在今天的文章中,我来讲述如何使用Kafka来部署Elastic Stack。下面是我们最常用的一个Elastic Stack的部署方案图。
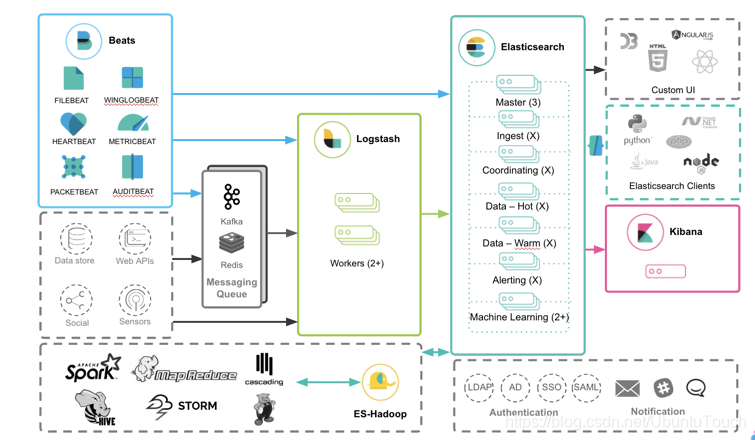
在上面我们可以看出来Beats的数据可以直接传入到Elasticsearch中,但是我们也可以看到另外一条路径,也就是Beats的数据也可以传入到Kafka中,并传入到 Logstash 中,最终导入到Elasticsearch中。那么为什么我们需要这个Kafka呢?
日志是不可预测的。 在发生生产事件后,恰恰在您最需要它们时,日志可能突然激增并淹没您的日志记录基础结构。 为了保护Logstash和Elasticsearch免受此类数据突发攻击,用户部署了缓冲机制以充当消息代理。

在本文中,我将展示如何使用ELK Stack和Kafka部署建立弹性数据管道所需的所有组件:
- Filebeat –收集日志并将其转发到Kafka主题。
- Kafka –代理数据流并将其排队。
- Logstash –汇总来自Kafka主题的数据,对其进行处理并将其发送到Elasticsearch。
- Elasticsearch –索引数据。
- Kibana –用于分析数据。
环境
我的环境如下:

在我的配置中,我使用了一个MacOS安装我的Elasticsearch及Kibana。另外我使用另外一个Ubuntu 18.04来安装我的Kafaka, Filebeat及Logstash。他们的IP地址分别如上所示。我们可以使用一个VM来安装我们的Ubuntu 18.04。
安装
为了能够完成我们的设置,我们做如下的安装:
安装Elasticseach
如果大家还没安装好自己的Elastic Stack的话,那么请按照我之前的教程“如何在Linux,MacOS及Windows上进行安装Elasticsearch” 安装好自己的Elasticsearch。由于我们的Elastic Stack需要被另外一个Ubuntu VM来访问,我们需要对我们的Elasticsearch进行配置。首先使用一个编辑器打开在config目录下的elasticsearch.yml配置文件。我们需要修改network.host的IP地址。在你的Mac及Linux机器上,我们可以使用:
$ ifconfig来查看到我们的机器的IP地址。针对我的情况,我的MacOS机器的IP地址是:192.168.43.220。

