MapReudce(二)
Hadoop04:MR编程规则及原理深入
一、回顾
1、MapReduce
- 运行的两个阶段
- Map:由MapTask进程完成
- Input+Map+Map端的shuffle
- Reduce:由ReduceTask进程完成
- Reduce端的shuffle+Reduce+Output
- Map:由MapTask进程完成
- 逻辑的五个阶段
- Input
- InputFormat
- 1-将所有给定的数据源转换成keyvalue
- 2-进行任务的拆分:计算:每个小的任务:分片:split
- 假设:100万条数据,按1万条数据1个split,共100个split
- 存储:每个小的 存储:分块:block
- 默认:TextInputFormat
- InputFormat
- Map:第一个处理逻辑
- Mapper<keyin,valuein,keyout,valueout>
- 1-根据Input阶段中Split的个数,来启动对应的 MapTask :1个split = 1MapTask
- 100split = 100 MapTask : 每个mapTask处理1万条数据
- 2-负责所有数据的第一步转换:转换逻辑:map方法决定
- 填空:由需求决定map方法怎么写
- Shuffle:第二个处理逻辑,自动实现三大功能
- 分区:Partitioner
- 当有多个reduce的情况下,决定了当前的这条数据会被哪个reduce进行处理
- 默认方式:按照key的hash分区
- Hash分区存在的问题:导致数据倾斜
- 自定义分区
- 继承Partitioner<key,value>
- 重写方法:pubilc int getPartition(key,value,reduceNumber)
- 返回对应的 分区编号
- 排序:Sort
- 对key进行排序
- 默认方式:对key按照字典顺序排序
- 分组:Group
- 对所有的keyvalue,按照key进行分组,每组就是每个key只有一条,相同key的value放入同一个迭代器中
- 分区:Partitioner
- Reduce:第三个处理逻辑
- Reducer<keyin,valuein,keyout,valueout>
- 用于启动一个ReduceTask来实现将之前所有拆分的数据进行合并
- 合并逻辑:reduce,根据业务来决定reduce方法的实现
- Output
- OutputFormat
- TextOutputFormat:将keyvalue写入文件,并且key与value之间用制表符分隔
- 将Reduce的结果进行输出
- Input
2、编程规则
- 数据类型:Hadoop的序列化类型,Text、IntWritable……
- 数据结构:KeyValue
- 编程模型:
- Driver类
- 必须包含main,作为程序的入口
- main:作为程序入口,负责调用run方法
- run:初始化一个job,配置job,提交job的运行
- 只有job被提交之后,后面五大阶段才开始运行
- Input类:TextInputFormat
- Map类:map方法
- Shuffle
- 分区器:HashPartitioner
- 排序器
- 分组器
- Reduce类:reduce方法
- Output:TextOutputFormat
- Driver类
二、课程目标
- MapReduce程序历史监控【掌握】
- jobhistoryserver:用于监控所有运行过的程序的日志信息
- MapReduce中自定义数据类型【重点】
- 自定义Hadoop中的序列化类型,封装JavaBean
- 排序
- 手机流量分析案例【掌握】
- Shuffle过程初探【了解】
三、MapReduce程序历史监控
1、MapReduce的HistoryServer的功能
- 问题:每次YARN重启以后,之前运行过的程序就看不到了,并且看不到每个程序具体的运行的信息
- 原因:每个程序的具体运行信息由单独的一个进程来管理:JobHistoryServer
- 管理所有运行过的程序的运行日志
- 解决:手动配置JobHitoryServer
2、YARN日志聚集的功能
- 将所有程序的运行日志存储在HDFS上
3、配置启动测试
-
先配置MapReduce的JobHitosryServer
-
修改mapred-site.xml
<!--配置JobHistoryServer进程的地址--> <property> <name>mapreduce.jobhistory.address</name> <value>node-02:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node-02:19888</value> </property>
-
-
再配置YARN的日志聚集功能
-
修改yarn-site.xml
<!--配置日志聚集的启动--> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!--配置日志聚集的自动删除--> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
-
-
分发
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/ scp mapred-site.xml yarn-site.xml node-02:$PWD scp mapred-site.xml yarn-site.xml node-03:$PWD -
启动测试
-
在第一台机器启动hdfs
-
在第二台机器启动JobHistoryServer
sbin/mr-jobhistory-daemon.sh start historyserver -
在第三台机器启动yarn
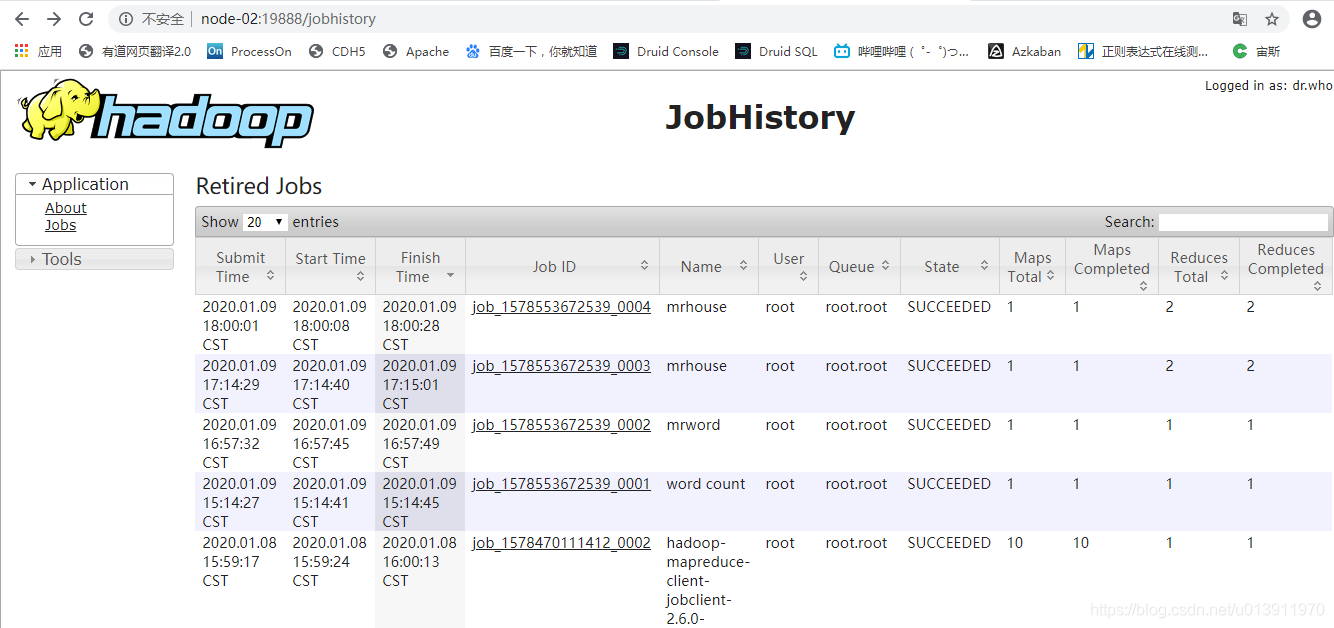
-
四、MapReduce中自定义数据类型
1、Hadoop中的类型
- 为什么不用Java中的类型?
- 因为Hadoop是分布式的,所有的数据类型要经过网络传输,必须序列化
- String age= “1”
- 不做序列化:A -> 1 ->B -> B只知道数据是什么
- 做序列化:A -> 对象:String age= “1” ->B知道数据是什么,也知道类型
- 因为Hadoop是分布式的,所有的数据类型要经过网络传输,必须序列化
- Hadoop中提供了哪些序列化类型?
- Text、NullWritable、IntWritable、DoubleWritable、BooleanWritable……
- 为什么要自定义数据类型?
- 因为整个Hadoop中所有数据只能以keyvalue进行传输
- Hadoop自带的类型,只能保存一个字段
- 如果我们需要传输计算多个字段 N>2,无法实现【拼接字符串】
- 所有Hadoop中也提供了自定义序列化类型的接口
2、自定义数据类型
- MapReduce程序的两种类型
- 没有shuffle:Input -> Map -> Output
- 一般用于ETL的过程:数据清洗
- 原来的数据中有100个字段,只需要50列
- 输入多少行,就输出多少行
