Lessons for New pandas Users
给新pandas用户上课。

01-lesson:导入库——创建数据集——创建dataFrame——从CSV导出到写入CSV——查找最大值——绘制数据。
创建数据–我们首先创建我们自己的数据集进行分析。这将预防让终端用户能阅读本教程,而不需要下载任何文件来复制下面的结果。我们将把这个数据集导出到一个文本文件中,这样您就可以从文本文件中获取一些数据。
获得数据–我们将学习如何在文本文件中读取。这些数据包括婴儿名字和1880年出生的婴儿名字。
准备数据–在这里,我们将简单地查看数据并确保它是干净的。我的意思是,我们将查看文本文件的内容并查找任何异常。这些数据可能包括丢失的数据、数据的不一致或其他看起来不合适的数据。如果找到了,我们就必须决定如何处理这些记录。
分析数据–我们会在特定的年份找到最流行的名字
展示数据–通过表格数据和图表,清楚地向终端用户显示特定年份中最流行的名称。
创建数据
数据集将包括5个婴儿名字和那一年(1880年)的出生人数
# The inital set of baby names and bith rates
names = ['Bob','Jessica','Mary','John','Mel']
births = [968, 155, 77, 578, 973]- 1
- 2
- 3
要合并这两个列表,我们将使用zip函数
BabyDataSet = list(zip(names,births))
BabyDataSet- 1
- 2
Out[106]: [(‘Bob’, 968), (‘Jessica’, 155), (‘Mary’, 77), (‘John’, 578), (‘Mel’, 973)]
BabyDataSet是一个列表,每一个元素是成对元祖。
我们基本上完成了创建数据集的工作。现在我们将使用pandas库将这些数据导出到一个csv文件中。
df将是一个DataFrame对象。您可以认为该对象以类似于sql表或excel电子表格的格式保存BabyDataSet的内容。让我们看一下df里面的内容。
df = pd.DataFrame(data = BabyDataSet, columns=['Names', 'Births'])
df- 1
- 2
数据部分用参数data= 赋值,列名由colulmns=指定 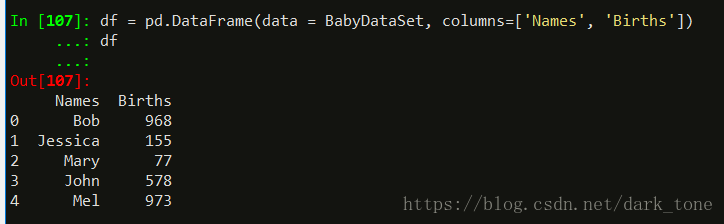
将dataframe导出到csv文件。我们可以命名文件births1880.csv。函数to_csv将用于导出文件。除非另有说明,否则文件将保存在notebook的同一位置。
我们将使用的唯一参数是索引和标头。将这些参数设置为False将防止索引和标题名称被导出。更改这些参数的值,以便更好地理解它们的使用。
df.to_csv('births1880.csv',index=False,header=False)- 1

获取数据
要获取csv文件,我们将使用pandas函数read_csv。让我们来看看这个函数以及它所需要的输入
即使这个函数有很多参数,我们也可以简单地使用它。
df = pd.read_csv('births1880.csv')
df- 1
- 2

