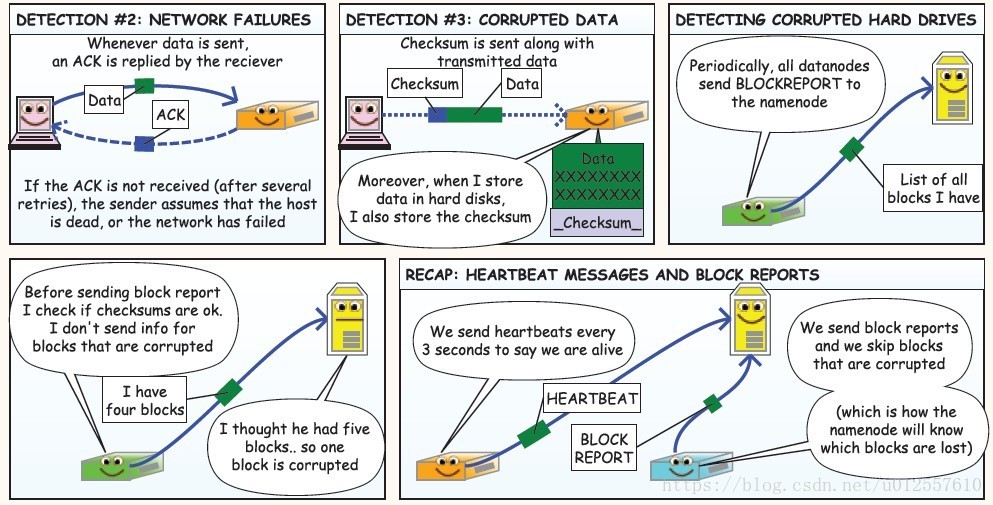
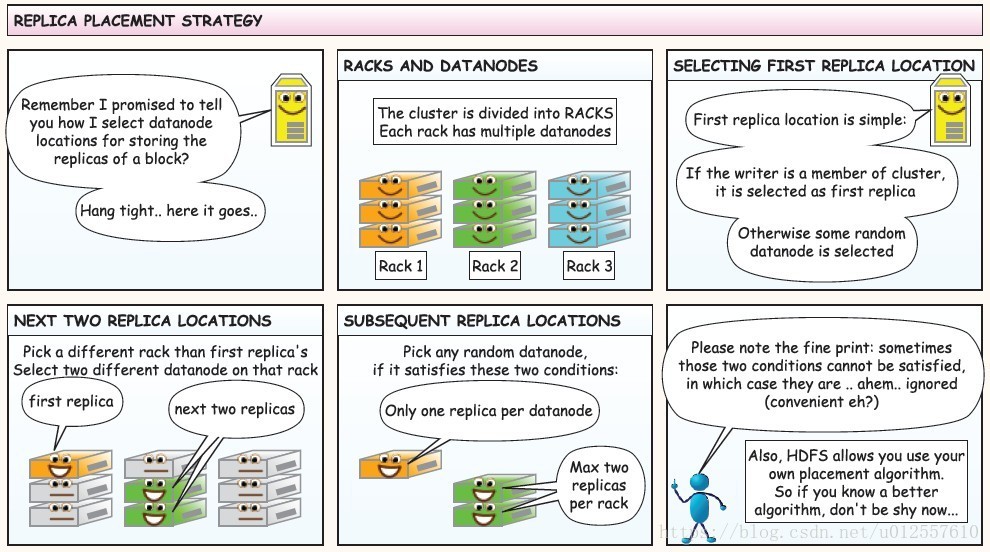
HDFS副本存放的策略
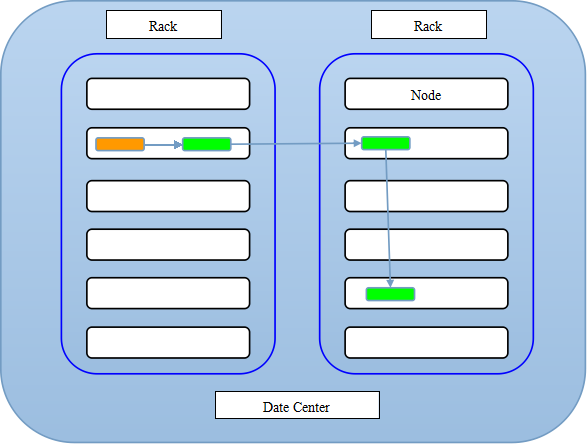
在上图中,蓝色框代表一个机架,一个机架上有很多个节点,黄色的代表一个writer,绿色的代表一个副本
The class is responsible for choosing the desired number of targets for placing block replicas.