- 原来的数据中有100个字段,只需要50列
- 一般用于ETL的过程:数据清洗
- 有shuffle:Input -> Map -> Shuffle -> Reduce -> Output
- 没有shuffle:Input -> Map -> Output
- 自定义数据类型的规则
- 第一种:实现Writable的接口
- 定义属性
- 重写方法:
- 构造
- get and set
- 序列化:write
- 反序列化:readFields
- toString
- 第二种:实现WritableComparable接口
- 定义属性
- 重写方法:
- 构造
- get and set
- 序列化:write
- 反序列化:readFields
- toString
- compareTo:用于比较两个相同的对象
- 区分:什么时候需要用第一种,什么时候用第二种
- 当前这个自定义的类型是否会作为Map输出的Key经过shuffle
- 如果是:用第二种
- 如果不是:用第一种
- 弄不清楚:全部用第二种
- 当前这个自定义的类型是否会作为Map输出的Key经过shuffle
- 第一种:实现Writable的接口
- 需求1:将wordcount程序中Map阶段的结果输出,并且有三列:单词、单词长度、1
- key:单词、单词长度
- value:1
- 需求2:将wordcount程序中Reduce的结果输出,并且有三列:单词、单词长度、单词个数
3、测试
-
将wordcount中map的结果进行输出,包含三列:单词、单词长度、1
-
自定义数据类型:实现Writable接口
/** * @ClassName WordCountBean * @Description TODO 自定义数据类型,用于封装单词和单词长度 * @Date 2020/1/11 11:01 * @Create By Frank */ public class WordCountBean implements Writable { //定义属性 private String word; private int length ; //构造 public WordCountBean() { } //一次性给所有属性赋值 public void setALL(String word, int length) { this.setWord(word); this.setLength(length); } //get and set public String getWord() { return word; } public void setWord(String word) { this.word = word; } public int getLength() { return length; } public void setLength(int length) { this.length = length; } //序列化 @Override public void write(DataOutput out) throws IOException { //输出两个对象 out.writeUTF(this.word); out.writeInt(this.length); } //反序列化:注意顺序必须与序列化的顺序保持一致,不然会导致值错乱 @Override public void readFields(DataInput in) throws IOException { //读出两个对象 this.word = in.readUTF(); this.length = in.readInt(); } //toString方法,在输出的 时候会被调用,写入文件或者打印 @Override public String toString() { return this.word+"\t"+this.length; } } -
输出Map的结果
/** * @ClassName WordCount * @Description TODO 用于实现Wordcount的MapReduce * @Date 2020/1/9 16:00 * @Create By Frank */ public class WordCountMapOut extends Configured implements Tool { /** * 构建一个MapReduce程序,配置程序,提交程序 * @param args * @return * @throws Exception */ @Override public int run(String[] args) throws Exception { /** * 第一:构造一个MapReduce Job */ //构造一个job对象 Job job = Job.getInstance(this.getConf(),"mrword"); //设置job运行的类 job.setJarByClass(WordCountMapOut.class); /** * 第二:配置job */ //input:设置输入的类以及输入路径 // job.setInputFormatClass(TextInputFormat.class); 这是默认的 Path inputPath = new Path("datas/word/count.txt");//以程序的第一个参数作为输入路径 TextInputFormat.setInputPaths(job,inputPath); //shuffle //map job.setMapperClass(WordCountMapper.class);//指定Mapper的类 job.setMapOutputKeyClass(WordCountBean.class);//指定map输出的key的类型 job.setMapOutputValueClass(IntWritable.class);//指定map输出的value的类型 //shuffle //reduce // job.setReducerClass(WordCountReduce.class);//指定reduce的类 // job.setOutputKeyClass(Text.class);//指定reduce输出的 key类型 // job.setOutputValueClass(IntWritable.class);//指定reduce输出的value类型 job.setNumReduceTasks(0);//这是默认的,没有reduce记得设置为0 //output // job.setOutputFormatClass(TextOutputFormat.class);//这是默认的输出类 Path outputPath = new Path("datas/output/mapoutpupt");//用程序的第二个参数作为输出路径 //如果输出目录已存在,就删除 FileSystem hdfs = FileSystem.get(this.getConf()); if(hdfs.exists(outputPath)){ hdfs.delete(outputPath,true); } //设置输出的地址 TextOutputFormat.setOutputPath(job,outputPath); /** * 第三:提交job */ //提交job运行,并返回boolean值,成功返回true,失败返回false return job.waitForCompletion(true) ? 