机器学习(1)- 概述
其他
2020-01-30 10:35:50
阅读次数: 0
1. 人工智能概述
1.1 人工智能概述[了解]
- 人工智能定义
- 用来模仿人类学习以及其他方面智能的一门新的技术科学
- 人工智能应用场景
- 网络安全
- 电子商务
- 计算模拟
- 交通模式
- 社交网络
- 传感网络.
1.2 人工智能发展历程
- 人工智能的起源【了解】
- 图灵测试: 人类智能
- 达特茅斯会议(1956年)
人工智能: 用机器模拟人类学习和其他方面的智能.
人工智能元年: 1956年
- 发展历程(了解)
第一个黄金期: 1956年-20世纪60年代初
第一个低谷期: 20世纪60年代初~20世纪70年代初
第二个黄金期: 20世纪70年代初~20世纪80年代中
第二个低谷期: 20世纪80年代中~20世纪90年代中
蓬勃发展期: 20世纪90年代中~今
1.3 人工智能主要分支【了解】
- 人工智能、机器学习和深度学习的关系
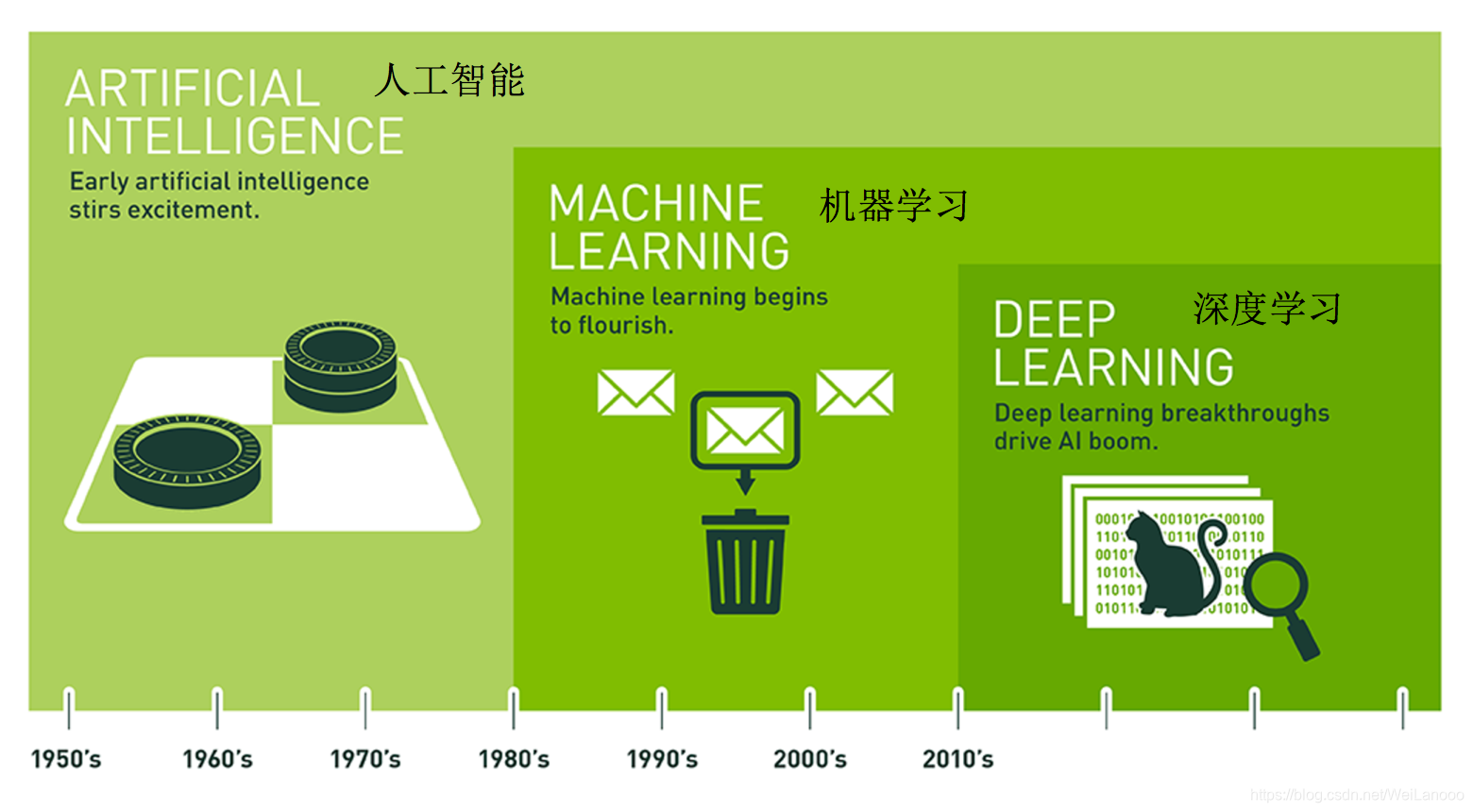
- 机器学习是人工智能的一种实现途径
- 深度学习是机器学习的一个方法发展而来
- 主要分支介绍
- 机器视觉
- 自然语言处理(NLP)
- 语音识别
- 文本挖掘/分类
- 机器翻译
- 机器人
- 人工智能发展必备三要素
- GPU与CPU对比
- CPU: IO密集型的操作
- GPU: 计算密集型的操作.
