为了演示集群的效果,这里准备一台虚拟机(window 7),在虚拟机中搭建了单IP多节点的zookeeper集群(多IP节点的也是同理的),并且在本机(win 7)和虚拟机中都安装了kafka。
前期准备说明:
1.三台zookeeper服务器,本机安装一个作为server1,虚拟机安装两个(单IP)
2.三台kafka服务器,本机安装一个作为server1,虚拟机安装两个。
备注:当然你可以直接在虚拟机上安装三个服务器分别为server1、server2、server3 。
- 虚拟机和本机网络环境
1.将虚拟机的网络模式调整为桥接模式,将虚拟机的防火墙功能关闭;
2.将主机的防火墙也关闭。
3.互相ping,测试是否能正常连接.。
- 下载kafka
从Kafka官网http://kafka.apache.org/downloads下载Kafka安装包。(要下载Binary downloads这个类型,不要下载源文件,方便使用)
- 下载zookeeper
从zookeeper官网http://zookeeper.apache.org/releases.html下载zookeeper安装包。
- 下载JDK
从官网http://www.java.com/download/下载(建议下载Oracle官方发布的Java),,配置环境变量。
zookeeper集群环境搭建
本机配置
修改本机sever1的zoo.cfg文件配置:
#存储内存中数据库快照的位置,如果不设置参数,更新事务日志将被存储到默认位置。 #dataDir=/tmp/zookeeper dataDir=D:/bigData/zookeeper-3.4.10/data #日志文件的位置 dataLogDir=D:/bigData/zookeeper-3.4.10/zlog #监听端口 clientPort=2181 #集群服务器配置 server.1=192.168.1.130:9000:7000 server.2=192.168.1.103:9001:7001 server.3=192.168.1.103:9002:7002
格式: server.A = B:C:D
A:是一个数字,表示第几号服务器
B:服务器IP地址
C:是一个端口号,用来集群成员的信息交换,表示这个服务器与集群中的leader服务器交换信息的端口
D:是在leader挂掉时专门用来进行选举leader所用的端口
完整配置文件如下:


# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. #dataDir=/tmp/zookeeper dataDir=D:/bigData/zookeeper-3.4.10/data dataLogDir=D:/bigData/zookeeper-3.4.10/zlog # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=192.168.1.130:9000:7000 server.2=192.168.1.101:9001:7001 server.3=192.168.1.101:9002:7002
创建serverID
在zoo.cfg配置文件中dataDir目录中新建一个没有后缀的myid文件,里边写1。
虚拟机配置
将本机的zookeeper安装包拷贝到虚拟机上,然后在盘中新建两个目录,server2,server3目录。
修改server2的zoo.cfg配置文件:
#存储内存中数据库快照的位置,如果不设置参数,更新事务日志将被存储到默认位置。 #dataDir=/tmp/zookeeper dataDir=E:/bigData/server2/zookeeper-3.4.10/data #日志文件的位置 dataLogDir=E:/bigData/server2/zookeeper-3.4.10/zlog #监听端口 clientPort=2182 #集群服务器配置 server.1=192.168.1.130:9000:7000 server.2=192.168.1.103:9001:7001 server.3=192.168.1.103:9002:7002
创建SeverID
在zoo.cfg配置文件中dataDir目录中新建一个没有后缀的myid文件,里边写2。
同理配置server3中的zookeeper,这样zookeeper集群的配置工作已经完成。
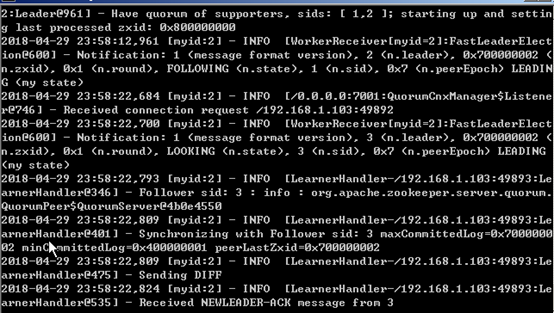
下面我们启动zookeeper集群:一个一个启动每一个zookeeper服务器:
先后进入每一个zookeeper服务器的bin目录下执行zkserver.cmd,在先启动的zookeeper会打印其他zookeeper服务器未启动的错误信息,直至到最后一个启动的时候就没有异常信息了。正常界面:
zookeeper集群环境搭建遇到问题总结:
- zookeeper启动时报Cannot open channel to X at election address Error contacting service. It is probably not running.