0 : -1; } /** * 整个程序的入口,负责调用当前类的run方法 * @param args */ public static void main(String[] args) { //构造一个conf对象,用于管理当前程序的所有配置 Configuration conf = new Configuration(); try { //调用当前类的run方法 int status = ToolRunner.run(conf, new WordCountMapOut(), args); //根据程序运行的 结果退出 System.exit(status); } catch (Exception e) { e.printStackTrace(); } } /** * Mapper的类,实现四个泛型,inputkey,inputValue,outputKey,outputValue * 输入的泛型:由输入的类决定:TextInputFormat:Longwritable Text * 输出的泛型:由代码逻辑决定:Text,IntWritable * 重写map方法 */ public static class WordCountMapper extends Mapper<LongWritable, Text, WordCountBean, IntWritable>{ //构造用于输出的key和value private WordCountBean outputKey = new WordCountBean(); private IntWritable outputValue = new IntWritable(1); /** * map方法:Input传递过来的每一个keyvalue会调用一次map方法 * @param key:当前的 key * @param value:当前的value * @param context:上下文,负责将新的keyvalue输出 * @throws IOException * @throws InterruptedException */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //将每一行的内容转换为String String line = value.toString(); //对每一行的内容分割 String[] words = line.split(" "); //迭代取出每个单词 for(String word:words){ //将单词赋值给key this.outputKey.setWord(word); this.outputKey.setLength(word.length()); //输出 context.write(this.outputKey,this.outputValue); } } } }
-
-
将wordcount中reduce的结果进行输出,包含三列:单词、单词长度、个数
-
自定义数据类型:实现WritableComparable接口
/** * @ClassName WordCountBean * @Description TODO 自定义数据类型,用于封装单词和单词长度 * @Date 2020/1/11 11:01 * @Create By Frank */ public class WordCountBean implements WritableComparable<WordCountBean> { //定义属性 private String word; private int length ; //构造 public WordCountBean() { } //一次性给所有属性赋值 public void setALL(String word, int length) { this.setWord(word); this.setLength(length); } //get and set public String getWord() { return word; } public void setWord(String word) { this.word = word; } public int getLength() { return length; } public void setLength(int length) { this.length = length; } //序列化 @Override public void write(DataOutput out) throws IOException { //输出两个对象 out.writeUTF(this.word); out.writeInt(this.length); } //反序列化:注意顺序必须与序列化的顺序保持一致,不然会导致值错乱 @Override public void readFields(DataInput in) throws IOException { //读出两个对象 this.word = in.readUTF(); this.length = in.readInt(); } //toString方法,在输出的 时候会被调用,写入文件或者打印 @Override public String toString() { return this.word+"\t"+this.length; } //用于在shuffle阶段的排序以及分组 @Override public int compareTo(WordCountBean o) { //先比较第一个值 int comp = this.getWord().compareTo(o.getWord()); if(0 == comp){ //如果第一个值,相等,以第二个值的比较结果作为最终的结果 return Integer.valueOf(this.getLength()).compareTo(Integer.valueOf(o.getLength())); } return comp; } } -
输出reduce的结果