这就引出了第一个问题。read_csv函数将csv文件中的第一个记录作为标题名称处理。这显然是不正确的,因为文本文件没有向我们提供标题名称。
为了纠正这个错误,我们将把header参数传递给read_csv函数,并将其设置为None(在python中为null)。
df = pd.read_csv('births1880.csv', header=None)
df- 1
- 2
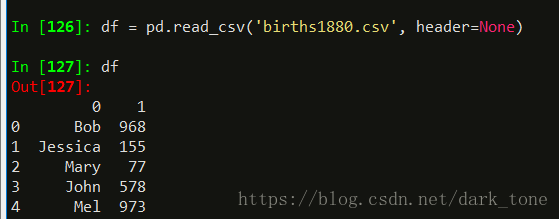
如果我们想要给出特定的列命名,我们必须传递一个名为names的参数。我们还可以省略header参数。
df = pd.read_csv('births1880.csv', names=['Names','Births'])
df- 1
- 2
您可以将数字[0、1、2、3、4]看作Excel文件中的行号。在pandas中,这些是dataframe索引的一部分。您可以将索引视为sql表的主键,但允许索引具有重复的异常。
准备数据
我们的数据包括婴儿名字和1880年出生的人数。我们已经知道我们有5个记录,并且没有一个记录丢失(非空值)。
在这个点上的名称列是没有关系的,因为它很可能是由字母数字字符串(婴儿名)组成的。在本专栏中有可能出现糟糕的数据,但在分析的这一点上我们不会担心。出生列应该包含代表特定年份出生的婴儿数量的整数。我们可以检查所有的数据是否属于数据类型的整数。让这个列有一个数据类型的浮点数是没有意义的。在分析的这一点上,我不会担心任何可能的异常值。
请注意,除了我们在“Names”列上进行的检查之外,我们还需要在这个阶段中查看dataframe内的数据。当我们继续在数据分析生命周期中,我们将有大量的机会发现数据集的任何问题。
#检查各列上的数据类型
df.dtypes- 1
- 2
Out[129]:
Names object
Births int64
dtype: object
如您所见,births列是int64类型的,因此在本专栏中不会出现浮点数(decimal number)或alpha数值字符。
分析数据
找到最受欢迎的名字或婴儿的名字和最高的出生率,我们可以做以下方法中的一个。
①对dataframe进行排序并选择第一行
②使用max()属性来找到最大值
# Method 1:
Sorted = df.sort_values(['Births'], ascending=False)
Sorted.head(1)- 1
- 2
- 3
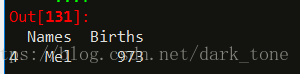
用sort_values排序df.sort_values(by=’Births’, ascending=False)也行。
# Method 2:
df['Births'].max()- 1
- 2
Out[133]: 973
展示数据
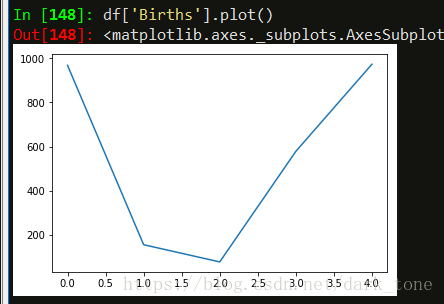
在这里,我们可以绘制出“出生”栏,并在图表上标注“最终用户”。与表一起,最终用户有一个清晰的图片,Mel是数据集中最受欢迎的婴儿名。
plot()是一个方便的属性,在这里,pandas可以轻松地在你的dataframe中绘制数据。我们学习了在上一节中如何找到出生列的最大值。现在,要找到973值的实际婴儿名看起来有点棘手,所以让我们检查一下。
[df['Births'] == df['Births'].max()] - 1
它等价于在births栏中找到所有的记录,它等于973,返回的是一个bool结构的dataFrame。
df['Names'][df['Births'] == df['Births'].max()]- 1
它等价于,在births栏等于973的栏中,选择Names列中的所有记录,返回值是一个对象。
Out[136]:
4 Mel
Name: Names, dtype: object
MaxValue = df['Births'].max()
maxname=df['Names'][df['Births'] == df['Births'].max()].values- 1
- 2
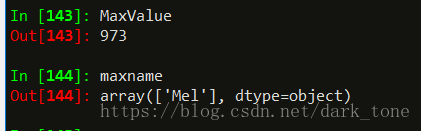
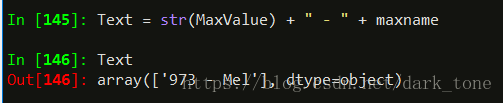
str()函数简单地将一个对象转换成一个字符串。
Text = str(MaxValue) + " - " + maxname- 1
# Create graph
df['Births'].plot()- 1
- 2
把text加入图片中
# Add text to graph
plt.annotate(Text, xy=(1, MaxValue), xytext=(8, 0),
xycoords=('axes fraction', 'data'), textcoords='offset points')- 1
- 2
- 3
这一步,我个人程序执行出错:Image size of 440x211608 pixels is too large,原因暂时不明(python版本问题?语句写法问题?原文出错?)
个人实践:
本例主要学习了zip函数,可以合并两个列表,形成元祖列表,再通过该元祖列表构建dataFrame。
然后学习了存储csv文件,读取csv文件,当存储和读取时,注意index,header,names参数对dataFrame结构的影响。
学习了如何用.types()函数查看各列的数据类型。
用sort_values()按照某一列的值对dataFrame排序,用max()求某一列的最大值。
另外这个例子可见,在一个N行N列的dataFrame结构里,如果已经单纯对比出某一列的值,再去找它对应那一行的其他列的信息,pandas写法挺麻烦的。
比如已经找到maxvalues是973,现在要找它对应的那行姓名信息,需要写出maxname=df[‘Names’][df[‘Births’] == df[‘Births’].max()].values,相当繁杂,人也容易被搞晕。
造成以上原因也很简单,因为此时,我们不知道数据在哪一行。
当然这个例子可以简化,比如另一种方法是使用已排序的dataframe:Sorted[‘Names’].head(1).value
把这个dataFrame先按照从大到小排序,再找排序后的第一行,写法会简单得多。
但是问题仍然没有彻底解决,如果不是找最大值的呢,仅仅是N行N列的dataFrame结构里某一个中间值呢。
比如这个例子,我们想要找出现了578次的对应name名,人工能看出是’John’。
我们不知道符合要求的数据在哪一行,那么排序的方法也就无效了。
我能想到的解决方法就是切片,利用条件筛选方式,单独切出要找的那一列,如果有好几个符合要求的值,
结果可能是若干列,把结果赋值给一个新的newdf。
对这个新的newdf[‘name’],找出想要的信息。
不知道对这类常见问题,pandas有没有更简单清晰的表达法?
按理说应该是有的,毕竟pandas功能如此强大。
不用额外切片,直接在原始数据上查找,类似df.find(name,Births==578)一个函数就能搞定那种,先标记起来。