解决方法:
a. 关闭所有服务器防火墙
b. 将本服务器的IP修改成0.0.0.0
例如:server.1=0.0.0.0:9000:7000
Kafka集群环境搭建:
下载kafka后解压到某个目录,然后修改server.properties配置。
server.properties修改说明:
broker.id=0 • 在kafka这个集群中的唯一标识,且只能是正整数 port=9091 • 该服务监听的端口 host.name=192.168.1.130 • broker 绑定的主机名称(IP) 如果不设置将绑定所有的接口。 advertised.host.name=192.168.1.130 • broker服务将通知消费者和生产者 换言之,就是消费者和生产者就是通过这个主机(IP)来进行通信的。如果没有设置就默认采用host.name。 num.network.threads=2 • broker处理消息的最大线程数,一般情况是CPU的核数 num.io.threads=8 • broker处理IO的线程数 一般是num.network.threads的两倍 socket.send.buffer.bytes=1048576 • socket发送的缓冲区。socket调优参数SO_SNDBUFF socket.receive.buffer.bytes=1048576 • socket接收的缓冲区 socket的调优参数SO_RCVBUF socket.request.max.bytes=104857600 • socket请求的最大数量,防止serverOOM。 log.dirs=\logs • kafka数据的存放地址,多个地址的话用逗号隔开。多个目录分布在不同的磁盘上可以提高读写性能 num.partitions=2 • 每个tipic的默认分区个数,在创建topic时可以重新制定 log.retention.hours=168 • 数据文件的保留时间 log.retention.minutes也是一个道理。 log.segment.bytes=536870912 • topic中的最大文件的大小 -1表示没有文件大小限制 log.segment.bytes 和log.retention.minutes 任意一个 达到要求 都会删除该文件 在创建topic时可以重新制定。若没有.则选取该默认值 log.retention.check.interval.ms=60000 • 文件大小检查的周期时间,是否处罚 log.cleanup.policy中设置的策略 log.cleaner.enable=false • 是否开启日志清理 zookeeper.connect=192.168.1.130:num1,192.168.1.130:num2,192.168.1.130:num3 • 上面我们的Zookeeper集群 zookeeper.connection.timeout.ms=1000000 • 进群链接时间超时
本机配置
修改本机server1的server.properties配置:
#在kafka这个集群中的唯一标识,且只能是正整数 broker.id=0 # kafka集群的地址 broker.list=192.168.0.130:9092,192.168.0.103:9093,192.168.0.103:9094 #listener and port port=9092 #broker 绑定的主机名称(IP) 如果不设置将绑定所有的接口。 host.name=192.168.1.130 #kafka数据的存放地址,多个地址的话用逗号隔开。多个目录分布在不同的磁盘上可以提高读写性能 # A comma separated list of directories under which to store log files #log.dirs=/tmp/kafka-logs log.dirs=D:/bigData/kafka_2.11-1.1.0/kafka-logs #每个tipic的默认分区个数,在创建topic时可以重新制定 num.partitions=3 # root directory for all kafka znodes. zookeeper.connect=192.168.1.130:2181,192.168.1.103:2182,192.168.1.103:2183
