机器学习入门概述总结
前言:
机器学习
是一门研究在非特定编程条件下让计算机采取行动的学科。最近二十年,机器学习为我们带来了
自动驾驶汽车
、
实用的语音识别
、
高效的网络搜索
,让我们
对人类基因的解读能力
大大提高。当今机器学习技术已经非常普遍,我们很可能在毫无察觉情况下每天使用几十次。许多研究者还认为机器学习是人工智能(AI)取得进展的最有效途径。
1、机器学习的定义
(1)
一个程序被认为能
从经验 E 中学习
,
解决任务 T
,
达到性能度量值P
,当且仅当,
有了经验 E 后
,
经过 P 评判
,程序在
处理 T 时的性能有所提升
。
(2)
从广义上来说,机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。
(3)
机器学习的定义用一句简单的话概述就是
把一堆无序的数据转化成有用的信息
。
(4)机器学习主要是研究如何使计算机从给定的数据中学习规律,即从观测数据(样本)中寻找规律,并利用学习到的规律(模型)对位置或无法观测的数据进行预测。
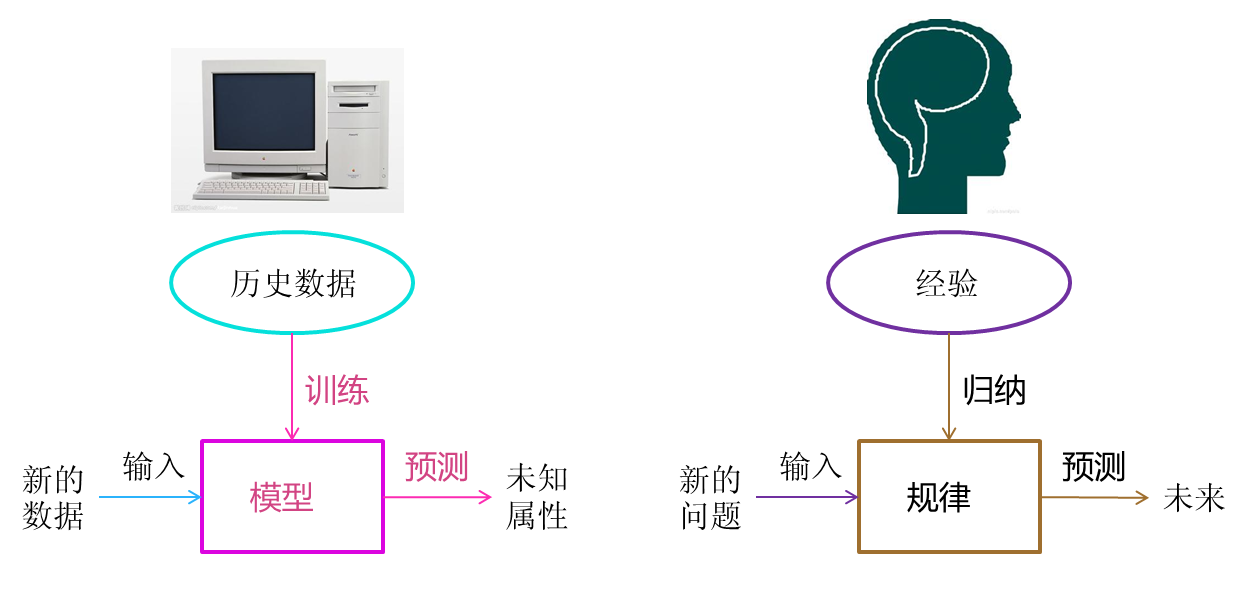
2、机器学习的领域
机器学习与
模式识别,统计学习,数据挖掘,计算机视觉,语音识别,自然语言处理
等领域有着很深的联系;
从范围上来说,机器学习跟模式识别,统计学习,数据挖掘是类似的。
机器学习与其他领域的处理技术的结合,形成了计算机视觉、语音识别、自然语言处理等交叉学科。因此,一般说数据挖掘时,可以等同于说机器学习。
我们平常所说的机器学习应用,应该是通用的,不仅仅局限在结构化数据,还有图像,音频等应用。

3、机器学习算法类型
(1)监督学习(Supervised Learning)
每组训练数据都有一个明确的标签和结果,利用这些已知的数据来学习模型的参数,使得模型预测的目标标签和真实标签尽可能接近。
监督学习主要应用
:预测房屋的价格,股票的涨停,垃圾邮件检测等。
监督学习主要算法
:回归和分类(线性回归,逻辑回归,神经网络,SVM、k-近邻、决策树(ID3、C4.5等)、朴素贝叶斯、AdaBoost等)
注:
把实例数据划分到合适的分类中(即分类)
用于预测数值型数据(即回归)
(2)无监督学习(Unsupervised Learning)
学习的数据不包含目标标签,需要学习算法自动学习到一些有价值的信息。
无监督学习主要应用
:社交网络的分析,天文数据分析,新闻事件分类等。
无监督学习主要算法:
聚类和密度估计(奇异值分解、主成分分析,独立成分分析、k-均值、Apriori算法和FP-growth)
注:
将数据集合分成由类似的对象组成的多个类的过程称为聚类
将寻找描述数据统计值的过程称为密度估计
(4)半监督学习(Semi-supervised Learning)
输入数据少量有目标标签的样本和大量没有目标标签的样本。首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。
应用场景
:包括分类和回归,算法包括一些对常用监督式学习算法的延伸
主要算法
:图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM)等
(5)强化学习(Reinforcement Learning)
输入数据直接反馈到模型,模型必须对此立刻做出调整。也就是常说的从经验中总结提升。
常见的应用场景
:动态系统以及机器人控制等,Google的AlphaGo就是运用了这种学习方式。算法本身会总结失败和成功的经验来达到很高的成功率。
常见算法:
Q-Learning以及时间差学习(Temporal difference learning)
(6) 遗传算法(Genetic Algorithm)
模拟进化理论,适者生存不适者淘汰,通过淘汰机制选择最优化的模型。
(7)推荐算法(
Recommendation Algorithm
)
分类:
基于内容的推荐算法、协同过滤推荐算法和基于知识的推荐算法
注:
在
企业数据应用的场景
下, 人们最常用的可能就是
监督式学习
和
非监督式学习
的模型。 在
图像识别
等领域,由于存在大量的非标识的数据和少量的可标识数据, 目前
半监督式学习
是一个很热的话题。 而
强化学习
更多的应用在
机器人控制及其他需要进行系统控制
的领域。
4、监督学习和无监督学习的区别
监督学习
中样本的输入属性x和输出y都给出,目的是学习从输入到输出的映射关系。
无监督学习
中只给出了输入数据,我们的目的是发现输入数据中的规律。
5、在具体应用中如何选择算法
(1)
首先考虑机器学习算法的目的。
(2)
如果是想要预测目标变量的值,则选择
监督学习算法
,否则选择
无监督学习算法
。
如果选择了监督学习算法,则要进一步确定目标变量类型,如果目标变量是
离散的
,则选择
分类器算法
,若果是
连续的
,则选择
回归算法
。
6、开发机器学习应用程序的步骤
(1)
收集数据
:方法:从网站上抽取数据、实例数据、公开可用的数据等。
(2)
数据输入
:把收集到的数据转变为符合格式要求的数据。