在上面我们把network.host设置为"_site",表明它绑定到我们的本地电脑的IP地址。详细说明请参阅Elasticsearch的network.host说明。
我们也必须在elasticsearch.yml的最后加上discovery.type: single-node,表明我们是单个node。
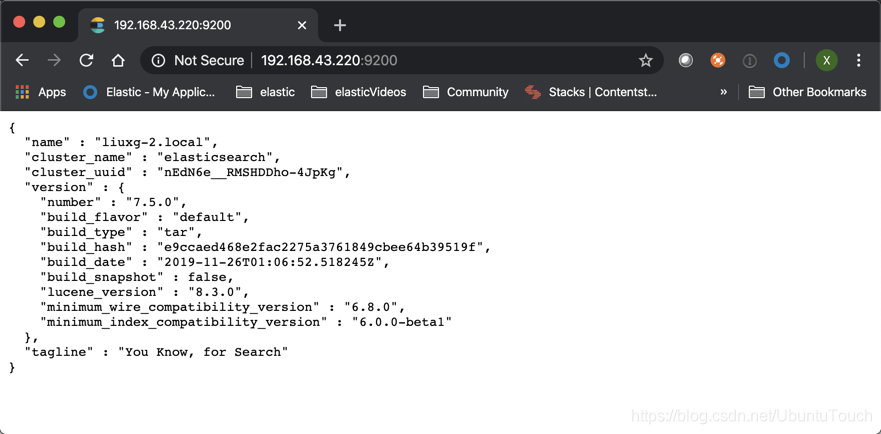
等修改完我们的IP地址后,我们保存elasticsearch.yml文件。然后重新运行我们的elasticsearch。我们可以在一个浏览器中输入刚才输入的IP地址并加上端口号9200。这样可以查看一下我们的elasticsearch是否已经正常运行了。
安装Kibana
我们可以按照“如何在Linux,MacOS及Windows上安装Elastic栈中的Kibana”中介绍的那样来安装我们的Kibana。由于我们的Elasticsearch的IP地址已经改变,所以我们必须修改我们的Kibana的配置文件。我们使用自己喜欢的编辑器打开在config目录下的kibana.yml文件,并找到server.host。把它的值修改为自己的电脑的IP地址。针对我的情况是:

同时找到elasticsearch.hosts,并把自己的IP地址输入进去:

保存我们的kibana.yml文件,并运行我们的Kibana。同时在浏览器的地址中输入自己的IP地址及5601端口:
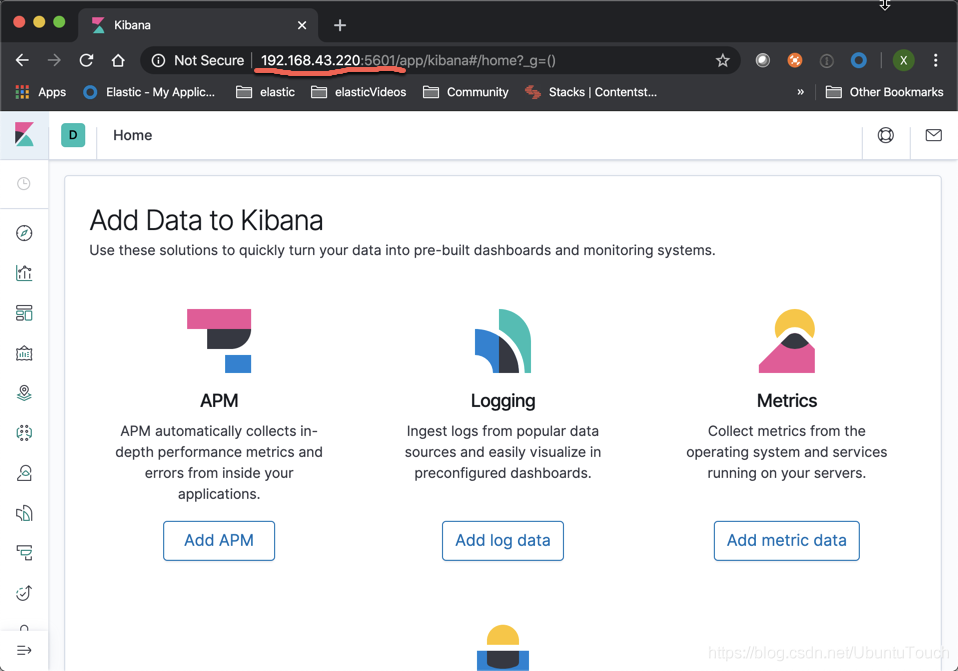
如果配置成功的话,我们就可以看到上面的画面。
安装Logstash
我们可以参考文章“如何安装Elastic栈中的Logstash”来在Ubuntu OS上安装我们的Logstash。
sudo apt-get install default-jre
curl -L -O https://artifacts.elastic.co/downloads/logstash/logstash-7.3.0.tar.gz
tar -xzvf logstash-7.3.0.tar.gz检查Java的版本信息:

我们创建一个叫做apache.conf的Logstash配置文件,并且它的内容如下:
apache.conf
input {
kafka {
bootstrap_servers => "localhost:9092"
topics => "apache"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => ["192.168.43.220:9200"]
}
如您所见-我们正在使用Logstash Kafka输入插件来定义Kafka主机和我们希望Logstash从中提取的主题。 我们将对日志进行一些过滤,并将数据发送到本地Elasticsearch实例。
安装Filebeat
在Ubuntu上安装Filebeat也是非常直接的。我们可以先打开我们的Kibana。