/** * @ClassName WordCount * @Description TODO 用于实现Wordcount的MapReduce * @Date 2020/1/9 16:00 * @Create By Frank */ public class WordCountMapOut extends Configured implements Tool { /** * 构建一个MapReduce程序,配置程序,提交程序 * @param args * @return * @throws Exception */ @Override public int run(String[] args) throws Exception { /** * 第一:构造一个MapReduce Job */ //构造一个job对象 Job job = Job.getInstance(this.getConf(),"mrword"); //设置job运行的类 job.setJarByClass(WordCountMapOut.class); /** * 第二:配置job */ //input:设置输入的类以及输入路径 // job.setInputFormatClass(TextInputFormat.class); 这是默认的 Path inputPath = new Path("datas/word/count.txt");//以程序的第一个参数作为输入路径 TextInputFormat.setInputPaths(job,inputPath); //shuffle //map job.setMapperClass(WordCountMapper.class);//指定Mapper的类 job.setMapOutputKeyClass(WordCountBean.class);//指定map输出的key的类型 job.setMapOutputValueClass(IntWritable.class);//指定map输出的value的类型 //shuffle //reduce job.setReducerClass(WordCountReduce.class);//指定reduce的类 job.setOutputKeyClass(WordCountBean.class);//指定reduce输出的 key类型 job.setOutputValueClass(IntWritable.class);//指定reduce输出的value类型 job.setNumReduceTasks(1);//这是默认的,没有reduce记得设置为0 //output // job.setOutputFormatClass(TextOutputFormat.class);//这是默认的输出类 Path outputPath = new Path("datas/output/reduceoutput");//用程序的第二个参数作为输出路径 //如果输出目录已存在,就删除 FileSystem hdfs = FileSystem.get(this.getConf()); if(hdfs.exists(outputPath)){ hdfs.delete(outputPath,true); } //设置输出的地址 TextOutputFormat.setOutputPath(job,outputPath); /** * 第三:提交job */ //提交job运行,并返回boolean值,成功返回true,失败返回false return job.waitForCompletion(true) ? 0 : -1; } /** * 整个程序的入口,负责调用当前类的run方法 * @param args */ public static void main(String[] args) { //构造一个conf对象,用于管理当前程序的所有配置 Configuration conf = new Configuration(); try { //调用当前类的run方法 int status = ToolRunner.run(conf, new WordCountMapOut(), args); //根据程序运行的 结果退出 System.exit(status); } catch (Exception e) { e.printStackTrace(); } } /** * Mapper的类,实现四个泛型,inputkey,inputValue,outputKey,outputValue * 输入的泛型:由输入的类决定:TextInputFormat:Longwritable Text * 输出的泛型:由代码逻辑决定:Text,IntWritable * 重写map方法 */ public static class WordCountMapper extends Mapper<LongWritable, Text, WordCountBean, IntWritable>{ //构造用于输出的key和value private WordCountBean outputKey = new WordCountBean(); private IntWritable outputValue = new IntWritable(1); /** * map方法:Input传递过来的每一个keyvalue会调用一次map方法 * @param key:当前的 key * @param value:当前的value * @param context:上下文,负责将新的keyvalue输出 * @throws IOException * @throws InterruptedException */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //将每一行的内容转换为String String line = value.toString(); //对每一行的内容分割 String[] words = line.split(" "); //迭代取出每个单词 for(String word:words){ //将单词赋值给key this.outputKey.setWord(word); this.outputKey.setLength(word.length()); //输出 context.write(this.outputKey,this.outputValue); } } } /** * 所有的Reduce都需要实现四个泛型 * 输入的keyvalue:就是Map的 输出的keyvalue类型 * 输出的keyvalue:由代码逻辑决定 * 重写reduce方法 */ public static class WordCountReduce extends Reducer<WordCountBean, IntWritable,WordCountBean, IntWritable>{ private IntWritable outputValue = new IntWritable(); /** * reduce方法 ,每一个keyvalue,会调用一次reduce方法 * @param key:传进来的key * @param values:迭代器,当前key的所有value * @param context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(WordCountBean key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //取出迭代器的值进行累加 int sum = 0; for (IntWritable value : values) { sum += value.get(); } //封装成输出的value this.outputValue.set(sum); //输出每一个key的结果 context.write(key,outputValue); } } }
-
-
基于各地区的二手房个数、平均单价、最低单价、最高单价
-
第一步:看结果
- 地区 个数 平均 最低 最高
-
第二步:看分组或者排序
- 按照地区分组:key
-
第三步:看其他的结果字段定value:单价
-
