问题引出:信息增量是什么?干什么用?
一颗决策树中的非叶子节点有split函数,用于将当前所输入的数据分到左子树或者右子树。我们希望每一个节点的split函数的性能最大化。这里的性能是指把两种不同的数据分开的能力,不涉及到算法的时间复杂度。但是,怎么去衡量一个split函数的性能呢?这里我们使用信息增益来衡量
。如果
越大,说明该节点的split函数将输入数据分成两份的性能越好。
下面图片是一个决策树的例子。来自https://www.cnblogs.com/xiemaycherry/p/10475067.html

下面图片表示决策树中的三个节点,其中父节点有一个split函数,用于分割所输入的数据成两份。

如何计算信息增益 ?下面先给出公式,再讲本人的理解。
-
香侬交叉熵公式
-
信息增益公式
香侬交叉熵公式的理解:
这个公式应该分成两部分,第一部分是
, 第二部分是
。前者表示
的信息量,后者表示
出现的概率。所以,公式
表示对于所有的c的信息量的期望。
一件事情的信息量跟这件事情发生的概率相关。可以直观理解为。一件事发生的概率越小,说明这件事的不确定越大,情况也就越复杂,所以信息量大。反之亦然。为了表示这种关系,我们使用下面图示公式来建模已知的一件事情的信息量:
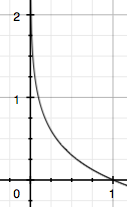
如果我们知道了每一件事所发生的信息量,再结合它所发生的概率,就可以计算它这些事情的信息量的期望了。(期望,其实是加权平均值,最简单的期望是均权平均值。所以公式
的前面的
可以理解为平均值的权重了)。
下面给出两棵树,输入两次数据,每次都输入100个(第一次输入一百个红色的,第二次是一百个蓝色的)。哪一棵树的split函数的分割性能更好呢?
通过观察,第二棵树好一点,因为,第二棵树把大部分红色数据分到了左边,把大部分蓝色数据分到了右边。所以,第二棵树的信息增益比第一颗的好。
如何使用上面的数学公式计算呢?

下面的图片便是计算第一棵树的信息增量了,最后的结果约等于0.0054。通过同样的方式可以计算第二棵树的信息增量,比第一棵树大。

通过上面的计算过程,我们发现,如果一个节点的split函数将输入的数据均匀地切分成两份,那么相应地信息熵的期望为
, log以2为底。

如果把输入数据分成两份不同的数据,比如下图所示,那么,交叉熵的期望就会变小。即下面公式的
变小,如果其它部分不变,
会变大。
表示分到一个分支上的数据量占该分支所有数据量的比值(建议结合上面计算公式理解)。该比值越大,说明本次分割对当前分支的影响也就越大了。本质上它是一个权重值。

以上便是决策树的信息增量和本人的理解。