(3)
分析输入的数据
:查看是否有空值或异常值,常用的方法是画出可视化图形。
(4)
训练算法
:机器学习算法的开始,是算法的核心。(但在无监督学习中不需要此步骤)
(5)
测试算法
:目的是为了评估算法。在监督学习中,需用已知目标值的数据进行评估;对于无监督学习,需用其他的评测手段检验算法的成功率。
(6)
使用算法
:将机器学习算法转化为应用程序执行任务。
7、机器学习主要算法简单概述
(1)回归算法(Regression
Algorithm
)
在大部分机器学习课程中,回归算法都是介绍的第一个算法。原因有两个:一是回归算法比较简单,介绍它可以让人平滑地从统计学迁移到机器学习中。二是回归算法是后面若干强大算法的基石,如果不理解回归算法,无法学习那些强大的算法。回归算法有两个重要的子类:即
线性回归
和
逻辑回归
。
从本质上讲,线型回归处理的问题类型与逻辑回归不一致。
线性回归处理的是数值问题
,也就是最后预测出的结果是数字,例如房价。而
逻辑回归属于分类算法
,也就说,
逻辑回归预测结果是离散的分类
,例如判断这封邮件是否是垃圾邮件,以及用户是否会点击此广告等等。
常见的回归算法包括
:最小二乘法(Ordinary Least Square),逻辑回归(Logistic Regression),逐步式回归(Stepwise Regression),多元自适应回归样条(Multivariate Adaptive Regression Splines)以及本地散点平滑估计(Locally Estimated Scatterplot Smoothing)
回归算法在现实世界的应用,如:
- 信用评分
- 度量营销活动的成功率
- 预测某一产品的收入
- 在一个特定的日子里会发生地震吗?等
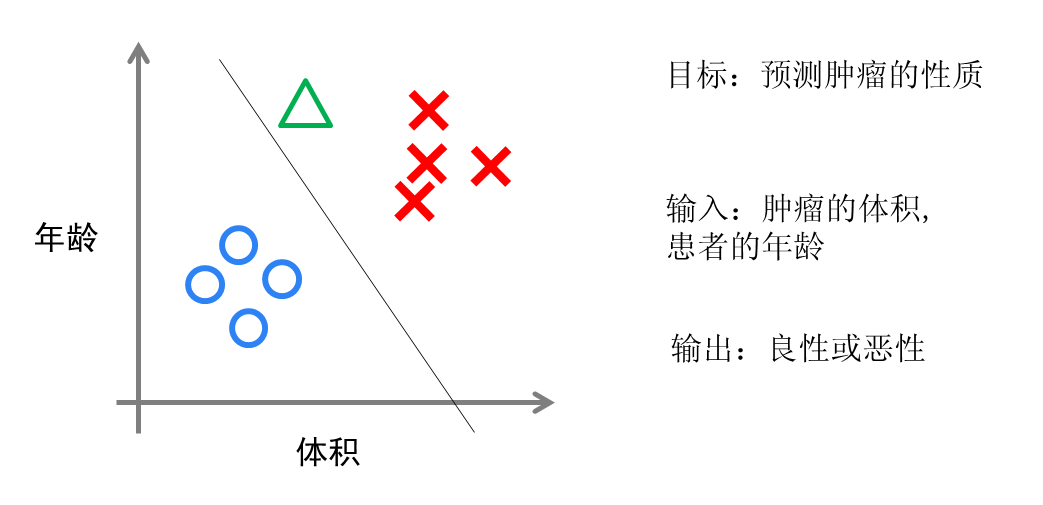
下图为:逻辑回归的直接展示
(2)人工神经网络
(Artificial Neural Network)
人工神经网络算法模拟生物神经网络,是一类模式匹配算法。通常用于解决
分类
和
回归
问题。(神经网络(也称之为人工神经网络,ANN)算法)
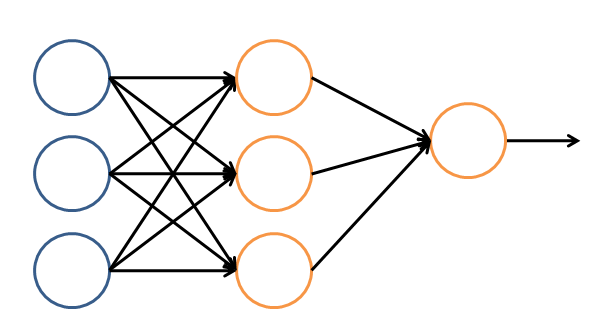
简单的神经网络的逻辑架构分成
输入层
,
隐藏层
,和
输出层
。
输入层负责接收信号,隐藏层负责对数据的分解与处理,最后的结果被整合到输出层
。每层中的一个圆代表一个
处理单元
,可以认为是模拟了一个神经元,若干个处理单元组成了一个层,若干个层再组成了一个网络,也就是"神经网络"。
