消息传递范式是一种聚合邻接节点信息来更新中心节点信息的范式,它将卷积算子推广到了不规则数据领域,实现了图与神经网络的连接。
此范式包含三个步骤:(1)邻接节点信息变换、(2)邻接节点信息聚合到中心节点、(3)聚合信息变换。
1.1 消息传递范式介绍
用 x i ( k − 1 ) ∈ R F \mathbf{x}^{(k-1)}_i\in\mathbb{R}^F xi(k−1)∈RF表示 ( k − 1 ) (k-1) (k−1)层中节点 i i i的节点特征, e j , i ∈ R D \mathbf{e}_{j,i} \in \mathbb{R}^D ej,i∈RD 表示从节点 j j j到节点 i i i的边的特征,消息传递图神经网络可以描述为
x i ( k ) = γ ( k ) ( x i ( k − 1 ) , □ j ∈ N ( i ) ϕ ( k ) ( x i ( k − 1 ) , x j ( k − 1 ) , e j , i ) ) , \mathbf{x}_i^{(k)} = \gamma^{(k)} \left( \mathbf{x}_i^{(k-1)}, \square_{j \in \mathcal{N}(i)} \, \phi^{(k)}\left(\mathbf{x}_i^{(k-1)}, \mathbf{x}_j^{(k-1)},\mathbf{e}_{j,i}\right) \right), xi(k)=γ(k)(xi(k−1),□j∈N(i)ϕ(k)(xi(k−1),xj(k−1),ej,i)),
其中 □ \square □表示可微分的、具有排列不变性(函数输出结果与输入参数的排列无关)的函数。具有排列不变性的函数有,和函数、均值函数和最大值函数。 γ \gamma γ和 ϕ \phi ϕ表示可微分的函数,如MLPs(多层感知器)。此处内容来源于CREATING MESSAGE PASSING NETWORKS。
1.2 MessagePassing基类
-该基类封装了消息传递的运行流程
- aggr:聚合方案,flow:消息传递的流向,node_dim:传播的具体维度
- MessagePassing.propagate():开始传递消息的起始调用
- MessagePassing.message():实现 ϕ \phi ϕ函数
- MessagePassing.aggregate():从源节点传递过来的消息聚合在目标节点上的函数,使用sum,mean和max
- MessagePassing.update():实现 γ \gamma γ函数
GCNConv的数学定义为
 步骤1-3通常是在消息传递发生之前计算的。步骤4-5可以使用
步骤1-3通常是在消息传递发生之前计算的。步骤4-5可以使用MessagePassing基类轻松处理。该层的全部实现如下所示。
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super(GCNConv, self).__init__(aggr='add', flow='source_to_target')
# 使用add聚合
# flow='source_to_target' 表示消息从源节点传播到目标节点
#线性变换
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x 维度 [N, in_channels]
# 邻接矩阵维度是 [2, E]
# Step 1: 向邻接矩阵添加自循环边
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: 对节点表征进行线性变换
#这个线性变换是np.dot(X,w)即可进行线性降维,改变特征的维度,其中这个w权重矩阵是随机生成的
x = self.lin(x)
# Step 3:计算归一化系数
row, col = edge_index
deg = degree(col, x.size(0), dtype=x.dtype)
deg_inv_sqrt = deg.pow(-0.5)
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col] #这个得到的便是每一条边的标准化系数*这条边target这一端的节点特征
# Step 4-5: 调用propagate函数,开启消息传递
return self.propagate(edge_index, x=x, norm=norm)
def message(self, x_j, norm):
# x_j 维度是[E, out_channels]
# Step 4: 将x_j进行归一化
return norm.view(-1, 1) * x_j
通过以上学习便掌握了创建一个仅包含依次“消息传递过程”的图神经网络的方法。
#这个含义即是将1433维的dataset进行降维到64维度
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='dataset', name='Cora')
data = dataset[0]
net = GCNConv(data.num_features, 64)
h_nodes = net(data.x, data.edge_index)
print(h_nodes.shape)
#torch.Size([2708, 64])
前向传播的demo
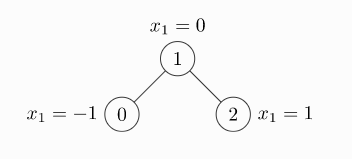
# 随机种子
torch.manual_seed(0)
# 定义边
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
# 定义节点特征,每个节点特征维度是2
x = torch.tensor([[-1, 2], [0, 4], [1, 5]], dtype=torch.float)
# 创建一层GCN层,并把特征维度从2维降到1维
conv = GCNConv(2, 1)
# 前向传播
x = conv(x, edge_index)
print(x)
print(conv.lin.weight)
tensor([[0.4728],
[0.9206],
[1.0365]], grad_fn=<ScatterAddBackward>)
Parameter containing:
tensor([[-0.0053, 0.3793]], requires_grad=True)
1.3 MessagePassing基类剖析
在__init__()方法中,我们看到程序会检查子类是否实现了message_and_aggregate()方法,并将检查结果赋值给fuse属性。
class MessagePassing(torch.nn.Module):
def __init__(self, aggr: Optional[str] = "add", flow: str = "source_to_target", node_dim: int = -2):
super(MessagePassing, self).__init__()