The replica placement strategy is that if the writer is on a datanode,the 1st replica is placed on the local machine,
otherwise a random datanode.
The 2nd replica is placed on a datanode that is on a different rack.
The 3rd replica is placed on a datanode which is on a different node of the rack as the second replica.从上面的描述中可以看到
- 1st replica. 如果写请求方所在机器是其中一个datanode,则直接存放在本地,否则随机在集群中选择一个datanode.
- 2nd replica. 第二个副本存放于不同第一个副本的所在的机架.
- 3rd replica.第三个副本存放于第二个副本所在的机架,但是属于不同的节点.
HDFS使用Java API操作
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.net.URI;
/**
* Hadoop HDFS Java API 操作
*/
public class HDFSApp {
public static final String HDFS_PATH = "hdfs://master/";
FileSystem fileSystem = null;
Configuration configuration = null;
/**
* 创建HDFS目录
*/
@Test
public void mkdir() throws Exception {
fileSystem.mkdirs(new Path("/hdfsapi/test"));
}
/**
* 创建文件
*/
@Test
public void create() throws Exception {
FSDataOutputStream output = fileSystem.create(new Path("/hdfsapi/test/a.txt"));
output.write("hello hadoop".getBytes());
output.flush();
output.close();
}
/**
* 查看HDFS文件的内容
*/
@Test
public void cat() throws Exception {
FSDataInputStream in = fileSystem.open(new Path("/hdfsapi/test/a.txt"));
IOUtils.copyBytes(in, System.out, 1024);
in.close();
}
/**
* 重命名
*/
@Test
public void rename() throws Exception {
Path oldPath = new Path("/hdfsapi/test/a.txt");
Path newPath = new Path("/hdfsapi/test/b.txt");
fileSystem.rename(oldPath, newPath);
}
/**
* 上传文件到HDFS
*
* @throws Exception
*/
@Test
public void copyFromLocalFile() throws Exception {
Path localPath = new Path("/Users/xiaoysec/data/hello.txt");
Path hdfsPath = new Path("/hdfsapi/test");
fileSystem.copyFromLocalFile(localPath, hdfsPath);
}
/**
* 上传文件到HDFS
*/
@Test
public void copyFromLocalFileWithProgress() throws Exception {
InputStream in = new BufferedInputStream(
new FileInputStream(
new File("/Users/xiaoysec/source/spark-1.6.1/spark-1.6.1-bin-2.6.0-cdh5.5.0.tgz")));
FSDataOutputStream output = fileSystem.create(new Path("/hdfsapi/test/spark-1.6.1.tgz"),
new Progressable() {
public void progress() {
System.out.print("."); //带进度提醒信息
}
});
