1.逻辑回归怎么实现多分类
方式一:修改逻辑回归的损失函数,使用 softmax 函数构造模型解决多分类问题,softmax 分 类模型会有相同于类别数的输出,输出的值为对于样本属于各个类别的概率,最后对于样本进行 预测的类型为概率值最高的那个类别.
方式二:根据每个类别都建立一个二分类器,本类别的样本标签定义为 0,其它分类样本标签 定义为 1,则有多少个类别就构造多少个逻辑回归分类器 若所有类别之间有明显的互斥则使用softmax 分类器,
若所有类别不互斥有交叉的情况则构造相应类别个数的逻辑回归分类器.
2.SVM 中什么时候用线性核什么时候用高斯核?
当数据的特征提取的较好,所包含的信息量足够大,很多问题是线性可分的那么可以采用线性核.若特征数较少,样本数适中,对于时间不敏感,遇到的问题是线性不可分的时候可以使用高 斯核来达到更好的效果.
3.什么是支持向量机,SVM 与 LR 的区别?
支持向量机为一个二分类模型,它的基本模型定义为特征空间上的间隔最大的线性分类器.而它的学习策略为最大化分类间隔,最终可转化为凸二次规划问题求解.
LR 是参数模型,SVM 为非参数模型.LR 采用的损失函数为 logistical loss,而 SVM 采用的是 hinge loss.在学习分类器的时候,SVM 只考虑与分类最相关的少数支持向量点.LR 的模型相对简单,在进行大规模线性分类时比较方便.
4.监督学习和无监督学习的区别
输入的数据有标签则为监督学习,输入数据无标签为非监督学习.
5.机器学习中的距离计算方法?
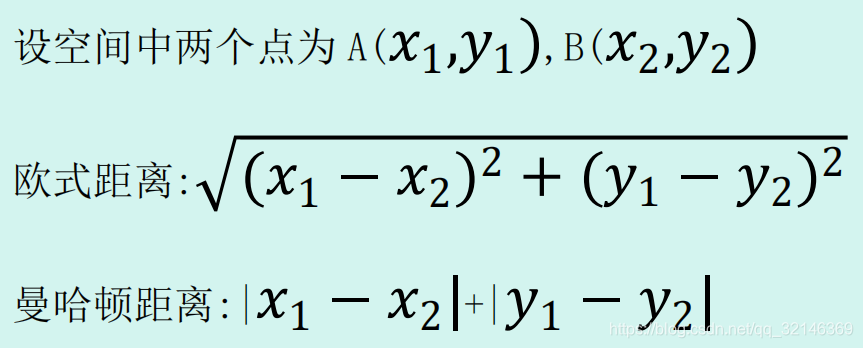
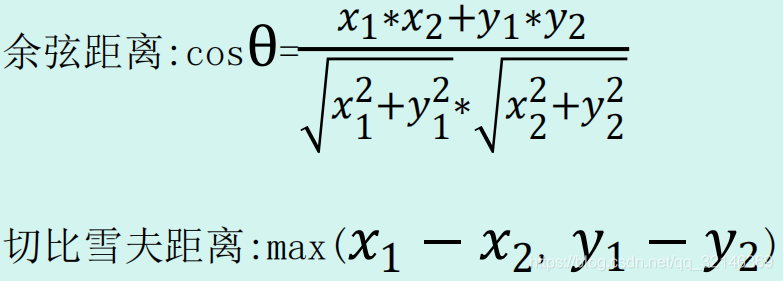
6. 朴素贝叶斯(naive Bayes)法的要求是?
朴素贝叶斯属于生成式模型,学习输入和输出的联合概率分布.给定输入 x,利用贝叶斯概率定理求出最大的后验概率作为输出 y.
7.训练集中类别不均衡,哪个参数最不准确?
举例,对于二分类问题来说,正负样例比相差较大为 99:1,模型更容易被训练成预测较大占比的类别.因为模型只需要对每个样例按照 0.99 的概率预测正类,该模型就能达到 99% 的准确率.
8.如果数据有问题,怎么处理;
1.上下采样平衡正负样例比;2.考虑缺失值;3.数据归一化
9.LR 和线性回归的区别
线性回归用来做预测,LR 用来做分类.线性回归是来拟合函数,LR 是来预测函数.线性回归用最小二乘法来计算参数,LR 用最大似然估计来计算参数.线性回归更容易受到异常值的影响, 而 LR 对异常值有较好的稳定性.
10.分类算法列一下有多少种?应用场景.
单一的分类方法主要包括:LR 逻辑回归,SVM 支持向量机,DT 决策树,NB 朴素贝叶斯,NN 人工神经网络,K-近邻;
集成学习算法:基于 Bagging 和 Boosting 算法思想,RF 随机森林,GBDT, Adaboost,XGboost.
11.SVM 的损失函数
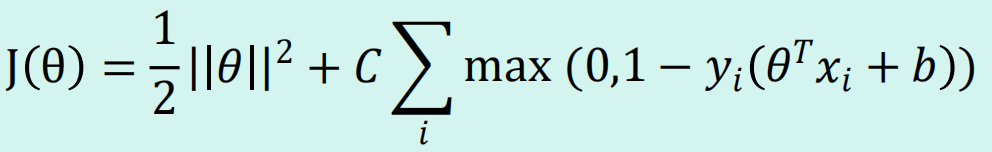
12. 核函数的作用
核函数隐含着一个从低维空间到高维空间的映射,这个映射可以把低维空间中线性不可分的 两类点变成线性可分的.
13.SVM 为什么使用对偶函数求解
对偶将原始问题中的约束转为了对偶问题中的等式约束,而且更加方便了核函数的引入,同 时也改变了问题的复杂度,在原始问题下,求解问题的复杂度只与样本的维度有关,在对偶问题下, 只与样本的数量有关.
14.ID3,C4.5 和 CART 三种决策树的区别
ID3 决策树优先选择信息增益大的属性来对样本进行划分,但是这样的分裂节点方法有一个很大的缺点,当一个属性可取值数目较多时,可能在这个属性对应值下的样本只有一个或者很少 个,此时它的信息增益将很高,ID3 会认为这个属性很适合划分,但实际情况下叫多属性的取值会 使模型的泛化能力较差,所以 C4.5 不采用信息增益作为划分依据,而是采用信息增益率作为划分 依据.但是仍不能完全解决以上问题,而是有所改善,这个时候引入了 CART 树,它使用 gini 系数 作为节点的分裂依据.
