背景
我们的网关采用了Hystrix来向业务方提供的服务发送http请求,之前尝试采用官方的Turbine+HystrixDashboard来监控Hystrix命令和线程池的指标,发现由于默认采集指标数据过多,在并发量比较高的情况下对网关应用Jvm内存和GC影响较大。因此在分析HystrixDashboard的数据采集过程后(相关文章:HystrixMetrics指标采集源码解读),决定自己来实现一套Hystrix指标监控。
根据在网上查找相关资料,我决定采用InfluxDB来存储指标数据,然后使用Grafana构建实时图表进行监控。
- InfluxDB是一个当下比较流行的时序数据库,InfluxDB使用 Go 语言编写,无需外部依赖,安装配置非常方便,适合构建大型分布式系统的监控系统(InfluxDB官网)
- Grafana是一个开源的度量分析与可视化套件。经常被用作基础设施的时间序列数据和应用程序分析的可视化。支持许多不同的数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等(grafana官网)
最终效果
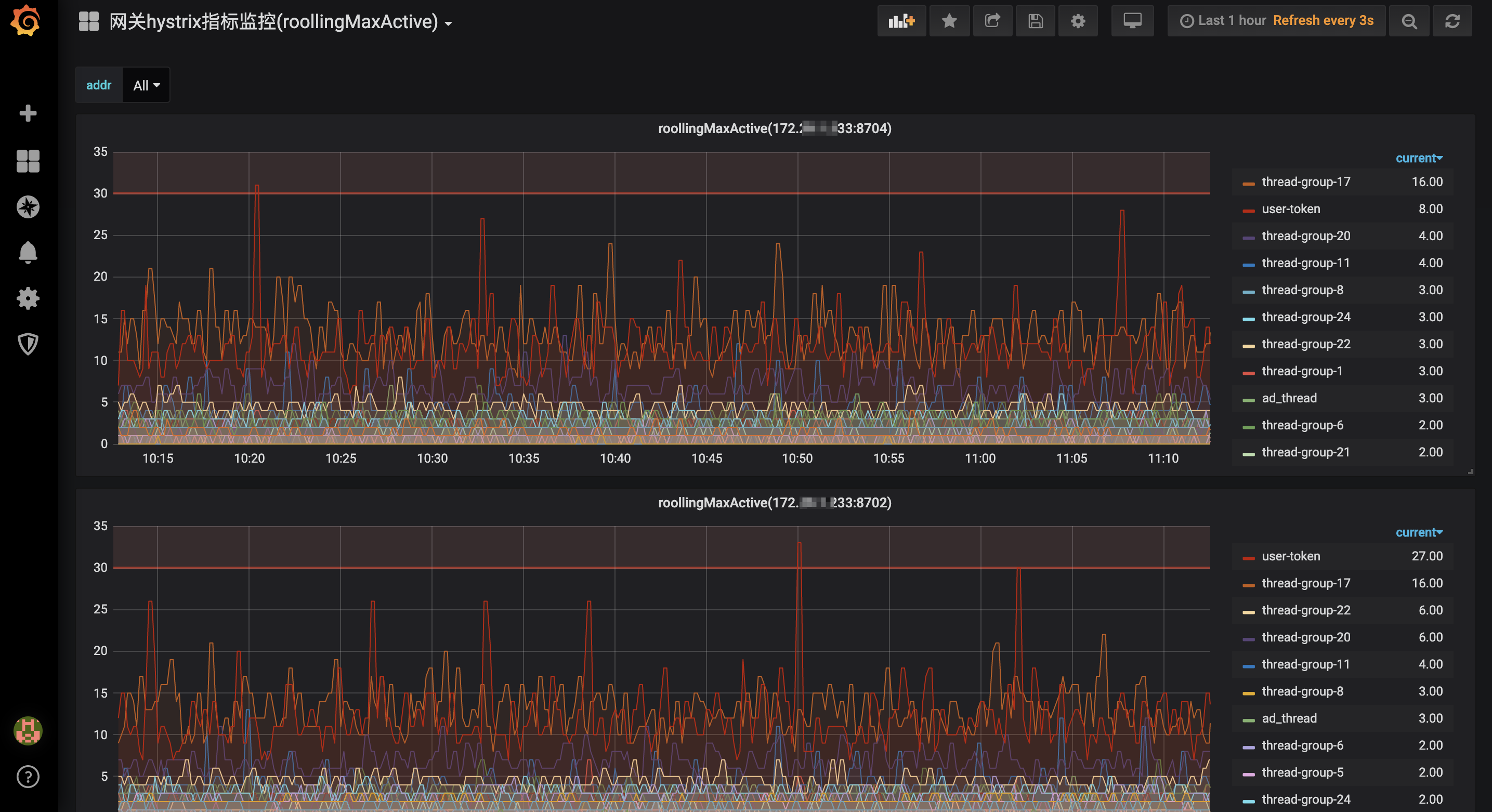
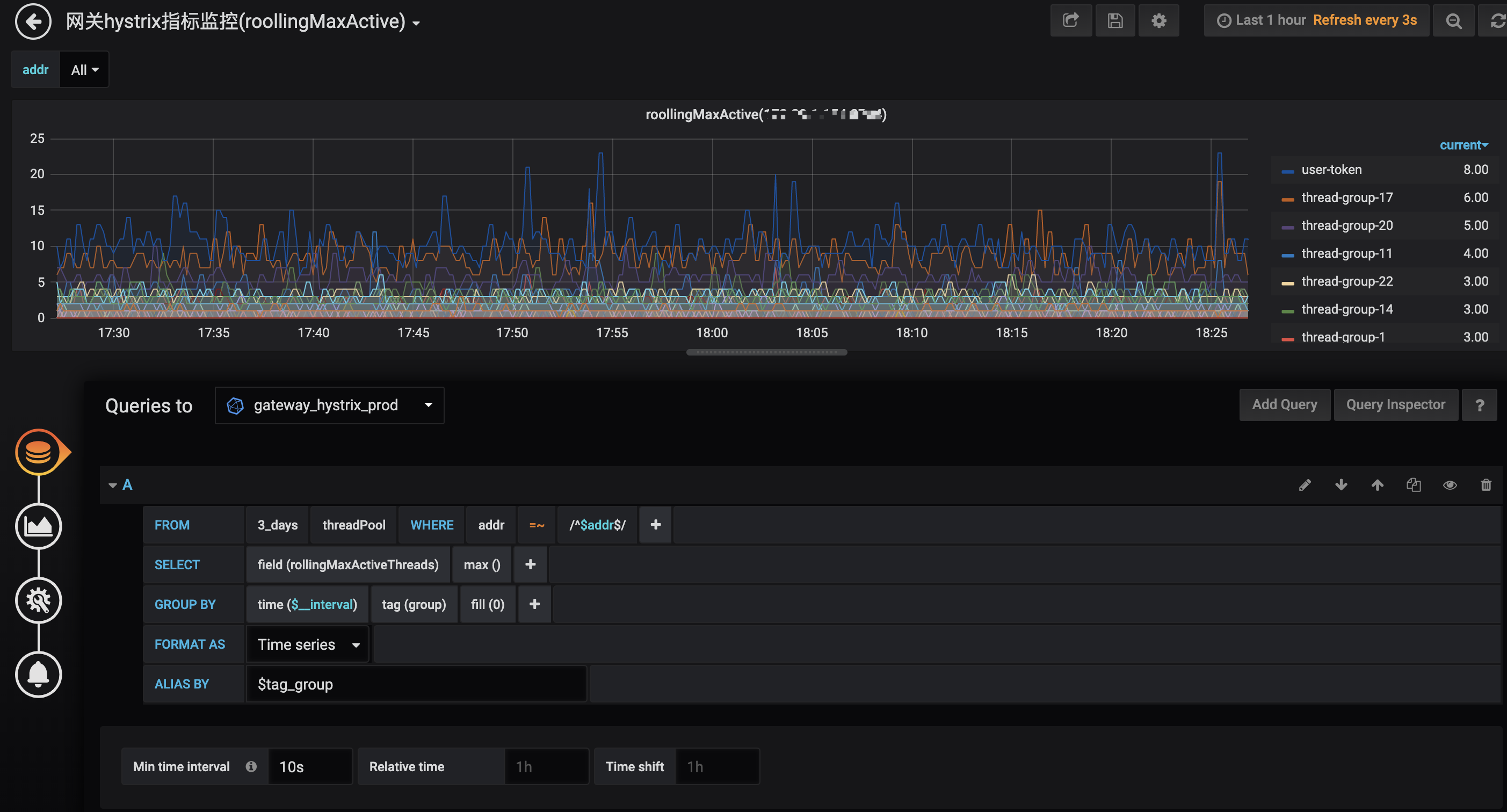
先提前看下效果图(以Hystrix线程池的rollingMaxActiveThreads指标数据为例),可查看每台网关实例的各个线程池组当前窗口期最大并发线程,用来关注不同业务服务的实时调用量,便于后续调整线程池大小及超时时间:
