1. 简介
大多数搜索引擎应用都必须具有某种搜索功能,问题是搜索功能往往是巨大的资源消耗并且它们由于沉重的数据库加载而拖垮你的应用的性能。
这就是为什么转移负载到一个外部的搜索服务器是一个不错的主意,Apache Solr是一个流行的开源搜索服务器,它通过使用类似REST的HTTP API,这就确保你能从几乎任何编程语言来使用solr。
Solr是一个开源搜索平台,用于构建搜索应用程序。 它建立在Lucene(全文搜索引擎)之上。 Solr是企业级的,快速的和高度可扩展的。 使用Solr构建的应用程序非常复杂,可提供高性能。
为了在CNET网络的公司网站上添加搜索功能,Yonik Seely于2004年创建了Solr。并在2006年1月,它成为Apache软件基金会下的一个开源项目。并于2016年发布最新版本Solr 6.0,支持并行SQL查询的执行。
Solr可以和Hadoop一起使用。由于Hadoop处理大量数据,Solr帮助我们从这么大的源中找到所需的信息。不仅限于搜索,Solr也可以用于存储目的。像其他NoSQL数据库一样,它是一种非关系数据存储和处理技术。
总之,Solr是一个可扩展的,可部署,搜索/存储引擎,优化搜索大量以文本为中心的数据。
2. Solor的安装
下载地址:http://archive.apache.org/dist/lucene/solr/
2.1 Windows下Solor的安装
1)解压solor.zip文件
2)复制dist目录下的 solr-4.10.3.war 到tomcat的webapps目录下

3)启动tomcat,得到solor的解压包,如图:

4)关闭tomcat,在solor中添加扩展包
(1)打开solor的解压包——>example——>lib——>ext 下的jar文件,拷贝到solor工程下的WEB-INF\lib目录下
如图:
jar文件所在目录:

拷贝的目标目录:

5)创建一个solorhome。在下载的solor文件中的example\solr目录就是solorhome,所以,我们可以直接将该文件夹拷贝到磁盘的某个位置并改名为solorhome,比方说D盘
例如:

拷贝到D盘

注意:这个solorhome就类似于solor的数据库
6)关联 solr 及 solrhome
在solor工程的web.xml中,有一段被注释了的配置,如图;

该配置就是配置solorhome的配置,放开该配置,并填写正确的路径即可,如图:

7)启动tomcat,访问solor,如图:

说明solor安装成功。
2.2 Linux下Solor的安装
3. 中文分词器——IK Analyzer
下载地址:a2yg
3.1 简介
IK Analyzer 是一个开源的,基亍 java 语言开发的轻量级的中文分词工具包。从 2006年 12 月推出 1.0 版开始, IKAnalyzer 已经推出了 4 个大版本。
最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。从 3.0 版本开始,IK 发展为面向 Java 的公用分词组件,独立亍 Lucene 项目,同时提供了对 Lucene 的默认优化实现。在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化
3.2 IK Analyzer配置
1)解压缩下载好的分析器压缩包,如图:

2)将IKAnalyzer2012FF_u1.jar文件拷贝到solor工程的lib目录下

3)配置扩展词典(mydict.dic)、停用词典(ext_stopword.dic)与分词配置文件IKAnalyzer.cfg.xml
在分词器的解压文件中,将这三个文件拷贝solor工程的WEB-INF下的classes文件夹下
注意:classes文件夹不存在,需要手动创建


(1)IKAnalyzer.cfg.xml
主要配置的是扩展词典和停用词典的位置,我们直接拷贝过去,可以不用修改,如果想换个名称,就需要修改文件名和这个配置文件对应的名称了。
(2)扩展词典mydict.dic
用于添加新出现的词或者自定义的关键词,例如:

(3)停用词词典ext_stopword.dic
用于添加一些不需要搜索或者一些辅助词或者敏感词,例如:

4)将分词器关联配置给solor
修改 solrhome\collection1\conf\schema.xml 文件,配置一个 FieldType,使用 IKAnalyzer
添加如下配置
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
如图:

配置解析:
fieldType标签:表示字段类型每一个字段类型使用一个fieldType标签
name属性:表示该字段类型的名称,名称自定义
class属性:基本类型
analyzer子标签:配置分析器
该配置的含义是,定义一个字段类型text_ik,采用分析器IKAnalyzer进行分词
3.3 在solor中测试
如图:输入武汉肺炎,选择text_ik分词器,点击分析

4. solor的使用
4.1 solor界面功能的简单介绍
4.1.1 core selector
如图:

这个地方就类似于选择数据库操作,这个collection1就是一个数据库,位于solorhome目录下,如图:

选择collection1之后,会出现很多选项菜单,如图:
1)query:用于查询我们所需要的数据
点击query,如图:

点击execute query就是执行查询的意思。
参数含义;
q:查询表达式。 *:* 表示查询所有 第一个*代表字段名称 第二个*代表要查询的条件值
sort:排序字段
start, rows:分页查询 start起始记录数 rows每页显示的条数
4.1.2 Analyse
如图:

该功能是用于对我们所需要搜索的词进行解析并拆分的
例如:输入武汉加油,选择text,点击Analyse values进行分析,得到如下图所示分析结果

Analyse Fieldname / FieldType表示字段类型,这里我们选择文本类型即可。
4.2 solor域的配置
solor域的配置就是字段的配置。
域相当于数据库的表字段,用户存放数据,因此用户根据业务需要去定义相关的Field(域),一般来说,每一种对应着一种数据,用户对同一种数据进行相同的操作。
4.2.1 域的常用属性
• name:指定域的名称
• type:指定域的类型,可以自定义的类型,自定义的类型就是fieldType标签中配置的name属性
• indexed:是否索引,当需要根据该字段进行搜索的时候,一般都设置为true
• stored:是否存储
• required:是否必须
• multiValued:是否多值
例如:以下每一个field表示一个域

注意:关于type的配置,当我们要配置的字段需要进行搜索,进行分词,这时候,我们可以考虑使用自定义的类型。如果没必要分词,就直接指定string类型即可。本身string也是在solor总共配置的一个fieldType,如图;

