前言
核心问题是:预训练-微调框架,瓶颈在哪里?
该框架的一个特点就是:下游的任务需要继承上游预训练模型的词表。有两个问题:
- 预训练模型通常需要覆盖较大范围的词表,而下游任务不需要那么大,造成serious exposure bias和计算损耗
- 下游任务中很常见的单词,在上游预训练中会被分为under-represented tokens
本文训练了一个”generator“,输入下游任务中存在、原词表不存在的词,生成原词表中存在的、词形上相似的词,并利用原预训练模型的信息,对这些词做初始化。
方法
pipeline
流程如下:
- 首先预训练一个语言模型
- 进一步预训练一个生成器,该生成器可以为所有输入的OOV,得到一个不错的向量表示
- 最后在下游任务中,首先学习到下游语料上的子词分割、及其下游词表,然后结合预训练的词表(用于提供原本有的词的embedding)以及生成器(用于提供原本没有、但在下游词表中存在的词的embedding),来构造新的embedding层。最后,结合重构的下游任务的embedding层,以及原来预训练模型的上层网络,得到一个改变词表的预训练模型,用于下游任务。
关键在于generator的构建。
generator的构建
存在这样的词法(morphologically)上的特性:
- 对于完整的词,它和它包含的子词有关
- 对于子词,它和包含它的完整的词有关
所以,给定一个词w,去找两个集合:1. 用预训练模型的segmentation principle来将词分成子词(subwords set);2. 从预训练模型词表中遍历包含该词的完整词(hyperwords set)。然后得到一个相关词集,进一步采用三种方法来产生embedding: - average
- attention mechanism,即训练一个d维的weight
- 定义六种关系(w和它的subword、hyperword的前、中、后缀),为不同的关系,训练一个d维的weight
如何训练下面两种generator呢?
generator的训练
本质想法:generator的作用是:输入一个unseen token,然后得到它的一个比较不错的向量表示。那一定要做的,就是构造这样的样本:对pre-training corpus中的、子词化的句子(记为 s p s^p sp),通过1. 随机选择一些subwords,拼接成unseen token;2. 随机选择一些token,把它分成unseen token。从而产生包含unseen token的句子(记为 s ” s^” s”)。然后采用两个loss function:
- 固定预训练模型的参数,重用预训练模型的loss function(如BERT,那就是MLM+NSP),来训练generator。(举个例子,输入了一个句子 s ” s^” s”,对于存在于词表中的词,就用预训练模型的embedding,对于不存在的,就通过上面generator的方式,来产生embedding,然后正常送入预训练模型的上层网络)
- 知识蒸馏,进一步利用原预训练模型的信息。(举个例子,对于 s p s^p sp中的某一个token1,可能通过预处理2,得到了unseen token1和unseen token2。token1通过原预训练模型的词表可以得到embedding1,unseen token1\2通过generator可以得到unseen emb1\2,然后取平均得到embedding2,去最小化这两个embedding的欧式距离):
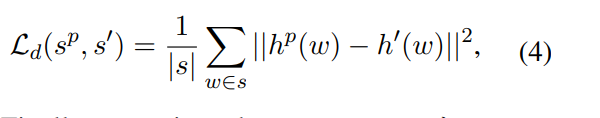
实验
TBC