# 此处省略n行代码
# Support for "fused" message passing.
self.fuse = self.inspector.implements('message_and_aggregate')
# 此处省略n行代码
消息传递过程是从propagate方法被调用开始的
class MessagePassing(torch.nn.Module):
# 此处省略n行代码
def propagate(self, edge_index: Adj, size: Size = None, **kwargs):
# 此处省略n行代码
# Run "fused" message and aggregation (if applicable).
if (isinstance(edge_index, SparseTensor) and self.fuse and not self.__explain__):
coll_dict = self.__collect__(self.__fused_user_args__, edge_index, size, kwargs)
msg_aggr_kwargs = self.inspector.distribute('message_and_aggregate', coll_dict)
out = self.message_and_aggregate(edge_index, **msg_aggr_kwargs)
update_kwargs = self.inspector.distribute('update', coll_dict)
return self.update(out, **update_kwargs)
# Otherwise, run both functions in separation.
elif isinstance(edge_index, Tensor) or not self.fuse:
coll_dict = self.__collect__(self.__user_args__, edge_index, size, kwargs)
msg_kwargs = self.inspector.distribute('message', coll_dict)
out = self.message(**msg_kwargs)
# 此处省略n行代码
aggr_kwargs = self.inspector.distribute('aggregate', coll_dict)
out = self.aggregate(out, **aggr_kwargs)
update_kwargs = self.inspector.distribute('update', coll_dict)
return self.update(out, **update_kwargs)
参数简介:
- edge_index: 边端点索引,它可以是Tensor类型或SparseTensor类型。
- 当flow="source_to_target"时,节点edge_index[0]的信息将被传递到节点edge_index[1],
- 当flow="target_to_source"时,节点edge_index[1]的信息将被传递到节点edge_index[0]
- size: 邻接节点的数量与中心节点的数量。
- 对于普通图,邻接节点的数量与中心节点的数量都是N,我们可以不给size传参数,即让size取值为默认值None。
- 对于二部图,邻接节点的数量与中心节点的数量分别记为M, N,于是我们需要给size参数传一个元组(M, N)。
- kwargs: 图其他属性或额外的数据。
propagate()方法首先检查edge_index是否为SparseTensor类型以及是否子类实现了message_and_aggregate()方法,如是就执行子类的message_and_aggregate方法;否则依次执行子类的message(),aggregate(),update()三个方法
1.4 message方法的覆写
前面我们介绍了,传递给propagate()方法的参数,如果是节点的属性的话,可以被拆分成属于中心节点的部分和属于邻接节点的部分,只需在变量名后面加上_i或_j。现在我们有一个额外的节点属性,节点的度deg,我们希望meassge方法还能接收中心节点的度,我们对前面GCNConv的message方法进行改造得到新的GCNConv类。
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super(GCNConv, self).__init__(aggr='add', flow='source_to_target')
# "Add" aggregation (Step 5).
# flow='source_to_target' 表示消息从源节点传播到目标节点
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: Add self-loops to the adjacency matrix.