第四步:带入
-
input
-
map
- 逻辑:将每一行的地区和单价这两个字段取出
- key:地区
- value:单价
-
shuffle
- 分组:相同地区的所有房子的单价放入同一个迭代器
-
reduce(key,Iterator<每套房子的单价>)
-
逻辑
-
将迭代器中的每条单价取出,放入集合
//注意:不能直接将迭代器中的类型直接放入集合,取里面的基本类型的值放入 List lists = new ArrayList<Double> for(DoubleWritable value : values){ lists.add(value.get()) count++ sum+= value.get() } Collections.sort(lists) -
个数:count
-
平均: sum/count
-
最低:lists.get(0)
-
最高:lists.get(list.size-1)
-
-
-
output
-
-
-
排序的两种方式
-
如果是自定义数据类型:可以调用该类型中的compareTo方法实现排序
-
官方默认的排序器:对key进行升序
-
官方提供了一个排序器的接口
-
job.setSortComparatorClass(null);//自定义排序规则 -
需求:希望实现对WordCount的结果进行key的降序
-
实现
-
先自定义一个 排序器
import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /** * @ClassName UserSort * @Description TODO 用户自定义排序器 * @Date 2020/1/11 11:47 * @Create By Frank */ public class UserSort extends WritableComparator { /** * 注册类型的转换 */ public UserSort() { //类型的转换注册,允许将类型转换为Text super(Text.class,true); } /** * 调用排序的方法 * @param a * @param b * @return */ @Override public int compare(WritableComparable a, WritableComparable b) { //需求:比较Text类型,传入WritableComparable,要进行转换 Text o1 = (Text) a; Text o2 = (Text) b; //降序 return -o1.compareTo(o2); } }
-
-
-
-
加载排序器并实现业务逻辑
job.setSortComparatorClass(UserSort.class);//自定义排序规则 -
源码中调用排序的逻辑
- 是否有自定义排序器
- 有:就用自定义排序器
- 没有:进入下一步判断
- 判断该类型是否有comparaTo方法
- 有:就用compareTo方法
- 没有:调用默认的key的字典顺序升序排序器
- 有:就用自定义排序器
- 是否有自定义排序器
五、手机流量分析案例
1、需求
- 基于给定的数据统计实现每个手机号的上行包总和、下行包总和、上行流量总和、下行流量总和
- 基于第一个需求的结果来进行处理,将结果数据按照上行包总和进行降序排序
- 基于第一个程序的结果,将数据写入不同的文件
2、需求1的实现
-
分析
-
第一步:看结果
手机号 上行总包 下行总包 上行总流量 下行总流量
-
第二步:看需求中有没有分组或者排序
- 分组:每个手机号
- Map输出的key就决定了
-
第三步:看剩余的结果中需要使用哪些字段来实现
-
第四步:分析验证
- Input:读取文件,变成keyvalue对
- Map:map方法
- 逻辑
- 对每条数据进行分割
- 取出需要用到的五个字段
- 后面四个字段封装javabean
- 输出
- key:手机号
- value:上行包、下行包、上行流量、下行流量
- 逻辑
- Shuffle
- 分区:本质是打标签
- 排序:按照手机号码进行排序
- 分组
- 相同手机号码的所有数据都放入了一个迭代器中
- Reduce
- 从迭代器中取出每个业务值,进行业务累加即可
- Output
-
实现
-
自定义数据类型
/** 流量案例1的自定义数据类型 */ public class FlowBean1 implements Writable { private long upPack; private long downPack; private long upFlow; private long downFlow; public FlowBean1() { } public void setAll(long upPack, long downPack, long upFlow, long downFlow) { this.setUpPack(upPack); this.setDownPack(downPack); this.setUpFlow(upFlow); this.setDownFlow(downFlow); } public long getUpPack() { return upPack; } public void setUpPack(long upPack) { this.upPack = upPack; } public long getDownPack() { return downPack; } public void setDownPack(long downPack) { this.downPack = downPack; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } @Override public void write(DataOutput out) throws IOException { out.writeLong(this.upPack); out.writeLong(this.downPack); out.writeLong(this.upFlow); out.writeLong(this.downFlow); } @Override public void readFields(DataInput in) throws IOException { this.upPack = in.readLong(); this.downPack = in.readLong(); this.upFlow = in.readLong(); this.downFlow = in.readLong(); } @Override public String toString() { return this.upPack+"\t"+this.downPack+"\t"+this.upFlow+"\t"+this.downFlow; } } -
mr实现
