已知数据X,去拟合某个概率模型的参数θ,是最基本的机器学习过程。
本文将入门讲解3个最基本的方法:最大似然估计(Maximum Likelihood Estimation,简称MLE),最大后验概率估计(Maximum a Posteriori estimation,简称MAP),以及贝叶斯估计。
下面的所有讲解都将用到这样的一组实验数据:抛一个硬币10次,得到如下结果:
正正反正反正正正反正
根据实验结果,我们的目标是用经典的二项分布来描述该概率模型。该概率模型有一个参数θ,即:每投一次硬币,出现正面的概率:p(正) =θ。我们将要通过数据来拟合这个参数。
下面分别用上述三种方法来求解θ。
1、 最大似然估计(Maximum Likelihood Estimation,MLE)
顾名思义, 最大似然估计尝试求解使得X出现概率最高的θ。
抛一个硬币10次,出现正面7次,我们的直觉会告诉我们,θ很有可能为0.7。
实际上,这种直觉恰好就是最大似然估计的结果。那么具体如何求解呢?
对于m次实验,由于每次都是独立的,我们可以将X中每一次实验结果Xi的似然函数P(Xi|θ)全部乘起来,那么,使得该式取得最大值的θ*,即为θ的最大似然估计:

在本例中,即:
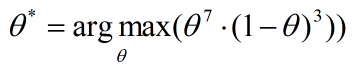
我们用横轴表示θ的取值(从0到1),纵轴表示上述函数的值,该函数绘制出来如下所示:
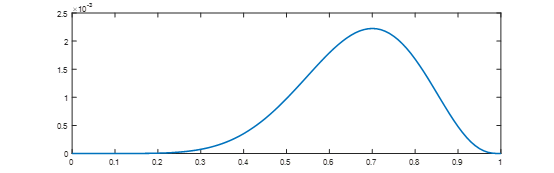
图1 P(X|θ)的似然函数
很容易看到,当θ取值为0.7时,函数取得唯一的极大值。
具体求解方式可对该函数求导。为了便于计算,通常引入对数来处理:

当导数为0时函数取得极大值,此时θ取0.7。
值得注意的是,最终的表达式为正面出现的次数除以总实验次数,恰好符合我们的直觉。
2、最大后验概率估计(Maximum a Posteriori estimation,MAP)
上述最大似然估计方法尝试求解θ来最大化似然函数P(X|θ),显然计算出来的参数完全取决于实验结果。
如果该硬币是完全对称的(即实际上θ=0.5),但是由于实验误差,10次出现了7次正面,因此我们计算出来的0.7与真实值0.5相比,也产生了很大的误差。
MAP方法能够很大程度解决这个问题。该方法尝试最大化另外一个概率值——后验概率P(θ|X) 。
我们来看看这样做有什么不同。由贝叶斯公示我们得知:

上式的分母部分P(X)为已知的(称作证据),因此,我们只需要最大化分子部分:P(θ|X)P(θ)。
注意该式和最大似然估计的唯一区别,是增加了先验概率P(θ)。这里如何处理呢?
实际上,这里的先验概率是我们自己来设定的(这就是所谓的先验知识,即你的认知、经验等),和实验结果X无关。
在此例中,先验概率表示我们的经验和认知告诉我们,对于投硬币这个二项分布模型而言,该模型的参数θ应该服从什么分布。
比如,我坚定的认为,硬币就应该很均匀,但允许在0.5附近有一定偏差,那么,我们可以选择一个正态分布N(0.5, 0.1)来描述θ:
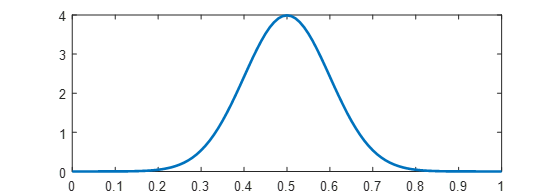
图2 P(θ)的正态分布
由于我们的任务为最大化P(θ|X)P(θ),因此我们如果把图1和图2的两个函数乘起来,便得到了函数P(θ|X)P(θ)。该图像的最大值即为所求:

图3 当P(θ)为正态分布时的P(θ|X)P(θ)
图中,上子图是实验10次,正面7次的结果;下子图是实验1000次,正面700次的结果。
可以看到,实验10次,取得最大值时的θ在0.57左右,明显小于MLE求出来的0.7。
而实验1000次,取得最大值时的θ在0.7左右。
因此,可以这样理解:MAP方法对实验数据保留了怀疑态度,因此引入了先验信息来缓解实验数据的误差。如果要说服MAP相信实验结果,则必须增加实验次数。
如果我们选择θ服从Beta(2,2)的贝塔分布,则同样的实验结果下,计算出来的结果如下:

图4 当P(θ)为贝塔分布时的P(θ|X)P(θ)
10次实验结果下,θ在0.68左右取得最大值。
可见,实验样本不够多的时候,先验概率模型的选择对结果影响还是很大的。就本例而言,Beta分布相对于正态分布,更愿意相信实验数据。
3、贝叶斯估计
贝叶斯估计与上述两类估计方法最大的区别在于:该类方法并不求出参数θ的具体值,而是求出θ的概率分布模型。
简单的说来,MLE方法求出θ=0.7,MAP求出θ=0.68,而对于贝叶斯估计,如果假设θ服从贝塔分布,则最终求出θ~Beta(α,β)的模型参数α,β。
首先,我们先来看贝塔分布的几种表示形式:
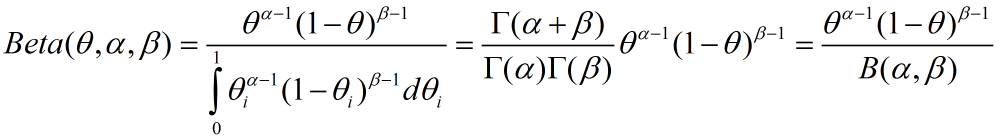
我们在待会的计算中会用到上述表达形式。
下面同样以10次抛硬币7次正面的结果为例进行讲解。
之前,我们已经介绍了贝叶斯公示。在MAP计算中,我们省略了贝叶斯公式中的证据部分P(X)。但是在贝叶斯估计方法里,我们要利用P(X)做点事情:
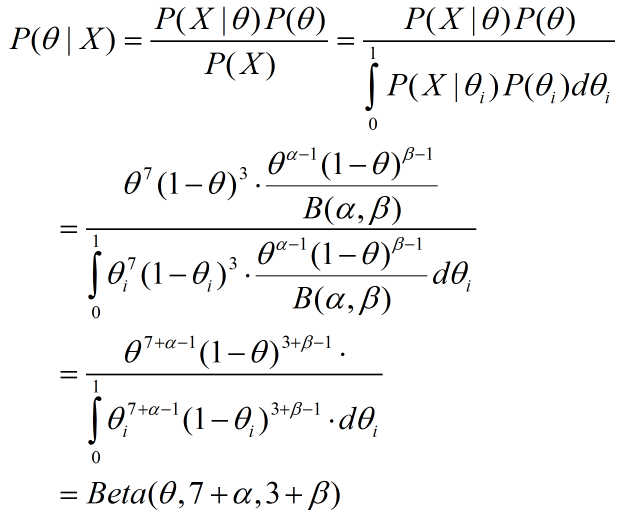
在上式中,我们通过全概率公式展开P(X)、约掉B(α,β),将结果巧妙的组成了一个新的贝塔概率分布函数θ~Beta(α+7,β+3),而这就是我们要求解的θ的概率分布。
计算的结果为一个新的贝塔分布,难道仅仅是巧合吗?
其实这是因为P(θ)使用的先验模型——贝塔分布,与P(θ|X)使用的伯努利分布是共轭关系。正是这种共轭关系,使得伯努利分布乘以贝塔分布,其结果是一个新的贝塔分布。
可以这样理解贝叶斯方法:
(1)首先提出一个先验模型,该模型参数为θ;
(2)通过结合实验数据,最终得到一个新的模型,该模型参数为θ*。
这个过程很好的体现了通过数据来修正模型的思想。
参考文献:
1、参数估计:贝叶斯思想和贝叶斯参数估计
2、常用的概率分布:二项式分布,贝塔分布,狄里克雷分布
3、详解最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解