虚拟机配置
将本机的kafka安装包拷贝到虚拟机上,存放在server2,server3目录。
注意:若本机拷贝到虚拟机中kafka之前有使用过,生成过topics,直接拷贝搭建集群,启动kafka时会报如下错误:
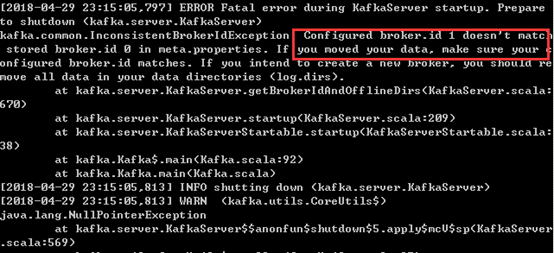
原因:在单点环境下创建的topic中,kafka服务器的broker.id为0,在搭建集群时修改了borker.id,先前创建的topic就无法找到对应的broker.id。
解决办法:删除原来的topic信息。
修改server2目录中kafka配置:
#在kafka这个集群中的唯一标识,且只能是正整数 broker.id=1 # kafka集群的地址 broker.list=192.168.0.130:9092,192.168.0.103:9093,192.168.0.103:9094 #listener and port port=9093 #broker 绑定的主机名称(IP) 如果不设置将绑定所有的接口。 host.name=192.168.1.103 #kafka数据的存放地址,多个地址的话用逗号隔开。多个目录分布在不同的磁盘上可以提高读写性能 # A comma separated list of directories under which to store log files #log.dirs=/tmp/kafka-logs log.dirs=D:/bigData/server2/kafka_2.11-1.1.0/kafka-logs #每个tipic的默认分区个数,在创建topic时可以重新制定 num.partitions=3 # root directory for all kafka znodes. zookeeper.connect=192.168.1.130:2181,192.168.1.103:2182,192.168.1.103:2183
同理修改server3中的kafka配置,配置好之后,kafka集成环境已经配置完成,下面我们来验证下集成环境是否OK。
验证集群环境
依次先启动zookeeper服务器
进入zookeeper的bin目录,执行zkServer.cmd
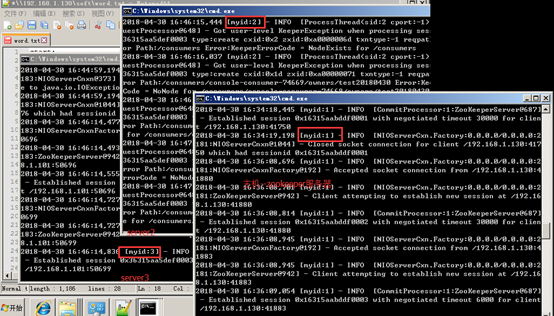
依次启动kafka服务器
进入kafka安装目录D:\bigData\kafka_2.11-1.1.0,按下shift+鼠标右键,选择"在此处打开命令窗口",打开命令行,在命令行中输入:.\bin\windows\kafka-server-start.bat .\config\server.properties回车。正常启动界面如图:
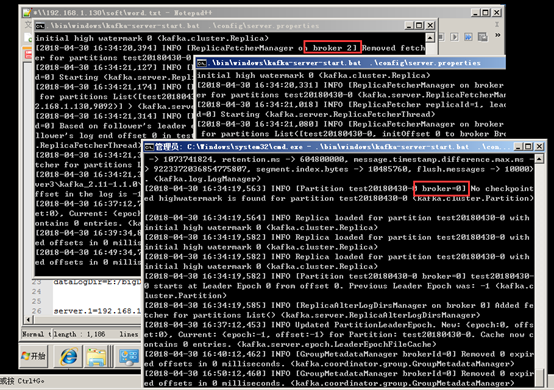
在主机kafka服务器创建topic
主要参数说明:
partitions分区数
(1). partitions :分区数,控制topic将分片成多少个log。可以显示指定,如果不指定则会使用broker(server.properties)中的num.partitions配置的数量
(2). 虽然增加分区数可以提供kafka集群的吞吐量、但是过多的分区数或者或是单台服务器上的分区数过多,会增加不可用及延迟的风险。因为多的分区数,意味着需要打开更多的文件句柄、增加点到点的延时、增加客户端的内存消耗。
(3). 分区数也限制了consumer的并行度,即限制了并行consumer消息的线程数不能大于分区数
