一、语音的产生
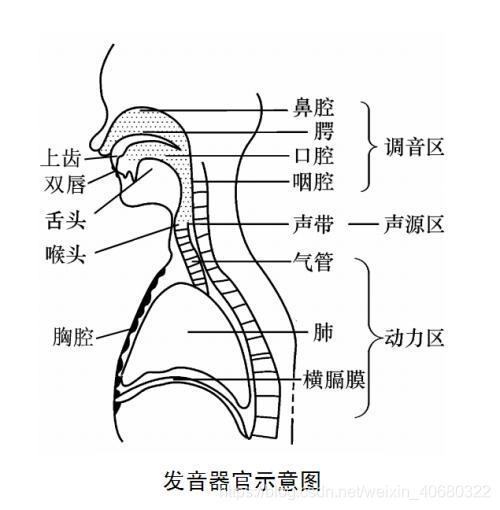
- 语音产生过程:激励-调制模型(Exicitation-Modulation Model)/源-滤波模型(Source-Filter Model)
- 激励(声源):肺部产生气流,通过猴头时冲击声带,使声带产生振动;
- 调制(调音):声带振动引起气流疏密变化,并在口腔和鼻腔中产生共鸣,这一共鸣会导致气流的疏密模式发生变化。
- 最后,这些疏密相间的模式由口唇辐射出来,产生我们听到的语音(周期性变化+纵波传播)。
- 启发:将声音分解成声带激励+声道调制。(分析发音内容时应更关注声道调制,分析情绪变化时应更关注声带激励的变化)
- 语音波形图(语音信号的时域表示)
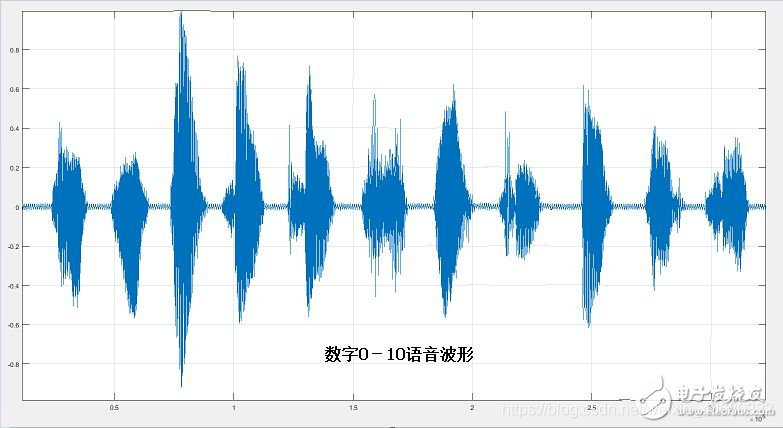
- 采样:如果在空间中确定一个位置,每隔一个非常短的时间(如1/16000秒)记录一次空气密度,即可记录下该点处的语音信号。
- 采样点:每个记录值。
- 采样频率:一秒内的采样次数(16000)。
- 语音信号的波形图:将密度值表示为时间的函数。
【注:空气密度变化和压力变化是一致的,因此语音波形记录的也是空气压力的变化】
- 语音频谱图(语音信号的频域表示)
- 语音信号的短时平稳属性:从波形图可看出,在一较短时间内(如0.01秒)信号的特性变化很小,但长时间看,不同时段的信号特性会发生明显的变化。
- 短时分析:将语音信号切分成一个个短时片段(信号稳定),利用各种稳态信号分析工具对这些片段进行处理。
- 语音帧:这些短时语音片段,一般长度为0.01秒左右。
- 短时频谱分析(一种常用的短时分析方法):提取每一帧中不同频率成分的能量大小。
- 某帧的频谱/短时频谱:该语音帧在不同频率上的能量。
- 某段语音的频谱:该段语音中的所有语音帧的短时频谱。
- 频谱图:横轴:频率。
[参考:https://www.cnblogs.com/tibetanmastiff/p/6741930.html]

- 语谱图:横轴:时间;纵轴:频率;颜色深浅:频率强度。
[参考:https://www.cnblogs.com/tibetanmastiff/p/6741930.html]
二、语音的感知
- 计算机看到的语音:一维振动的采样序列。
- 语音信号中嵌入的信息:发音内容、说话人身份、说话方式、目标与动机等。
- 语音信号中的随机性:发音过程中的无意识变动(如送气和舌位差异)、外界环境的噪声、声音采集设备的差异等。