在神经网络中,每个处理单元事实上就是一个逻辑回归模型,逻辑回归模型接收上层的输入,把模型的预测结果作为输出传输到下一个层次。通过这样的过程,神经网络可以完成非常复杂的非线性分类。
重要的人工神经网络算法包括
:感知器神经网络(Perceptron Neural Network), 反向传递(Back Propagation), Hopfield网络,自组织映射(Self-Organizing Map, SOM)。学习矢量量化(Learning Vector Quantization, LVQ)
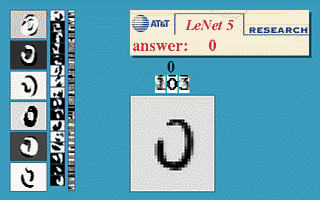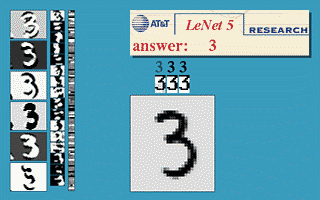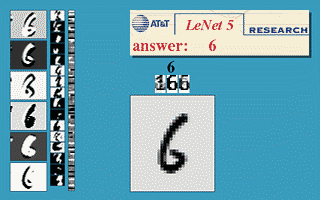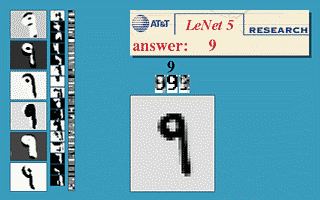
下图会演示神经网络在
图像识别领域
的一个著名应用,这个程序叫做
LeNet
,是一个基于多个隐层构建的神经网络。通过LeNet可以识别多种手写数字,并且达到很高的识别精度。
(3)SVM(支持向量机)
支持向量机算法是诞生于统计学习界,同时在机器学习界大放光彩的
经典算法
。
支持向量机算法从某种意义上来说是
逻辑回归算法的强化
,通过给予逻辑回归算法更严格的优化条件,支持向量机算法可以获得比逻辑回归更好的分类界线。
通过跟
高斯“核”
的结合,支持向量机可以表达出非常复杂的分类界线,从而达成很好的的分类效果。“核”事实上就是一种特殊的函数,最典型的特征就是可以
将低维的空间映射到高维的空间
。
(4)聚类算法
在聚类算法中,训练数据都是不含标签的,而算法的目的则是通过训练,推测出这些数据的标签。这类算法有一个统称,即无监督算法。无监督算法中最典型的代表就是聚类算法。
常见的聚类算法包括 k-Means算法以及期望最大化算法(Expectation Maximization, EM)。
(5)降维算法
降维算法也是一种无监督学习算法,其主要特征是
将数据从高维降低到低维层次
。在这里,维度其实表示的是数据的特征量的大小,例如,房价包含房子的长、宽、面积与房间数量四个特征,也就是维度为4维的数据。可以看出来,长与宽事实上与面积表示的信息重叠了,例如面积=长 × 宽。
通过降维算法我们就可以去除冗余信息
,将特征减少为面积与房间数量两个特征,即从4维的数据压缩到2维。于是我们将数据从高维降低到低维,不仅利于表示,同时在计算上也能带来加速。