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: Linearly transform node feature matrix.
x = self.lin(x)
# Step 3: Compute normalization.
row, col = edge_index
deg = degree(col, x.size(0), dtype=x.dtype)
deg_inv_sqrt = deg.pow(-0.5)
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
# Step 4-5: Start propagating messages.
return self.propagate(edge_index, x=x, norm=norm, deg=deg.view((-1, 1)))
def message(self, x_j, norm, deg_i):
# x_j has shape [E, out_channels]
# deg_i has shape [E, 1]
# Step 4: Normalize node features.
return norm.view(-1, 1) * x_j * deg_i
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='dataset', name='Cora')
data = dataset[0]
net = GCNConv(data.num_features, 64)
h_nodes = net(data.x, data.edge_index)
print(h_nodes.shape)
1.5 aggregate方法的覆写
在前面的例子的基础上,我们增加如下的aggregate方法。通过观察运行结果我们可以看到,我们覆写的aggregate方法被调用,同时在super(GCNConv, self)._init_(aggr=‘add’)中传递给aggr参数的值被存储到了self.aggr属性中。
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super(GCNConv, self).__init__(aggr='add', flow='source_to_target')
# "Add" aggregation (Step 5).
# flow='source_to_target' 表示消息从源节点传播到目标节点
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: Add self-loops to the adjacency matrix.
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: Linearly transform node feature matrix.
x = self.lin(x)
# Step 3: Compute normalization.
row, col = edge_index
deg = degree(col, x.size(0), dtype=x.dtype)
deg_inv_sqrt = deg.pow(-0.5)
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
# Step 4-5: Start propagating messages.
return self.propagate(edge_index, x=x, norm=norm, deg=deg.view((-1, 1)))
def message(self, x_j, norm, deg_i):
# x_j has shape [E, out_channels]
# deg_i has shape [E, 1]
# Step 4: Normalize node features.
return norm.view(-1, 1) * x_j * deg_i
def aggregate(self, inputs, index, ptr, dim_size):
print('self.aggr:', self.aggr)
print("`aggregate` is called")
return super().aggregate(inputs, index, ptr=ptr, dim_size=dim_size)
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='dataset', name='Cora')
data = dataset[0]
net = GCNConv(data.num_features, 64)
h_nodes = net(data.x, data.edge_index)
print(h_nodes.shape)
1.6 message_and_aggregate方法的覆写
在一些案例中,“消息传递”与“消息聚合”可以融合在一起。对于这种情况,我们可以覆写message_and_aggregate方法,在message_and_aggregate方法中一块实现“消息传递”与“消息聚合”,这样能使程序的运行更加高效。
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
from torch_sparse import SparseTensor
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super(GCNConv, self).__init__(aggr='add', flow='source_to_target')
# "Add" aggregation (Step 5).
# flow='source_to_target' 表示消息从源节点传播到目标节点
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: Add self-loops to the adjacency matrix.
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: Linearly transform node feature matrix.
x = self.lin(x)
# Step 3: Compute normalization.
row, col = edge_index
deg = degree(col, x.size(0), dtype=x.dtype)
deg_inv_sqrt = deg.pow(-0.5)
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
# Step 4-5: Start propagating messages.
adjmat = SparseTensor(row=edge_index[0], col=edge_index[1], value=torch.ones(edge_index.shape[1]))
# 此处传的不再是edge_idex,而是SparseTensor类型的Adjancency Matrix
return self.propagate(adjmat, x=x, norm=norm, deg=deg.view((-1, 1)))
def message(self, x_j, norm, deg_i):
# x_j has shape [E, out_channels]
# deg_i has shape [E, 1]
# Step 4: Normalize node features.
return norm.view(-1, 1) * x_j * deg_i
def aggregate(self, inputs, index, ptr, dim_size):
print('self.aggr:', self.aggr)
print("`aggregate` is called")
return super().aggregate(inputs, index, ptr=ptr, dim_size=dim_size)
def message_and_aggregate(self, adj_t, x, norm):
print('`message_and_aggregate` is called')
# 没有实现真实的消息传递与消息聚合的操作
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='dataset', name='Cora')
data = dataset[0]
net = GCNConv(data.num_features, 64)
h_nodes = net(data.x, data.edge_index)
# print(h_nodes.shape)
1.7 update方法的覆写
from torch_geometric.datasets import Planetoid
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
from torch_sparse import SparseTensor
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super(GCNConv, self).__init__(aggr='add', flow='source_to_target')
# "Add" aggregation (Step 5).
# flow='source_to_target' 表示消息从源节点传播到目标节点
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: Add self-loops to the adjacency matrix.