4.2.2 域
solor的域配置都是根据实际业务需求进行配置的,虽然solor中内置了很多域,但是这些域并不能满足我们的实际需求,所以,我们一般情况下,不会使用solor给我们配好的域,而是根据实际需求,自定义域信息。
域的配置规则:
1)该字段需要不要进行搜索
2)我们需不需要将这个字段的结果显示出来
3)我们是不是需要用到这个字段的信息
4.2.3 复制域——copyField
复制域的作用在于将某一个Field中的数据复制到另一个域中
例如:将item_title、item_category、item_seller、item_brand域复制给item_keywords
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="item_title" dest="item_keywords"/>
<copyField source="item_category" dest="item_keywords"/>
<copyField source="item_seller" dest="item_keywords"/>
<copyField source="item_brand" dest="item_keywords"/>
配置说明:
1)field标签: 定义域对象
name:域对象的名称
type:指定域对象的分词类型
indexed:是否需要搜索
stored:是否需要存储
multiValued:是否多值
2)copyField:定义复制域
source:源。被复制的域对象的名称
dest:目的地。需要复制的域对象的名称
复制域的场景是什么了?
比方说在淘宝中搜索商品的时候,搜索框可以搜索商品的名称,可以搜索店铺名称,也可以搜索品牌等等,这时候,需要用很多or连接,会显得很麻烦,所以,为了这个场景下就可以使用复制域,让一个域是很多需要域的并集,这样,在搜索的时候,就直接指定这个复制域来搜索就可以了。
注意:
1. 复制域不需要存储,它只是一个逻辑上的域空间,不是物理的复制,所以需要存储。
2. multiValued必须要设置为true
4.2.4 动态域
当我们需要动态扩充字段时,我们需要使用动态域。比如:规格的值是不确定的,所以我们需要使用动态域来实现。
配置如下:
<dynamicField name="item_spec_*" type="string" indexed="true" stored="true" /> 配置解释:
1) dynamicField :配置动态域的标签
2)name:动态域的名称。例如:item_spec_* 表示前面item_spec_ 为固定名称,通配符* 后面的内容动态产生
3)type:字段类型,string,表示不需要进行分词
4)indexed;是否搜索
5)stored;是否存储
实现效果:
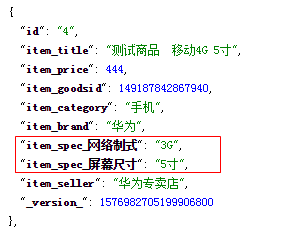
其中:网络制式与屏幕尺寸是动态生成的。
5. solor查询表达式
5.1 查询参数
q : 查询字符串,必须的。
fl: 指定返回那些字段内容,用逗号或空格分隔多个。
start: 返回第一条记录在完整找到结果中的偏移位置,0开始,一般分页用。
rows: 指定返回结果最多有多少条记录,配合start来实现分页。
sort: 排序,格式:sort=<field name>+<desc|asc>[,<field name>+<desc|asc>]。
示例:(inStock desc, price asc)表示先 "inStock" 降序, 再 "price" 升序,默认是相关性降序。
wt: (writer type)指定输出格式,可以有 xml, json, php, phps。
fq: (filter query)过虑查询,作用:在q查询符合结果中同时是fq查询符合的,
例如:q=mm&fq=date_time:[20081001 TO 20091031],找关键字mm,并且date_time是20081001到20091031之间的
q.op 覆盖schema.xml的defaultOperator(有空格时用"AND"还是用"OR"操作逻辑),一般默认指定
df: 默认的查询字段,一般默认指定
qt: (query type)指定那个类型来处理查询请求,一般不用指定,默认是standard。
indent:返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
version:查询语法的版本,建议不使用它,由服务器指定默认值。注意:solr查询时间为UTC 格式(2013-04-25T22:22:12.000Z)
5.2 检索运算符
: 指定字段查指定值,如返回所有值:
? 表示单个任意字符的通配
* 表示多个任意字符的通配(不能在检索的项开始使用*或者?符号)
~ 表示模糊检索,如检索拼写类似于"roam"的项这样写:roam~将找到形如foam和roams的单词;roam~0.8,检索返回相似度在0.8以上的记录。 邻近检索,如检索相隔10个单词的"apache"和"jakarta","jakarta apache"~10
^ 控制相关度检索,如检索jakarta apache,同时希望去让"jakarta"的相关度更加好,那么在其后加上""符号和增量值,即jakarta4 apache
布尔操作符 AND、||
布尔操作符 OR、&&
布尔操作符 NOT、!、-(排除操作符不能单独与项使用构成查询)
+ 存在操作符,要求符号"+"后的项必须在文档相应的域中存在
() 用于构成子查询
[] 包含范围检索,如检索某时间段记录,包含头尾,date:[200707 TO 200710]
{} 不包含范围检索,如检索某时间段记录,不包含头尾,date:{200707 TO 200710}
" 转义操作符,特殊字符包括+ - && || ! ( ) { } [ ] ^ " ~ * ? : "5.3 示例
1)查询所有
http://localhost:8080/solr/primary/select?q=*:*2)限定返回字段
// 查询所有记录,只返回productId字段
http://localhost:8080/solr/primary/select?q=*:*&fl=productId3)分页
// 查询前六条记录,只返回productId字段
http://localhost:8080/solr/primary/select?q=*:*&fl=productId&rows=6&start=04)增加限定条件
// 查询category=2、en_US_city_i=1以及namespace=d的前六条记录,只返回productId和category字段
http://localhost:8080/solr/primary/select?q=*:*&fl=productId&rows=6&start=0&fq=category:2&fq=namespace:d&fl=productId+category&fq=en_US_city_i:15)添加排序
// 查询category=2以及namespace=d并按category_i升序排序的前六条记录,只返回productId字段
http://localhost:8080/solr/primary/select?q=*:*&fl=productId&rows=6&start=0&fq=category:2&fq=namespace:d&sort=category_i+asc6. Solr的注解——@Field
用来标识实体类和solr的域之间的对应关系。如果属性与配置文件定义的域名称不一致,需要在注解中指定域名称
例如:
public class TbItem implements Serializable{
@Field
private Long id;
@Field("item_title")
private String title;
}
用@Field标识的字段id表示在solr域中有一个name属性值为id的filed域
例如:
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> @Field("item_title")则表示实体类的title对应solr域的item_title,例如:
<field name="item_title" type="string" indexed="true" stored="true" required="true" multiValued="false" /> 