/** *实现流量案例的需求1 */ public class FlowMr1 extends Configured implements Tool { //构建一个job,配置job,提交运行job @Override public int run(String[] args) throws Exception { //构建 Job job = Job.getInstance(this.getConf(),"flow1"); job.setJarByClass(FlowMr1.class); //配置 Path inputPath = new Path("datas/flowCase/data_flow.dat"); TextInputFormat.setInputPaths(job,inputPath); job.setMapperClass(FlowMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean1.class); job.setReducerClass(FlowReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean1.class); Path outputPath = new Path("datas/output/flow/flow1"); TextOutputFormat.setOutputPath(job,outputPath); //提交 return job.waitForCompletion(true) ? 0 : -1; } //作为程序的入口 public static void main(String[] args) throws Exception { //调用run方法 Configuration conf = new Configuration(); int status = ToolRunner.run(conf, new FlowMr1(), args); System.exit(status); } public static class FlowMapper extends Mapper<LongWritable, Text,Text, FlowBean1>{ private Text outputKey = new Text(); private FlowBean1 outputValue = new FlowBean1(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //分割 String[] items = value.toString().split("\t"); //先做过滤 if(items.length >= 11){ //合法的数据有多少 context.getCounter("userlog","legal line").increment(1L); this.outputKey.set(items[1]);//将手机号作为key this.outputValue.setAll(Long.valueOf(items[6]),Long.valueOf(items[7]),Long.valueOf(items[8]),Long.valueOf(items[9])); //输出 context.write(this.outputKey,this.outputValue); }else{ //不合法的数据有多少 context.getCounter("userlog","illegal line").increment(1L); return;//如果 不合法,直接return,不处理该条数据,直接取下一条 } } } public static class FlowReduce extends Reducer<Text, FlowBean1,Text, FlowBean1>{ private FlowBean1 outputValue = new FlowBean1(); @Override protected void reduce(Text key, Iterable<FlowBean1> values, Context context) throws IOException, InterruptedException { long sumUpPack = 0; long sumDownPack = 0; long sumUpFlow = 0; long sumDownFlow = 0; for (FlowBean1 value : values) { sumUpPack += value.getUpPack(); sumDownPack += value.getDownPack(); sumUpFlow += value.getUpFlow(); sumDownFlow += value.getDownFlow(); } this.outputValue.setAll(sumUpPack,sumDownPack,sumUpFlow,sumDownFlow); //输出 context.write(key,outputValue); } } }
-
-
3、需求2的实现
-
第一步:看结果
手机号 上行总包 下行总包 上行总流量 下行总流量
-
第二步:有没有分组或者排序
- 排序:上行包总和,key中必须包含上行包总和
- key:将五个字段都作为key中内容
-
第三步:分析value
- 为NullWritable
-
第四步:分析
- Input:读上个程序的结果
- Map:
- 处理逻辑
- 分割每一行的内容放入自定义数据类型
- key:整条数据
- value:null
- 处理逻辑
- Shuffle
- 排序:调用compareTo,按照上行总包进行降序排序
- 分组:不需要分组
- Reduce:没有reduce
- Output
-
实现
-
自定义数据类型的实现
/** * 流量案例1的自定义数据类型 */ public class FlowBean2 implements WritableComparable<FlowBean2> { private String phone; private long upPack; private long downPack; private long upFlow; private long downFlow; public FlowBean2() { } public void setAll(String phone,long upPack, long downPack, long upFlow, long downFlow) { this.setPhone(phone); this.setUpPack(upPack); this.setDownPack(downPack); this.setUpFlow(upFlow); this.setDownFlow(downFlow); } public String getPhone() { return phone; } public void setPhone(String phone) { this.phone = phone; } public long getUpPack() { return upPack; } public void setUpPack(long upPack) { this.upPack = upPack; } public long getDownPack() { return downPack; } public void setDownPack(long