刚才说的降维过程中减少的维度属于肉眼可视的层次,同时压缩也不会带来信息的损失(因为信息冗余了)。如果肉眼不可视,或者没有冗余的特征,降维算法也能工作,不过这样会带来一些信息的损失。但是,降维算法可以从数学上证明,从高维压缩到的低维中最大程度地保留了数据的信息。因此,使用降维算法仍然有很多的好处。
降维算法的主要作用
是
压缩数据与提升机器学习其他算法的效率
。通过降维算法,可以将具有几千个特征的数据压缩至若干个特征。另外,降维算法的另一个好处是数据的可视化,例如将5维的数据压缩至2维,然后可以用二维平面来可视。
降维算法的主要代表是
PCA算法
(即主成分分析算法)。
(6)推荐算法
推荐算法是目前业界非常火的一种算法,在电商界,如亚马逊,天猫,京东等得到了广泛的运用。
推荐算法的主要特征
就是
可以自动向用户推荐他们最感兴趣的东西,从而增加购买率,提升效益。
推荐算法有两个主要的类别:
(1)
基于物品内容的推荐
,是将与用户购买的内容近似的物品推荐给用户,这样的前提是每个物品都得有若干个标签,因此才可以找出与用户购买物品类似的物品,这样推荐的好处是关联程度较大,但是由于每个物品都需要贴标签,因此工作量较大。
(2)
基于用户相似度的推荐
,则是将与目标用户兴趣相同的其他用户购买的东西推荐给目标用户,例如小A历史上买了物品B和C,经过算法分析,发现另一个与小A近似的用户小D购买了物品E,于是将物品E推荐给小A。
两类推荐都有各自的优缺点,在一般的电商应用中,一般是两类混合使用。推荐算法中最有名的算法就是
协同过滤算法
。
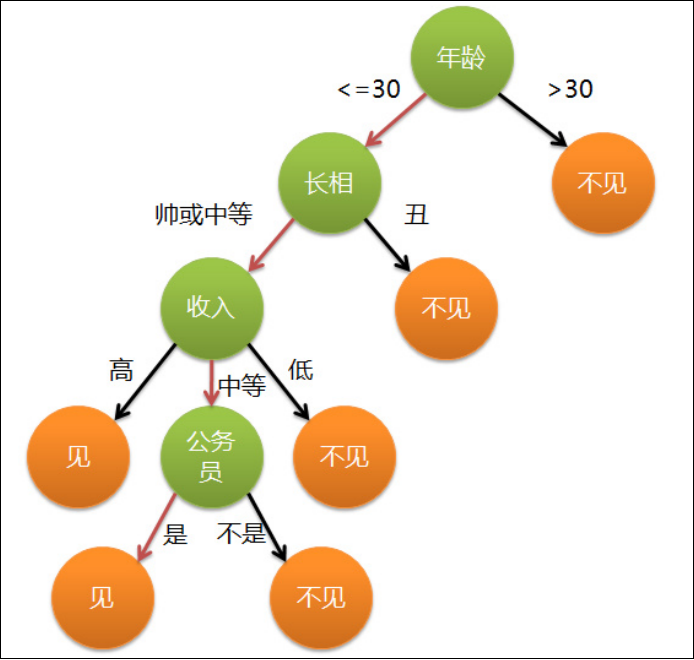
(7)决策树算法
决策树算法根据数据的属性采用树状结构建立决策模型, 决策树模型常常用来解决
分类和回归
问题。
常见的算法包括
:分类及回归树(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3), C4.5, Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 随机森林(Random Forest), 多元自适应回归样条(MARS)以及梯度推进机(Gradient Boosting Machine, GBM)
分类决策树
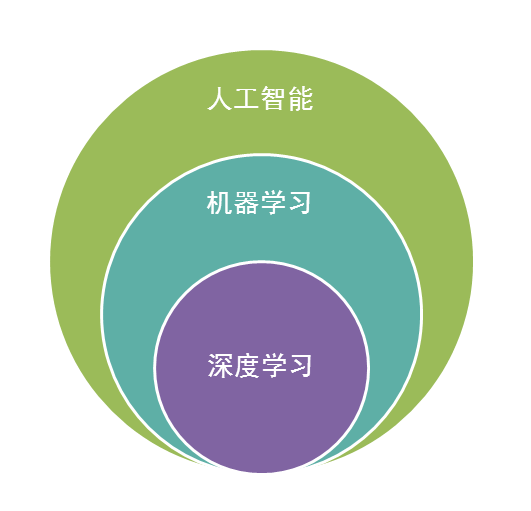
机器学习是人工智能的核心,深度学习是机器学习的子类

参考资料:
吴恩达的机器学习课程:
机器学习实战书籍