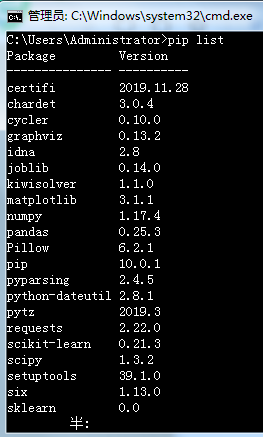
1)贴上Python环境及pip list截图,了解一下大家的准备情况。暂不具备开发条件的请说明原因及打算。

2)贴上视频学习笔记,要求真实,不要抄袭,可以手写拍照。






3)什么是机器学习,有哪些分类?结合案例,写出你的理解。
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
目前机器学习主流分为:监督学习,无监督学习,半监督学习,强化学习。
监督学习是从标记的训练数据来推断一个功能的机器学习任务。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。一个最佳的方案将允许该算法来正确地决定那些看不见的实例的类标签。
无监督学习——我们有一些问题,但是不知道答案,我们要做的无监督学习就是按照他们的性质把他们自动地分成很多组,每组的问题是具有类似性质的(比如数学问题会聚集在一组,英语问题会聚集在一组,物理........)比如:阅兵
所有数据只有特征向量没有标签,但是可以发现这些数据呈现出聚群的结构,本质是一个相似的类型的会聚集在一起。把这些没有标签的数据分成一个一个组合,就是聚类(Clustering)
半监督学习在训练阶段结合了大量未标记的数据和少量标签数据。与使用所有标签数据的模型相比,使用训练集的训练模型在训练时可以更为准确,而且训练成本更低。在现实任务中,未标记样本多、有标记样本少是一个比价普遍现象,如何利用好未标记样本来提升模型泛化能力,就是半监督学习研究的重点。要利用未标记样本,需假设未标记样本所揭示的数据分布信息与类别标记存在联系。
强化学习就是智能系统从环境到行为映射的学习,以使奖励信号(强化信号)函数值最大。如:走路、踢球。