我们选择“Apache logs”

我们可以看到如下的画面:

在上面,我们选择DEB,因为Ubuntu OS是debian系统。按照上面的步骤,我们可以一步一步地安装Filebeat。
简单地说:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.5.0-amd64.deb
sudo dpkg -i filebeat-7.5.0-amd64.deb你可以在/etc/filebeat找到filebeat.yml配置文件。我们修改这个文件的内容为:
filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /etc/filebeat/access.log
output.kafka:
codec.format:
string: '%{[@timestamp]} %{[message]}'
hosts: ["192.168.43.192:9092"]
topic: apache
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000在输入部分,我们告诉Filebeat要收集哪些日志-apache访问日志。 在输出部分,我们告诉Filebeat将数据转发到本地Kafka服务器和相关主题 apache(将在下一步中安装)。Kafka将在Ubuntu OS上的9092口上接受数据。请注意我在上面配置access.log的路径为/etc/filebeat/access.log。在实际的使用中,我们需要根据apache的实际路径来配置,比如/var/log/apache2/access.log。
请注意codec.format指令的使用-这是为了确保正确提取message和timestamp字段。 否则,这些行将以JSON发送到Kafka。
安装Kafka
我们的最后也是最后一次安装涉及设置Apache Kafka(我们的消息代理)。Kafka使用ZooKeeper来维护配置信息和同步,因此在设置Kafka之前,我们需要先安装ZooKeeper:
sudo apt-get install zookeeperd接下来,让我们下载并解压缩Kafka:
wget https://apache.mivzakim.net/kafka/2.4.0/kafka_2.13-2.4.0.tgz
tar -xzvf kafka_2.13-2.4.0.tgz
sudo cp -r kafka_2.13-2.4.0 /opt/kafka现在,我们准备运行kafka,我们将使用以下脚本进行操作:
sudo /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties您应该开始在控制台中看到一些INFO消息:

我们接下来打开另外一个控制台中,并为Apache日志创建一个主题:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic apache我们创建了一个叫做apache的topic。上面的命令将返回如下的结果:
Created topic apache.我们现在已经完全为开始管道做好了准备。
开始测试
为了测试方便,我们可以在地址下载一个Apache access的log文件,并命名为access.log。我们可以把这个文件存于/etc/filebeat这个目录中,尽管这不是一个好的选择。在access.log的文档内容像如下文字:
80.135.37.131 - - [11/Sep/2019:23:56:45 +0000] "GET /item/giftcards/4852 HTTP/1.1" 200 91 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0.1) Gecko/20100101 Firefox/9.0.1"
68.186.206.172 - - [11/Sep/2019:23:56:50 +0000] "GET /category/cameras HTTP/1.1" 200 129 "/category/software" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"
启动Kafka
在上面的步骤中,我们已经成功地启动了Kafka,并同时创建了一个叫做apache的topic
启动Logstash
我们按照如下的方式来启动Logstash:
./bin/logstash -f apache.conf 我们在Logstash的安装目录里运行上面的命令。
启动filebeat
在/etc/filebeat目录中,有如下的文件:
liuxg@liuxg:/etc/filebeat$ pwd
/etc/filebeat
liuxg@liuxg:/etc/filebeat$ ls
access.log filebeat.reference.yml filebeat.yml.org
fields.yml filebeat.yml modules.daccess.log在我们当期的目录下。我们按照如下的方式来运行filebeat:
sudo service filebeat start如果我们想重新运行filebeat,可以打入如下的命令:
sudo service restart filebeat如果由于某种原因,我们想对我们的access.log重新被filebeat来执行一遍,那么我可以删除如下的registery目录:
cd /var/lib/filebeat/
rm -rf registry/
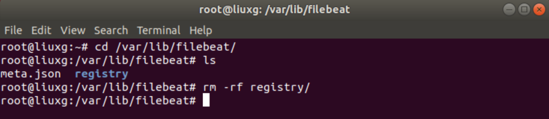
在删除这个registry目录后,我们再执行上面的restart指令即可。
我们可以在Kibana中查看logstash的文档:

我们也可以通过创建一个logstash的index pattern即可对我们的数据进行分析了。