IOUtils.copyBytes(in, output, 4096);
}
/**
* 下载HDFS文件
*/
@Test
public void copyToLocalFile() throws Exception {
Path localPath = new Path("/Users/xiaoysec/tmp/h.txt");
Path hdfsPath = new Path("/hdfsapi/test/hello.txt");
fileSystem.copyToLocalFile(hdfsPath, localPath);
}
/**
* 查看某个目录下的所有文件
*/
@Test
public void listFiles() throws Exception {
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));
for(FileStatus fileStatus : fileStatuses) {
String isDir = fileStatus.isDirectory() ? "文件夹" : "文件";
short replication = fileStatus.getReplication();
long len = fileStatus.getLen();
String path = fileStatus.getPath().toString();
System.out.println(isDir + "\t" + replication + "\t" + len + "\t" + path);
}
}
/**
* 删除
*/
@Test
public void delete() throws Exception{
fileSystem.delete(new Path("/"), true);
}
@Before
public void setUp() throws Exception {
System.out.println("HDFSApp.setUp");
configuration = new Configuration();
fileSystem = FileSystem.get(new URI(HDFS_PATH), configuration, "hadoop");
}
@After
public void tearDown() throws Exception {
configuration = null;
fileSystem = null;
System.out.println("HDFSApp.tearDown");
}
}
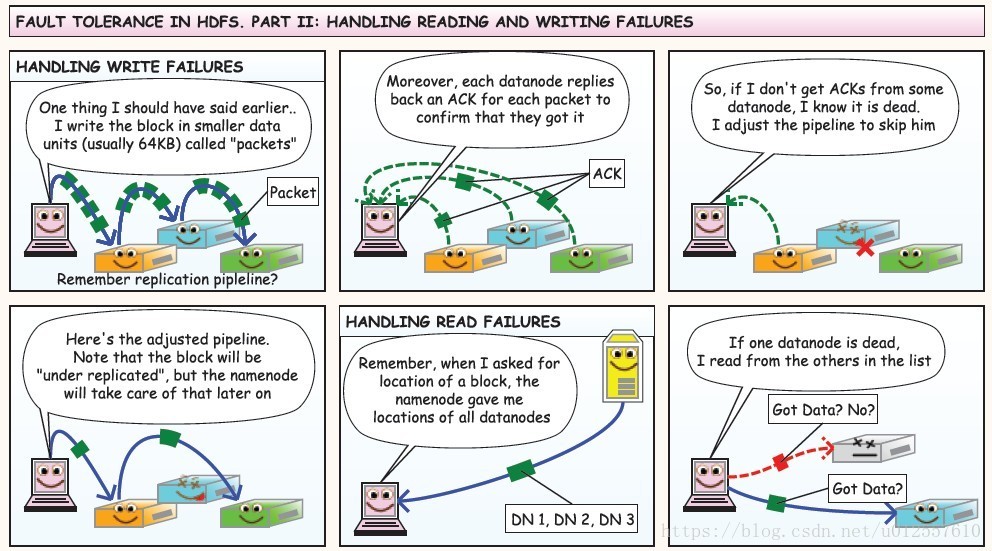
HDFS读写操作流程
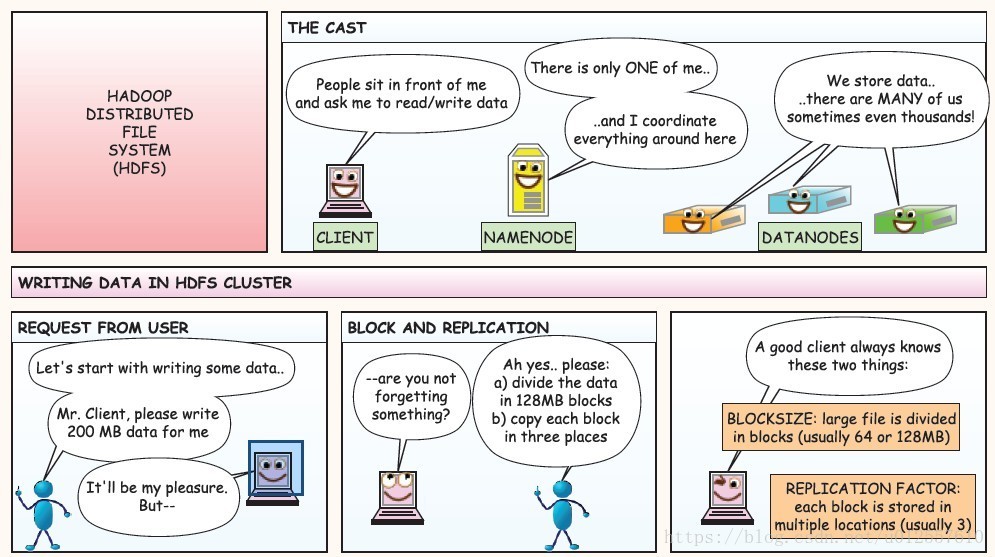
上图中Client可以是以shell的形式也可以是Java API调用的形式,在一个集群中有且只有一个NameNode,但可以有很多个DataNode

在向HDFS集群写数据的过程中,一个好的Client应该知道BlockSize和副本因子,也就是怎么将大文件分割成多个块,每个块的副本数
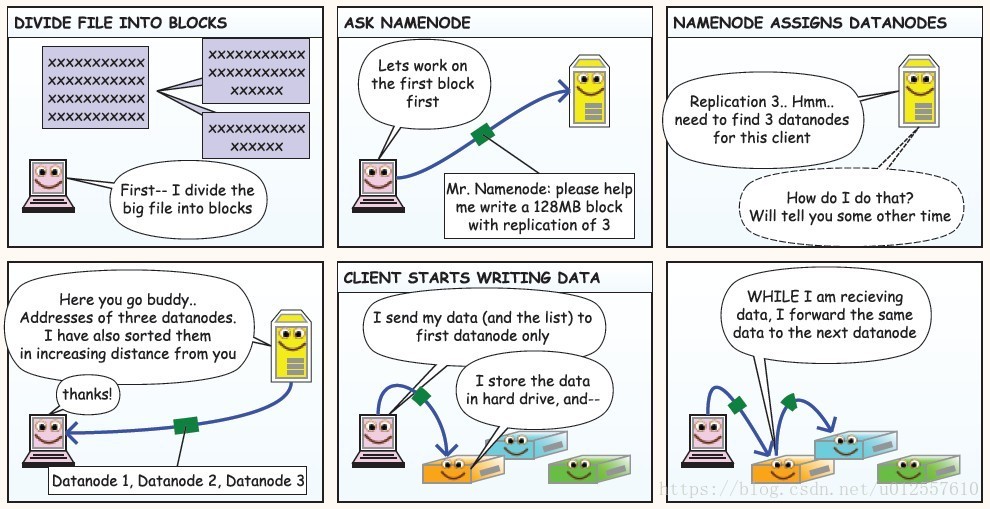
在用户发起请求过后,Client首先将文件根据BlockSize拆分成多个块,询问NameNode节点第一个block的三个副本应该放在哪几个DataNode上,在NameNode进行一番判断之后向Client返回可以存放block1的三个副本的三个DataNode的地址,这个时候,Client就可以将block1的内容发送给DataNode1,当DataNode1接收数据的同时,将数据同时传递给DataNode2
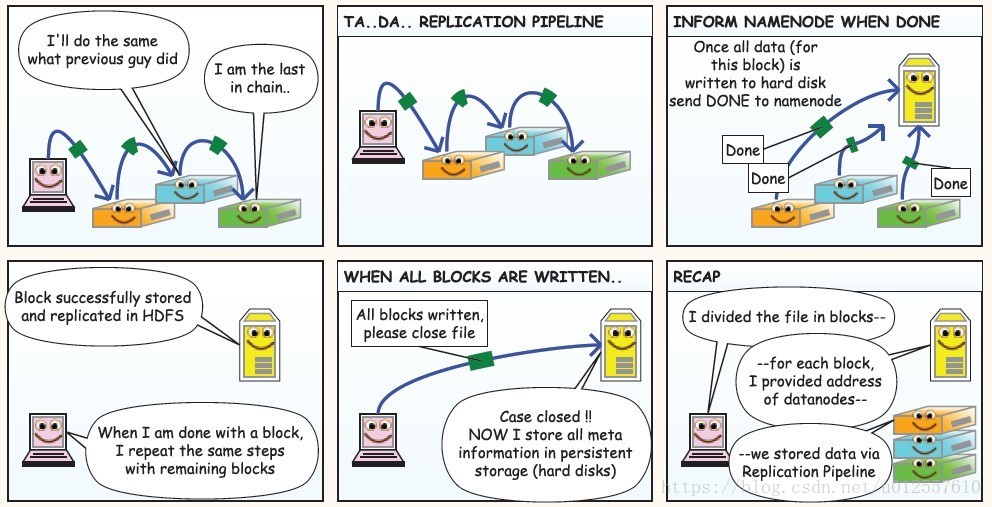
同样的,DataNode2在接收数据的同时将数据向DataNode3传递,当这个block所对应的数据DataNode接收完的时候,DataNode向NameNode汇报已经接收完毕,接着Client就可以发送第二个block了,当所有的block被接收完毕的时候Client就向NameNode请求关闭流,NameNode上存储了所有数据的元数据信息
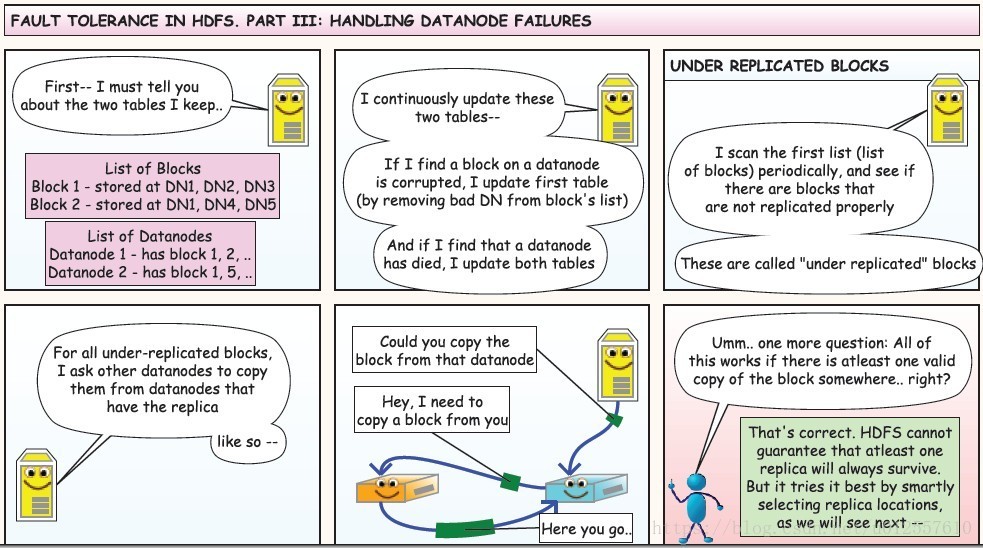
总的来说:
Client负责将数据分成多个block
NameNode负责与Client进行交互并保存数据的元信息
DataNode负责通过pipeline存储数据
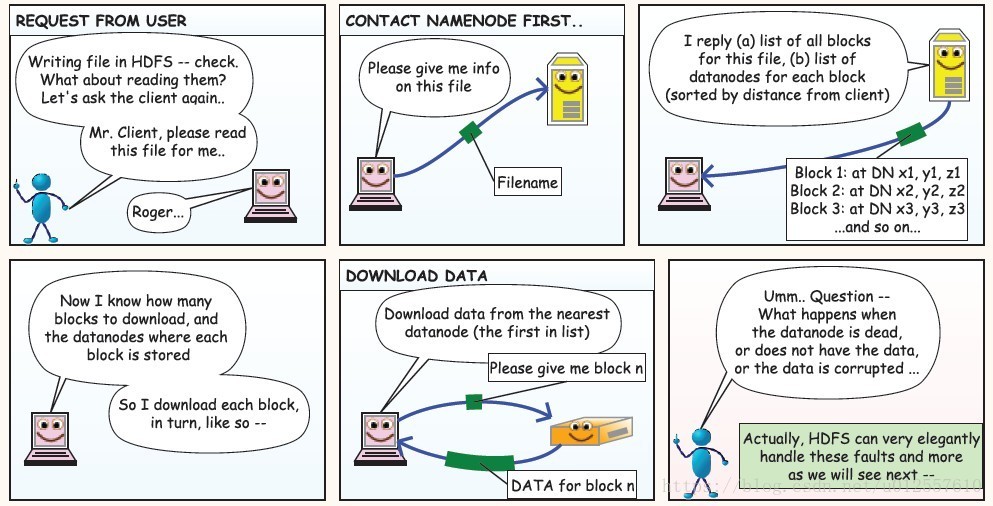
当需要读取文件的时候,Client需要向NameNode询问文件存储的位置,NameNode向Client返回一个list,其中包含了文件所有的block信息以及每个block在哪些DataNode上可以找到,Client接着向DataNode请求这些block