一、部署InfluxDB、Grafana
这里以CentOS系统下的yum安装为例,便于快速部署,其他下载安装方式参考官网:
1. 安装InfluxDB
# 1. 下载安装包
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.7.6.x86_64.rpm
# 2. 使用yum安装
sudo yum localinstall influxdb-1.7.6.x86_64.rpm
# 3. 启动服务(默认使用8086端口)
service influxdb start
2. 安装Grafana
# 1. 下载安装包
wget https://dl.grafana.com/oss/release/grafana-6.2.0-1.x86_64.rpm
# 2. 使用yum安装
sudo yum localinstall grafana-6.2.0-1.x86_64.rpm
# 3. 启动服务(默认使用3000端口)
service grafana-server start
二、上报指标数据
1.引入InfluxDB的java client依赖:
<dependency>
<groupId>org.influxdb</groupId>
<artifactId>influxdb-java</artifactId>
<version>2.15</version>
</dependency>
2.InfluxDB数据库配置
# 数据库地址、用户名、密码
influxDB.serverAddr=http://172.xx.xx.xx:8086
influxDB.username=root
influxDB.password=root
# 库名
influxDB.dataBase=gateway_hystrix_test
# 数据保留策略名
influxDB.retentionPolicyName=3_days
# 数据保留策略,3d:保留3天
influxDB.retentionPolicy=3d
创建并初始化InfluxDB实例,后续通过引入InfluxDB对象来进行相关数据库操作(类SQL语句):
@Configuration
public class InfluxDbConfig {
@Value("${influxDB.serverAddr}")
private String serverAddr;
@Value("${influxDB.username}")
private String username;
@Value("${influxDB.password}")
private String password;
@Value("${influxDB.dataBase}")
private String dataBase;
@Value("${influxDB.retentionPolicyName}")
private String retentionPolicyName;