(4). 分区数也限制了producer发送消息是指定的分区。如创建topic时分区设置为1,producer发送消息时通过自定义的分区方法指定分区为2或以上的数都会出错的;这种情况可以通过alter –partitions 来增加分区数。
replication-factor副本
1. replication factor 控制消息保存在几个broker(服务器)上,一般情况下等于broker的个数。
2. 如果没有在创建时显示指定或通过API向一个不存在的topic生产消息时会使用broker(server.properties)中的default.replication.factor配置的数量。
创建Topic
1. 创建主题,命名为"test20180430",replicationfactor=3(因为这里有三个kafka服务器在运行)。可根据集群中kafka服务器个数来修改replicationfactor的数量,以便提高系统容错性等。
2. 在D:\bigData\kafka_2.11-1.1.0\bin\windows目录下打开新的命令行,输入命令:kafka-topics.bat --create --zookeeper 192.168.1.130:2181 --replication-factor 3 --partitions 1 --topic test20180430回车。如图:

查看Topic
kafka-topics.bat --zookeeper 192.168.1.130:2181 --describe --topic test20180430

结果说明:
第一行,列出了topic的名称,分区数(PartitionCount),副本数(ReplicationFactor)以及其他的配置(Config.s)
Leader:1 表示为做为读写的broker的编号
Replicas:表示该topic的每个分区在那些borker中保存
Isr:表示当前有效的broker, Isr是Replicas的子集
创建Producer消息提供者
1. 在D:\bigData\kafka_2.11-1.1.0\bin\windows目录下打开新的命令行,输入命令:kafka-console-producer.bat --broker-list 192.168.1.130:9092,192.168.1.101:9093,192.168.1.101:9094 --topic test20180430 回车。(该窗口不要关闭)

创建Customer消息消费者
1. 在D:\bigData\kafka_2.11-1.1.0\bin\windows目录下打开新的命令行,输入命令:kafka-console-consumer.bat --zookeeper 192.168.1.130:2181 --topic test20180430回车。

以同样的方式,将虚拟机上server2和server3的消息者customer创建,然后通过主机上的producer进行消息发送操作。
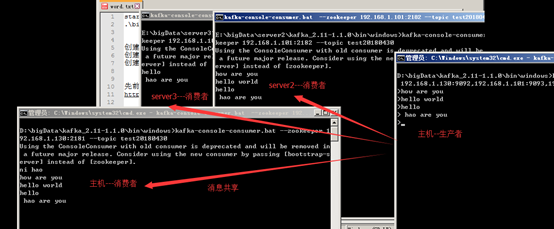
至此,集群环境已经验证OK。
集群容错性
1. 首先查看topic的信息
kafka-topics.bat --list --zookeeper 192.168.1.130:2181
查看指定的topic的详细信息:
kafka-topics.bat --zookeeper 192.168.1.130:2181 --describe --topic test20180430
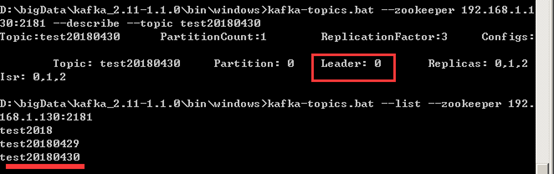
可以看到此时选举的leader是0,即就是虚拟机中的kafka服务器,现在把虚拟机的kafka服务器给干掉。此时leader为变为1,消费者能继续消费。

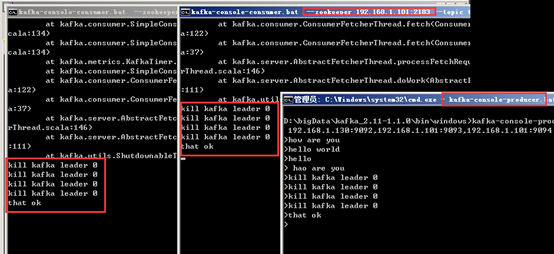
注意:zk的部署个数最好为基数,ZK集群的机制是只要超过半数的节点OK,集群就能正常提供服务。只有ZK节点挂得太多,只剩一半或不到一半节点能工作,集群才失效。