1.4 机器学习工作流程[理解.重点]
- 什么是机器学习
机器学习: 从数据中自动分析获得获得模型, 并利用模型对未知数据进行预测.
- 机器学习工作流程
- 获取数据
- 数据处理
- 特征工程
- 机器学习(训练模型)
- 模型评估
2.1 获取到的数据集介绍
- 数据集构成
- 一行数据就是一个样本
- 一列数据是一个特征
- 目标值(标签值): 预测的目标, 连续(回归), 离散(分类)
- 数据类型的构成
- 数据类型1: 特征值 + 目标值 -> 监督学习
- 数据类型2: 只有特征值, 没有目标值 -> 无监督学习算法
- 数据分割:
- 训练集: 用于模型训练的
- 测试集: 用于评估模型的
- 划分比例: 测试集, 20%~30%
2.2 数据基本处理
2.3 特征工程:
- 定义
- 把数据转换为能够让算法发挥更好效果的数字特征过程.
- 特征工程包含内容
- 特征提取: 把任意的数据(文本/图片), 转换可用于机器学习的数字特征的过程
- 特征预测处理: 使用一些转换函数, 把数据转换为更加适合算法模型的特征的过程
- 特征降维: 减少特征的维度(数量)
2.4 机器学习
2.5 模型评估
1.5 机器学习算法分类[记忆.重点]
- 监督学习
- 无监督学习
- 数据数据: 只有特征值, 没有目标值
- 算法: 聚类(相似的样本聚到一个类别中))
- 半监督学习
- 强化学习
- 概念: 智能体通过不断试错, 得到一个最佳策略.
- 四要素:
- 智能体(Agent)
- 环境(Environment)
- 行动(Action)
- 奖励(Reward)
1.6 模型评估
- 分类模型评估
- 准确率: 预测正确的数量占总样本数量的比例
- 精确率
- 召回率
- F1-Score
- AUC指标
- 回归模型评估
- 均方根误差(RMSE): 预测值减去真实值的平方和除以样本数量, 然后再开根号
- 相对均方误差(RSE): “预测值减去真实值的平方和” 除以 “真实值的均值减去真实值的平方和”
- 平均绝对误差(MAE): 预测值减去真实值的绝对值的和除以样本数量
- 相对绝对误差(RAE): 预测值减去真实值的绝对值的和 除以 真实值平均值减去真实值的绝对值的和
- 上面评估误差越小说明模型越好!
- R^2: 1- 相对均方误差(RSE), 意义: 值越接近与1, 模型越好, 值越小模型越差
- 拟合:
- 拟合的两个问题
- 欠拟合:
- 特点: 在训练集上表现差, 在测试集表现也差
- 原因: 模型太简单了, 学到特征太少了.
- 过拟合:
- 特点: 在训练集上表现很好, 在测试集上表现差
- 原因: 模型太复杂了, 学到特征的太多了.
1.8 深度学习简介【了解】
- 神经网络: 输入 -> 多层神经网络(每一层都有多个节点) -> 输出
发布了112 篇原创文章 ·
获赞 289 ·
访问量 14万+
转载自blog.csdn.net/WeiLanooo/article/details/102508026