@Value("${influxDB.retentionPolicy}")
private String retentionPolicy;
@Bean
public InfluxDB influxDB() {
// 连接influxDB数据库
InfluxDB influxDB = InfluxDBFactory.connect(serverAddr, username, password);
// 创建数据库
influxDB.query(new Query("CREATE DATABASE " + dataBase));
influxDB.setDatabase(dataBase);
// 创建数据保留策略
influxDB.query(new Query("CREATE RETENTION POLICY \"" + retentionPolicyName + "\" ON \"" + dataBase
+ "\" DURATION " + retentionPolicy + " REPLICATION 1 DEFAULT"));
influxDB.setRetentionPolicy(retentionPolicyName);
return influxDB;
}
}
3. 采集并上报指标数据
通过@Scheduled每秒上报,这里只采集了HystrixThreadPool指标,如果有额外的需求,还可以通过HystrixCommandMetrics、HystrixCollapserMetrics来获取其他Hystrix指标数据:
- HystrixCommandMetrics:获取Hystrix命令执行情况(成功/失败)
- HystrixThreadPoolMetrics:获取Hystrix线程池指标
- HystrixCollapserMetrics:获取Hystrix合并命令执行情况
@Component
public class HystrixMetricRecorder {
private static final Logger logger = LoggerFactory.getLogger(HystrixMetricRecorder.class);
private String host;
@Value("${server.port}")
private int port;
@Autowired
private InfluxDB influxDB;
@PostConstruct
public void init() {
try {
host = InetAddress.getLocalHost().getHostAddress();
} catch (Exception e) {
logger.error("get host&port error", e);
}
}
@Scheduled(fixedRate = 1000)
public void threadPoolMetricsRecord() {
// 获取Hystrix线程池指标数据(Hystrix自动收集的)
