实质:在定义域随机放置多个变量,不断跳跃,同步寻找最优解。寻找方向受单个粒子与全部粒子的最优位置共同影响。单个粒子按照公式不断迭代寻找当新位置。多个变量聚集在某一点时,该点即是最优解。
控制其搜索速度(步长)的因素有两个,使其兼备全局搜索能力和局部搜索能力,减少错过最优解几率
- 距离自身最优距离
- 距离群体最优距离
状态转移方程:
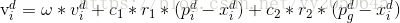
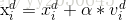
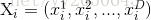
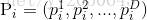
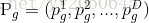
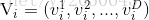
参数说明:
- 粒子数m:一般为20-40。根据实际定义。
- 惯性因子
:一般在0.6-0.75.影响步长(即影响 全局/局部 搜索能力)。
- 加速常数 c1 ,c2 : 控制速度的影响因素的权重。一般取2左右的值。
- 常数r1 , r2 :在[0,1]之间随机数。
- v,x:步长和位移值。
基本粒子群算法
权重 w 为1.
算法改进
https://blog.csdn.net/xuehuafeiwu123/article/details/52299628
线性递减:前期有较高的全局搜索能力以找到合适的种子,后期有较高的开发能力,以加快收敛速度,故惯性权重递减。
扫描二维码关注公众号,回复:
9305361 查看本文章

学习因子、惯性权重是改进粒子群算法的关键
更新函数决定了粒子群算法的本质能力。
matlab实现
- 初始化种群(位置和速度
- 权重随迭代次数的增加而降低(线性递减
- 计算粒子适应度,将各个粒子的位置和适应度储存在Pbest中,将Pbest中适应度最优个体的位置和速度储存在Gbest中
- 根据公式更新粒子的速度和位移
- 将各个粒子与前一个最优位置比较,如果较好,则将其设置为当前最优位置
- 比较当前的Pbest与上一周期的Gbest,更新Gbest
- 达到迭代次数或者达到精度,停止。否则返回第二步
说明:
- 为防止粒子位置超过最大区间,设定界限,在粒子位置与步长进行迭代时,超过边界最值的则设定为最值
- r1,r2为随机数
matlab代码实现(后期改多维也很方便)
% fitness 目标函数
% N 粒子数目
% c1,c2 学习因子 一般取2
% w 权重
% M 最大迭代次数 具体看精度要求
% D 自变量个数/空间维度 由目标函数决定
% a 上界
% b 下界
% Pbest 个体最优位置
% PVbest 个体最优适应度
% Gbest 种群最优位置
% GVbest 种群最优适应度
% 目标函数
a = -10;
b = 10;
wmax = 0.75;
wmin = 0.25;
vmin = -10;
vmax = 10;
N = 10;
D = 1;
M = 100;
c1 = 2;
c2 = 2;
%初始化种群
%多维时可以考虑 x = Xmin(i)+(Xmax(i)-Xmin(i))*rand(1,D);
% v = Vmin(i)+(Vmax(i)-Vmin(i))*rand(1,D);
for i = 1:N
for j = 1:D
x(i,j) = unifrnd(a,b);
v(i,j) = (vmin+vmax)/2+randn*(vmax-vmin)/(2*2);
%约95.4%数值分布在距离平均值有2个标准差之内的范围 故除以2
end
end
%因速度以定义域中点为中心 成标准正态分布 故需保证所有粒子都在定义域中
for i = 1:N
for j = 1:D
if v(i,j) < vmin
v(i,j) = vmin;
elseif v(i,j) > vmax
v(i,j) = vmax;
end
end
end
%权重下降
for i = 1:M
w(i) = wmax - ((wmax-wmin)/M)*i;
end
%初始化粒子适应度
Pbest = x;
PVbest = fitness(x(:,1));
%初始化全局最优
Gbest = Pbest(1);
GVbest = PVbest(1);
for i = 2:N
if GVbest>PVbest(i)
Gbest = Pbest(i);
GVbest = PVbest(i);
end
end
%迭代开始
for t = 1:M
for i = 1:N
v(i) = w(i)*v(i) + c1*rand*(Pbest(i)-x(i)) +c2*rand*(Gbest-x(i));
x(i) = x(i) + v(i);
%边界处理
index = find(x(i,:)<a | x(i,:)>b);
x(i,:) = unifrnd(a,b);
%更新最优粒子 根据实际确定
if fitness(x(i))< PVbest(i)
Pbest(i) = x(i);
PVbest(i) = fitness(x(i));
end
if PVbest(i) > GVbest
Gbest = Pbest(i);
GVbest = PVbest(i);
end
end
%每代最优值
Tbest(t) = GVbest;
end
figure
plot(Tbest);
xlable('迭代次数');
ylable('适应度值');
title('适应度进化曲线');
%目标函数 因此设定中只有一维,故
function y = fitness(x)
y = x^2;
end