downPack) { this.downPack = downPack; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } @Override public void write(DataOutput out) throws IOException { out.writeUTF(this.phone); out.writeLong(this.upPack); out.writeLong(this.downPack); out.writeLong(this.upFlow); out.writeLong(this.downFlow); } @Override public void readFields(DataInput in) throws IOException { this.phone = in.readUTF(); this.upPack = in.readLong(); this.downPack = in.readLong(); this.upFlow = in.readLong(); this.downFlow = in.readLong(); } @Override public String toString() { return this.phone+"\t"+this.upPack+"\t"+this.downPack+"\t"+this.upFlow+"\t"+this.downFlow; } @Override public int compareTo(FlowBean2 o) { //按照上行总包数进行排序 return -Long.valueOf(this.getUpPack()).compareTo(Long.valueOf(o.getUpPack())); } } -
mr实现
/** * 实现流量案例的需求2 */ public class FlowMr2 extends Configured implements Tool { //构建一个job,配置job,提交运行job @Override public int run(String[] args) throws Exception { //构建 Job job = Job.getInstance(this.getConf(),"flow1"); job.setJarByClass(FlowMr2.class); //配置 Path inputPath = new Path("datas/output/flow/flow1"); TextInputFormat.setInputPaths(job,inputPath); job.setMapperClass(FlowMapper.class); job.setMapOutputKeyClass(FlowBean2.class); job.setMapOutputValueClass(NullWritable.class); // job.setReducerClass(FlowReduce.class); // job.setOutputKeyClass(Text.class); // job.setOutputValueClass(FlowBean1.class); job.setNumReduceTasks(1); Path outputPath = new Path("datas/output/flow/flow2"); TextOutputFormat.setOutputPath(job,outputPath); //提交 return job.waitForCompletion(true) ? 0 : -1; } //作为程序的入口 public static void main(String[] args) throws Exception { //调用run方法 Configuration conf = new Configuration(); int status = ToolRunner.run(conf, new FlowMr2(), args); System.exit(status); } public static class FlowMapper extends Mapper<LongWritable, Text, FlowBean2, NullWritable>{ private FlowBean2 outputKey = new FlowBean2(); private NullWritable outputValue = NullWritable.get(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //分割 String[] items = value.toString().split("\t"); //先做过滤 if(items.length == 5){ //合法的数据有多少 context.getCounter("userlog","legal line").increment(1L); //将五个字段封装作为key this.outputKey.setAll(items[0],Long.valueOf(items[1]),Long.valueOf(items[2]),Long.valueOf(items[3]),Long.valueOf(items[4])); //输出 context.write(this.outputKey,this.outputValue); }else{ //不合法的数据有多少 context.getCounter("userlog","illegal line").increment(1L); return;//如果 不合法,直接return,不处理该条数据,直接取下一条 } } } public static class FlowReduce extends Reducer<Text, FlowBean1,Text, FlowBean1>{ private FlowBean1 outputValue = new FlowBean1(); @Override protected void reduce(Text key, Iterable<FlowBean1> values, Context context) throws IOException, InterruptedException { long sumUpPack = 0; long sumDownPack = 0; long sumUpFlow = 0; long sumDownFlow = 0; for (FlowBean1 value : values) { sumUpPack += value.getUpPack(); sumDownPack += value.getDownPack(); sumUpFlow += value.getUpFlow(); sumDownFlow += value.getDownFlow(); } this.outputValue.setAll(sumUpPack,sumDownPack,sumUpFlow,sumDownFlow); //输出 context.write(key,outputValue); } } }
-
4、需求3的实现:
-
基于第一个程序的结果,将数据写入不同的文件
-
第一步:看结果
手机号 上行总包 下行总包 上行总流量 下行总流量
-
第二步:有没有排序和分组:没有,是以一对一的关系,只有分区
-
实现
-
自定义分区
/** 自定义分区规则 */ public class FlowParitioner extends Partitioner<FlowBean2, NullWritable> { @Override public int getPartition(FlowBean2 key, NullWritable value, int numPartitions) { //所有134开头写入分区0 //135,136写入分区1 //其他写入分区2 String phone = key.getPhone(); if(phone.startsWith("134")){ return 0; }else if(phone.startsWith("135") || phone.startsWith("136")){ return 1; }else return 2; } }
-
-
mr的实现
/**
实现流量案例的需求3
*/
public class FlowMr3 extends Configured implements Tool {
//构建一个job,配置job,提交运行job
@Override
public int run(String[] args) throws Exception {
//构建
Job job = Job.getInstance(this.getConf(),"flow3");
job.setJarByClass(FlowMr3.class);
//配置
Path inputPath = new Path("datas/output/flow/flow1");
TextInputFormat.setInputPaths(job,inputPath);
job.setMapperClass(FlowMapper.class);
job.setMapOutputKeyClass(FlowBean2.class);
job.setMapOutputValueClass(NullWritable.class);
job.setPartitionerClass(FlowParitioner.class);
job.setReducerClass(FlowReduce.class);
job.setOutputKeyClass(FlowBean2.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(3);
Path outputPath = new Path("datas/output/flow/flow3");
TextOutputFormat.setOutputPath(job,outputPath);
//提交
return job.waitForCompletion(true) ? 0 : -1;
}
//作为程序的入口
public static void main(String[] args) throws Exception {
//调用run方法
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new FlowMr3(), args);
System.exit(status);
}
public static class FlowMapper extends Mapper<LongWritable, Text, FlowBean2, NullWritable>{
private FlowBean2 outputKey = new FlowBean2();
private NullWritable outputValue = NullWritable.get();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//分割
String[] items = value.toString().split("\t");
//先做过滤
if(items.length == 5){
//合法的数据有多少
context.getCounter("userlog","legal line").increment(1L);
//将五个字段封装作为key
this.outputKey.setAll(items[0],Long.valueOf(items[1]),Long.valueOf(items[2]),Long.valueOf(items[3]),Long.valueOf(items[4]));
//输出
context.write(this.outputKey,this.outputValue);
}else{
//不合法的数据有多少
context.getCounter("userlog","illegal line").increment(1L);
return;//如果 不合法,直接return,不处理该条数据,直接取下一条
}
}
}
public static class FlowReduce extends Reducer<FlowBean2, NullWritable,FlowBean2, NullWritable>{
@Override
protected void reduce(FlowBean2 key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//没有聚合逻辑,直接输出
context.write(key,NullWritable.get());
}
}
}
六、Shuffle过程初探
1、Shuffle的设计目的
-
基于统计的思想来设计的
-
以SQL的应用为原型
select 1 from 2 where 3 group by 4 having 5 order by 6 limit 7 1-代表列的过滤,就是结果 2-代表数据源:从某张表或者某张临时表中查询 3-代表行的过滤 4-按什么分组 5-对分组后的行进行过滤 6-用于排序 7-限制输出
2、Shuffle的功能
- 分区:为了多进程并行
- 默认reduce只有1个,如果Map输出的数据非常的大,一个Reduce的负载就很高,效率很低
- 决定了当前的每一条数据归哪个reduce进行处理
- 排序:符合统计分析的过程
- 分组:符合统计分析的过程
3、Shuffle的基本过程
-
Map:在Map阶段对每条数据调用map方法之后,所有数据进入Map端的shuffle阶段
-
Shuffle
-
Map端的Shuffle
- 排序
-
Reduce端的shuffle
-
分组
-
hadoop 1 hadoop 1 hive 1 hbase 1 hive 1 spark 1 hue 1 不排序直接分组: hadoop:1,1 每一组的比较次数:N-1 hadoop 1 hadoop 1 hive 1 hive 1 hbase 1 spark 1 hue 1 排序以后分组 hadoop:1,1 2
-
-
-
Reduce:在Reduce 阶段对每条数据调用 reduce方法之前,数据在进行分组排序等操作为Reduce端的shuffle