Collection<HystrixThreadPoolMetrics> threadPoolMetrics = HystrixThreadPoolMetrics.getInstances();
for (HystrixThreadPoolMetrics threadPoolMetric : threadPoolMetrics) {
// 线程池组名
String groupName = threadPoolMetric.getThreadPoolKey().name();
// 当前活跃线程数
int currentActive = threadPoolMetric.getCurrentActiveCount().intValue();
// 当前线程池大小
int currentPoolSize = threadPoolMetric.getCurrentPoolSize().intValue();
// 窗口期(默认最近10s)最大并发线程数
long rollingMaxActiveThreads = threadPoolMetric.getRollingMaxActiveThreads();
// 窗口期(默认最近10s)线程拒绝数
long rollingCountThreadsRejected = threadPoolMetric.getRollingCountThreadsRejected();
/*
measurement相当于表名
tag是用于统计或分类的参数,这里用ip+端口进行标记,用于后续图表展示
field相当于列,存储各类指标值
*/
influxDB.write(Point.measurement("threadPool")
.time(System.currentTimeMillis(), TimeUnit.MILLISECONDS)
.tag("host", host)
.tag("port", port + "")
.tag("addr", host + ":" + port)
.tag("group", groupName)
.addField("currentActive", currentActive)
.addField("currentPoolSize", currentPoolSize)
.addField("rollingMaxActiveThreads", rollingMaxActiveThreads)
.addField("rollingCountThreadsRejected", rollingCountThreadsRejected).build());
}
}
}
4.检查InfluxDB数据
启动应用,通过http API可以看到相关库和表已经自动创建了
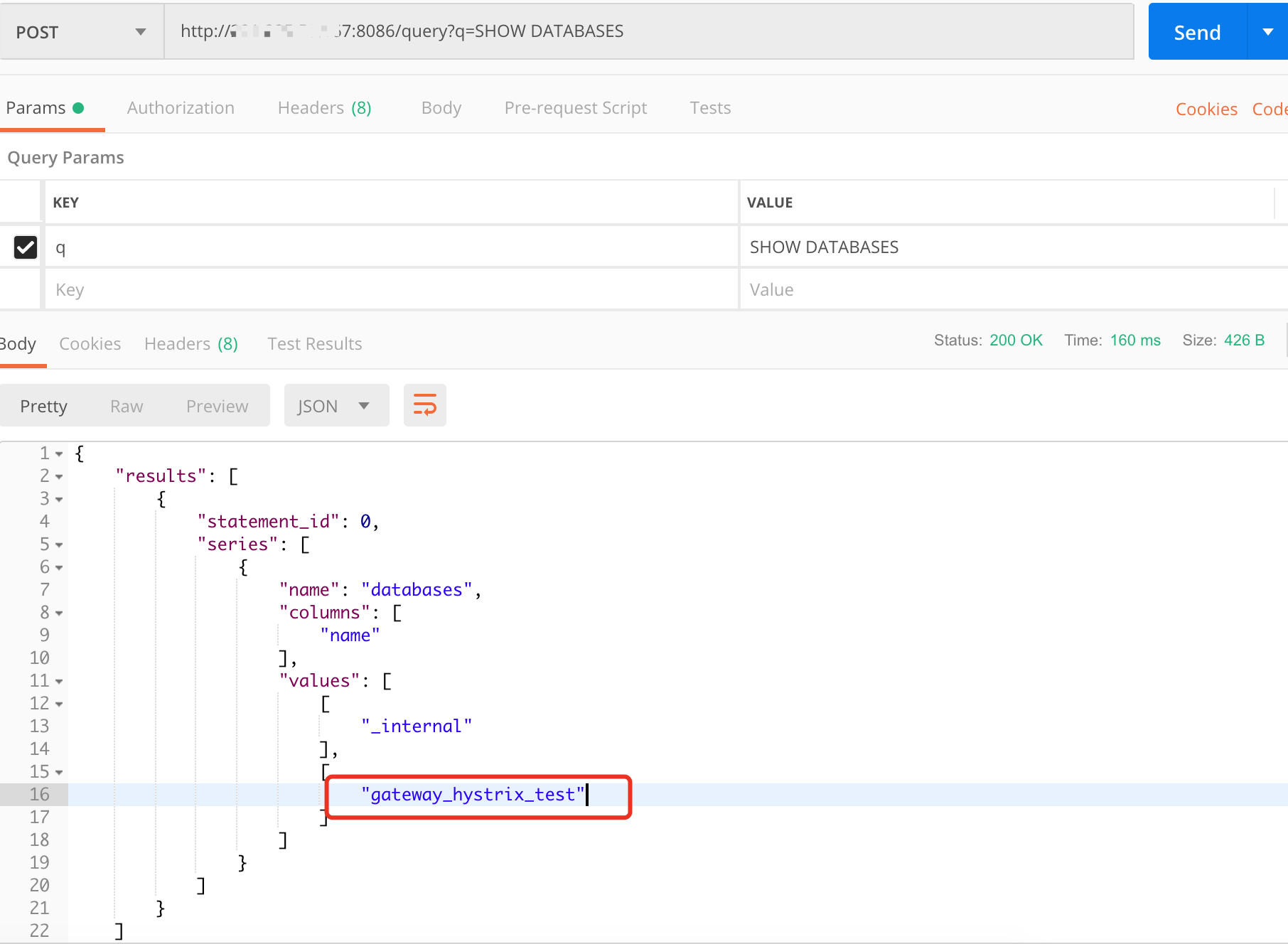
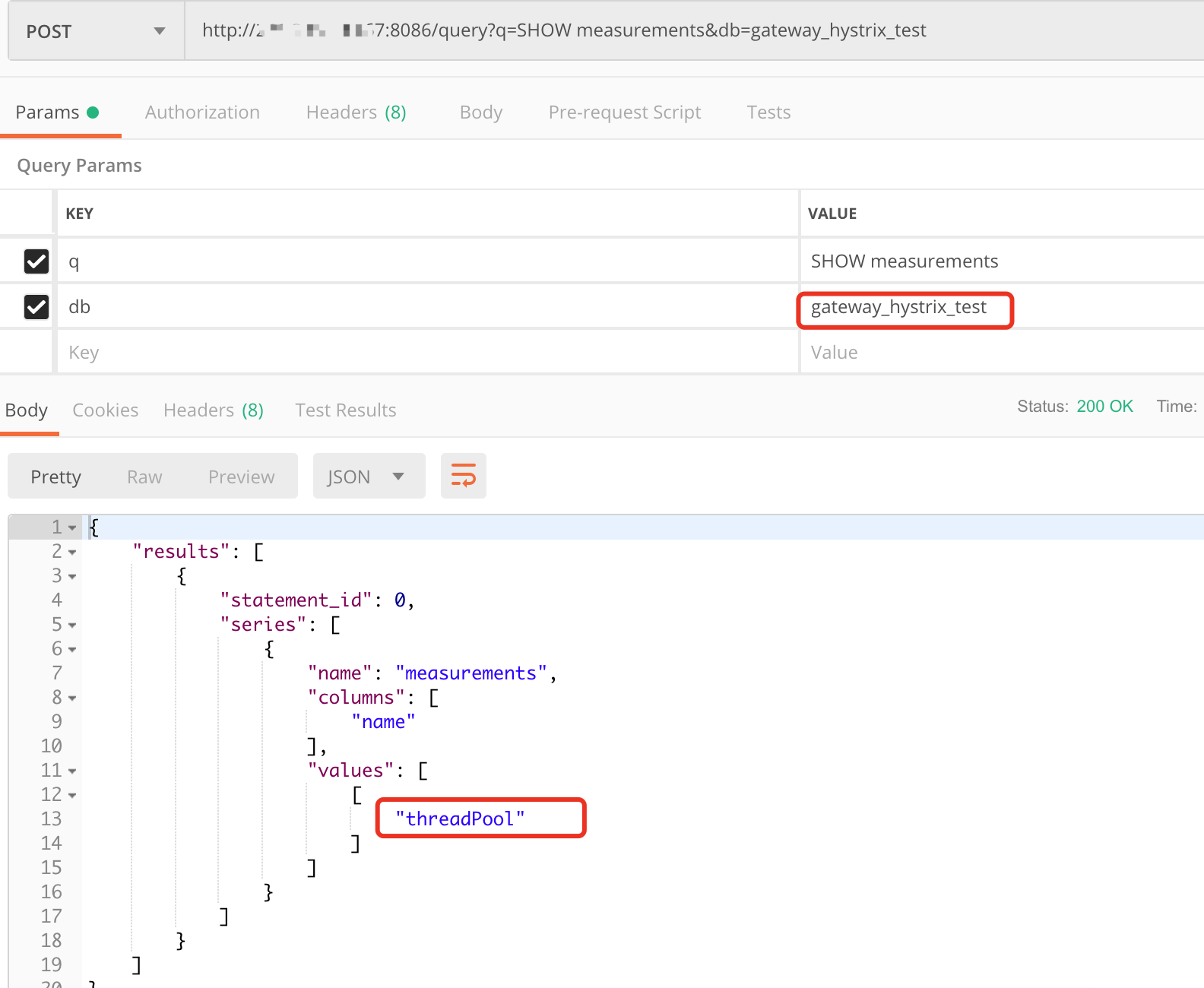
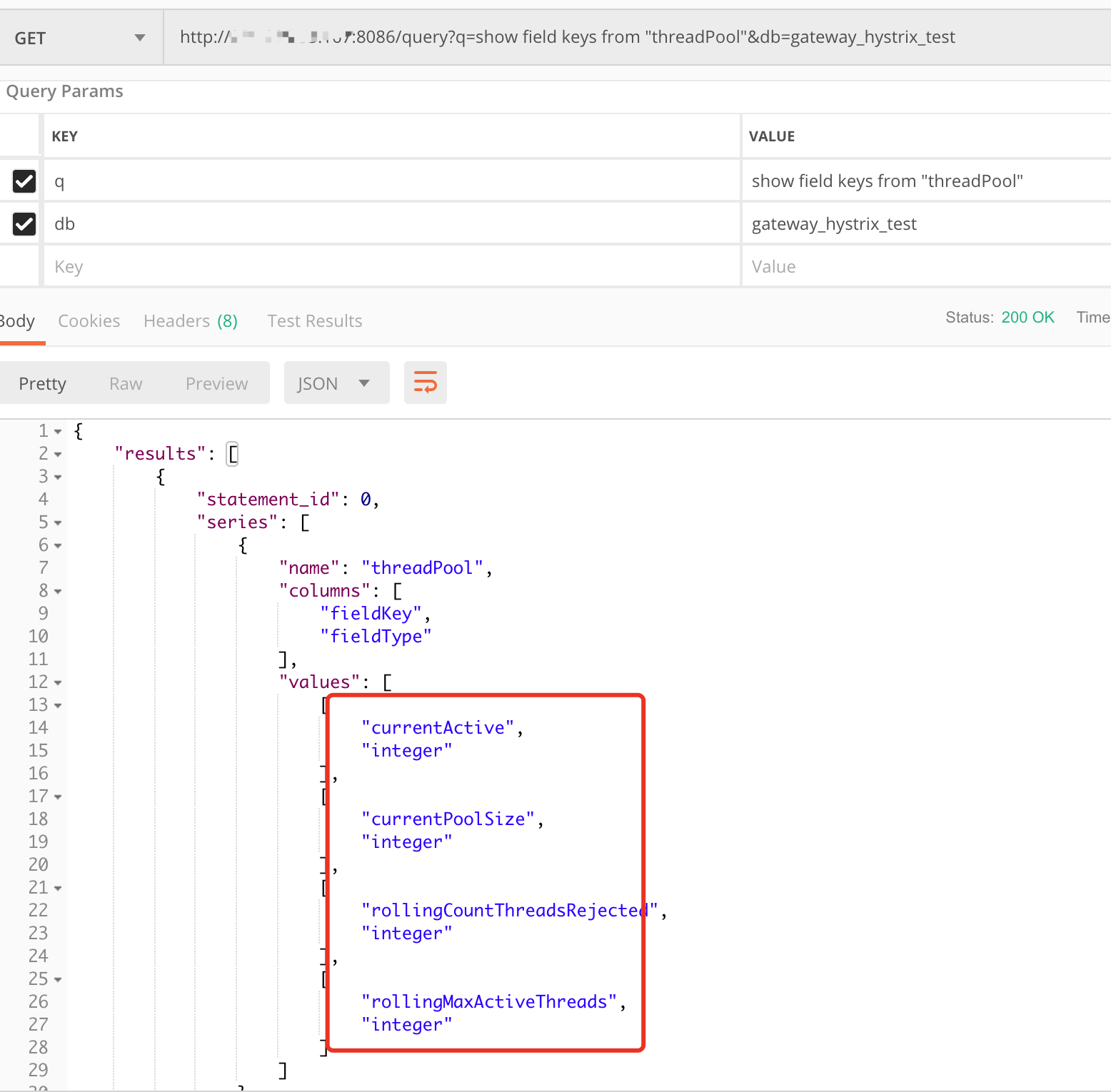
再确认指标数据都已成功上报:
三、配置Grafana数据可视化
