一、意义
训练过程中,UBM通过MAP自适应,可以得到每个说话人的GMM模型。
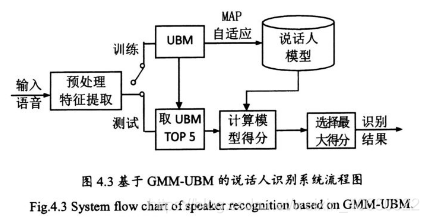
二、算法示意图
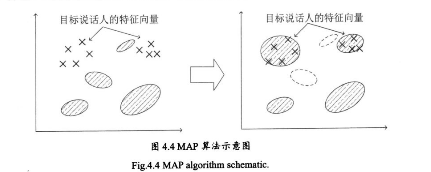
三、算法过程
1. 与EM算法中的E-Step相同
- 已知
a.
O={o1,o2,...,oT}:某一个说话人的矢量特征。
b.
i:UBM的某个高斯分量。
c.
λ={wi,ui,Σi∣i=1,2,...,M}:UBM的参数,共有M阶高斯分量。
- 目标:计算该矢量特征序列中 每个向量 对于UBM中每个高斯分量的后验概率分布。
- 公式
P(i∣ot,λ)=∑j=1Mwjp(ot∣uj,Σj)wip(ot∣ui,Σi)
- 导出公式
a. 训练语音 属于第
i个高斯分量的帧数(
T:训练语音的帧数)
ni=t=1∑TP(i∣ot,λ)
b.
Ei[o]=ni1t=1∑TP(i∣ot,λ)ot
c.
Ei[ooT]=ni1t=1∑TP(i∣ot,λ)ototT
2. 用
ni得到的修正因子更新旧的UBM参数
λ
- 已知
a.
βi=ni+γni:高斯分量的权重、均值向量、协方差矩阵的修正因子。
作用:平衡GMM模型的新旧参数。(值越大说明数据越充分,新参数越可信)
b.
γ:关系因子。
作用:约束修正因子
βi的变化尺度,让所有混合权值和为1。(常取16)
- 更新公式
a.
w^i=[Tβini+(1−βi)wi]γ
b.
u^i=βiEi[o]+(1−βi)ui
c.
Σ^i=βiEi[ooT]+(1−βi)(Σi+uiuiT)−u^iu^iT
参考论文:基于GMM-UBM模型的说话人识别系统的第39-40页。