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: Linearly transform node feature matrix.
x = self.lin(x)
# Step 3: Compute normalization.
row, col = edge_index
deg = degree(col, x.size(0), dtype=x.dtype)
deg_inv_sqrt = deg.pow(-0.5)
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
# Step 4-5: Start propagating messages.
adjmat = SparseTensor(row=edge_index[0], col=edge_index[1], value=torch.ones(edge_index.shape[1]))
# 此处传的不再是edge_idex,而是SparseTensor类型的Adjancency Matrix
return self.propagate(adjmat, x=x, norm=norm, deg=deg.view((-1, 1)))
def message(self, x_j, norm, deg_i):
# x_j has shape [E, out_channels]
# deg_i has shape [E, 1]
# Step 4: Normalize node features.
return norm.view(-1, 1) * x_j * deg_i
def aggregate(self, inputs, index, ptr, dim_size):
print('self.aggr:', self.aggr)
print("`aggregate` is called")
return super().aggregate(inputs, index, ptr=ptr, dim_size=dim_size)
def message_and_aggregate(self, adj_t, x, norm):
print('`message_and_aggregate` is called')
# 没有实现真实的消息传递与消息聚合的操作
def update(self, inputs, deg):
print(deg)
return inputs
dataset = Planetoid(root='dataset', name='Cora')
data = dataset[0]
net = GCNConv(data.num_features, 64)
h_nodes = net(data.x, data.edge_index)
# print(h_nodes.shape)
update方法接收聚合的输出作为第一个参数,此外还可以接收传递给propagate方法的任何参数。在上方的代码中,我们覆写的update方法接收了聚合的输出作为第一个参数,此外接收了传递给propagate的deg参数。
作业
-
请总结
MessagePassing类的运行流程以及继承MessagePassing类的规范。 -
请继承
MessagePassing类来自定义以下的图神经网络类,并进行测试:- 第一个类,覆写
message函数,要求该函数接收消息传递源节点属性x、目标节点度d。 - 第二个类,在第一个类的基础上,再覆写
aggregate函数,要求不能调用super类的aggregate函数,并且不能直接复制super类的aggregate函数内容。 - 第三个类,在第二个类的基础上,再覆写
update函数,要求对节点信息做一层线性变换。 - 第四个类,在第三个类的基础上,再覆写
message_and_aggregate函数,要求在这一个函数中实现前面message函数和aggregate函数的功能。
- 第一个类,覆写
from torch_geometric.datasets import Planetoid
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
from torch_sparse import SparseTensor
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super(GCNConv, self).__init__(aggr='add', flow='source_to_target')
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: Add self-loops to the adjacency matrix.
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: Linearly transform node feature matrix.
x = self.lin(x)
# Step 3: Compute normalization.
row, col = edge_index
deg = degree(col, x.size(0), dtype=x.dtype)
deg_inv_sqrt = deg.pow(-0.5)
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
# Step 4-5: Start propagating messages.
adjmat = SparseTensor(row=edge_index[0], col=edge_index[1], value=torch.ones(edge_index.shape[1]))
# 此处传的不再是edge_idex,而是SparseTensor类型的Adjancency Matrix
return self.propagate(adjmat, x=x, norm=norm, deg=deg.view((-1, 1)))
def message(self, x_j, norm, deg_i):
# x_j has shape [E, out_channels]
# deg_i has shape [E, 1]
# Step 4: Normalize node features.
return norm.view(-1, 1) * x_j * deg_i
def aggregate(self, inputs, index, ptr, dim_size):
print('self.aggr:', self.aggr)
print("`aggregate` is called")
return super().aggregate(inputs, index, ptr=ptr, dim_size=dim_size)
def message_and_aggregate(self, adj_t, x, norm):
print('`message_and_aggregate` is called')
# 没有实现真实的消息传递与消息聚合的操作
def update(self, inputs, deg):
print(deg)
return inputs
dataset = Planetoid(root='./codes/data/Planetoid/', name='Cora')
data = dataset[0]
net = GCNConv(data.num_features, 64)
h_nodes = net(data.x, data.edge_index)
参考链接 理解GCN的整个算法流程:
https://blog.csdn.net/qq_41987033/article/details/103377561