Grafana端口为3000,默认用户名、密码都是admin

1.创建数据源
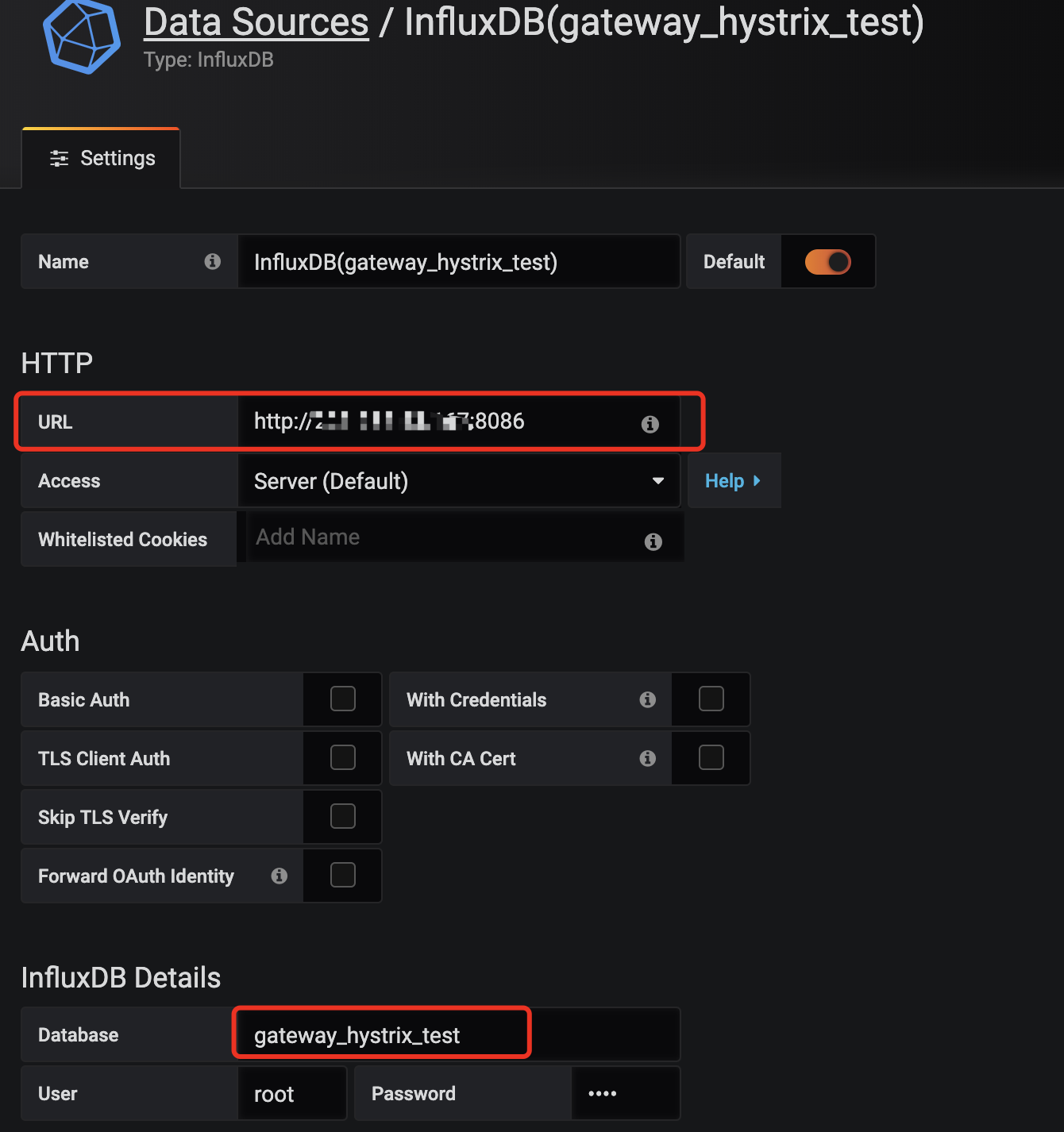
Configuration -> Data Sources -> 选择InfluxDB
根据自己InfluxDB的部署参数来配置数据源
2.创建Panel

3.配置数据查询
首先创建一个动态变量addr,这个是根据上报数据的tag=addr(ip+端口)来查询的,用于后面自动分组展示数据。

然后就是通过设置具体的数据展示参数:
- 选择db=threadPool,retentionPolicy=3_days
- 设置动态分组条件,将tag addr的值设置条件 = 变量$addr
- 选择需要展示的字段值:rollingMaxActiveThreads,取最大值
- 按时间和tag分组,并将无上报的时间点填充值为0
-
配置Repeating:选择addr,这样可以根据ip和端口的不同自动创建多个图表

配置全部完成,就可以通过选择时间区间段和刷新频率,来查看自己的监控图表啦。
总结
其实通过InfluxDB+Grafana监控服务器指标或Jvm指标等通用指标数据的教程有很多,这里主要是帮助大家如何通过InfluxDB的java客户端来上报自定义的指标数据,可以是文中的Hystrix的线程执行指标,也可以是各类业务指标。总之,最终目的就是希望通过可视化的界面,来快速掌握分析应用的运行状况,来进行实时监控乃至后续的优化,希望这篇文章能帮到你。
