粒子群算法(PSO,Particle Swarm Optimization)是20世纪90年代兴起的一种算法,因其概念简明、实现方便、收敛速度快而为人所知。
PSO模拟鸟群的捕食行为。设想这样一个场景:一群鸟在随机搜索食物。在这个区域里只有一块食物。所有的鸟都不知道食物在那里。但是他们知道当前的位置离食物还有多远。那么找到食物的最优策略是什么呢。最简单有效的就是搜寻目前离食物最近的鸟的周围区域。
由于每个鸟都不知道食物在哪里,但是却知道距离多远,所以每次可以知道整个鸟群哪只鸟距离目标最近,当然最近的距离也知道,这个时候这只鸟可以对整个群体发“信号”,然后整个鸟群就向着这只鸟方向飞行,多次迭代之后,整个鸟群就已经接近目标了
粒子群算法的基本思想是模拟鸟群随机搜寻食物的捕食行为,鸟群通过自身经验和种群之间的交流调整自己的搜寻路径,从而找到食物最多的地点。其中每只鸟的位置/路径则为自变量组合,每次到达的地点的食物密度即函数值。每次搜寻都会根据自身经验(自身历史搜寻的最优地点)和种群交流(种群历史搜寻的最优地点)调整自身搜寻方向和速度,这个称为跟踪极值,从而找到最优解。
粒子群算法是一门新兴算法,此算法与遗传算法有很多相似之处,其收敛于全局最优解的概率很大。
①相较于传统算法计算速度非常快,全局搜索能力也很强;
②PSO对于种群大小不十分敏感,所以初始种群设为500-1000,速度影响也不大;
③粒子群算法适用于连续函数极值问题,对于非线性、多峰问题均有较强的全局搜索能力。
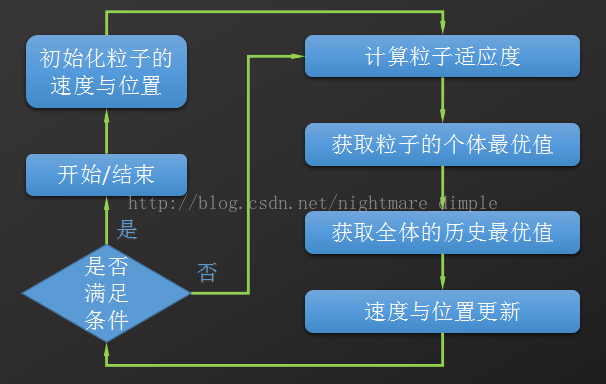
基本流程:

2.根据适应度算法计算粒子适应度
3.根据粒子计算的适应度值寻找粒子当前搜索到的最有位置与整个粒子群当前的最有位置

自适应变异是借鉴遗传算法中的变异思想,在PSO算法中引入变异操作,即对某些变量以一定的概率重新初始化。变异操作扩展了在迭代中不断缩小的种群搜索空间,使粒子能够跳出先前搜索到的最优值位置,在更大的空间中开展搜索,同时保持了种群多样性,提高算法寻找最优值的可能性。因此,在普通粒子群算法的基础上引入简单变异算子,在粒子每次更新之后,以一定概率重新初始化粒子。
重点一:一维的粒子群算法求解
粒子群算法中所涉及到的参数有:
种群数量:粒子群算法的最大特点就是速度快,因此初始种群取50-1000都是可以的,虽然初始种群越大收敛性会更好,不过太大了也会影响速度;
迭代次数:一般取100~4000,太少解不稳定,太多浪费时间。对于复杂问题,进化代数可以相应地提高;
惯性权重:该参数反映了个体历史成绩对现在的影响,一般取0.5~1;
学习因子:一般取0~4,此处要根据自变量的取值范围来定,并且学习因子分为个体和群体两种;
空间维数:粒子搜索的空间维数即为自变量的个数。
位置限制:限制粒子搜索的空间,即自变量的取值范围,对于无约束问题此处可以省略。
速度限制:如果粒子飞行速度过快,很可能直接飞过最优解位置,但是如果飞行速度过慢,会使得收敛速度变慢,因此设置合理的速度限制就很有必要了。
clc;clear;close all;
%% 初始化种群
%已知位置限制[0,20],由于一维问题较为简单,因此可以取初始种群N 为50,迭代次数为100,当然空间维数d 也就是1。位置和速度的初始化即在位置和速度限制内随机生成一个N x d 的矩阵,对于此题,位置初始化也就是在0~20内随机生成一个50x1的数据矩阵,而对于速度则不用考虑约束,一般直接在0~1内随机生成一个50x1的数据矩阵。
%此处的位置约束也可以理解为位置限制,而速度限制是保证粒子步长不超限制的,一般设置速度限制为[-1,1]。
%粒子群的另一个特点就是记录每个个体的历史最优和种群的历史最优,因此而二者对应的最优位置和最优值也需要初始化。其中每个个体的历史最优位置可以先初始化为当前位置,而种群的历史最优位置则可初始化为原点。对于最优值,如果求最大值则初始化为负无穷,相反地初始化为正无穷。
%每次搜寻都需要将当前的适应度和最优解同历史的记录值进行对比,如果超过历史最优值,则更新个体和种群的历史最优位置和最优解。
%点乘对应的是矩阵中元素的相乘,这就需要两个矩阵的维度一定要相同才可以
%函数句柄的写法
f= @(x)x .* sin(x) .* cos(2 * x) - 2 * x .* sin(3 * x); % 函数表达式
figure(1);
ezplot(f,[0,0.01,20]);
% 函数ezplot无需数据准备,可以直接画出函数的图形,画隐函数图形很方便。
N = 50; % 初始种群个数
d = 1; % 空间维数
ger = 100; % 最大迭代次数
limit = [0, 20]; % 设置位置参数限制
vlimit = [-1, 1]; % 设置速度限制
w = 0.8; % 惯性权重
c1 = 0.5; % 自我学习因子,一般为2
c2 = 0.5; % 群体学习因子 ,一般为2
for i = 1:d
x = limit(i, 1) + (limit(i, 2) - limit(i, 1)) * rand(N, d);
%初始种群的位置,limit表示第一个参数表达式在自变量趋于第二个参数的极限值
end
v = rand(N, d); % 初始种群的速度
xm = x; % 每个个体的历史最佳位置
ym = zeros(1, d); % 种群的历史最佳位置
fxm = zeros(N, 1); % 每个个体的历史最佳适应度
fym = -inf; % 种群历史最佳适应度
hold on
plot(xm, f(xm), 'ro');title('初始状态图');
% figure(2)
%% 群体更新
iter = 1;
record = zeros(ger, 1); % 记录器
while iter <= ger
fx = f(x) ; % 个体当前适应度
for i = 1:N
if fxm(i) < fx(i)
fxm(i) = fx(i); % 更新个体历史最佳适应度
xm(i,:) = x(i,:); % 更新个体历史最佳位置
end
end
if fym < max(fxm)
[fym, nmax] = max(fxm); % 更新群体历史最佳适应度,
% 该方法能够记录下每列的最大值和其对应的索引位置
ym = xm(nmax, :); % 更新群体历史最佳位置
end
v = v * w + c1 * rand * (xm - x) + c2 * rand * (repmat(ym, N, 1) - x);% 速度更新
% 边界速度处理
v(v > vlimit(2)) = vlimit(2);
v(v < vlimit(1)) = vlimit(1);
x = x + v;% 位置更新
% 边界位置处理
x(x > limit(2)) = limit(2);
x(x < limit(1)) = limit(1);
record(iter) = fym;%最大值记录
% x0 = 0 : 0.01 : 20;
% plot(x0, f(x0), 'b-', x, f(x), 'ro');title('状态位置变化')
% pause(0.1)
iter = iter+1;
end
figure(3);plot(record);title('收敛过程')
x0 = 0 : 0.01 : 20;
hold off
figure(4);plot(x0, f(x0), 'b-', x, f(x), 'ro');title('最终状态位置')
disp(['最大值:',num2str(fym)]);
disp(['变量取值:',num2str(ym)]);
结果显示:

重点二:二维的粒子群算法求解
1.建一个函数文件fitnessrevisemodel.m,里面的内容如下:
%目标是求解:方程组:0.4 * (x - 5)^2 + 0.3 * (y - 6)^2 - 0.2 ; x,y的范围:[-100,100], 这个时候目标就是求最小值了
function y = fitnessrevisemodel(x)
%函数用于计算粒子适应度值
%x input 输入粒子
%y output 粒子适应度值
y = 0.4 * (x(1)-5)^2 + 0.3*(x(2)-6)^2 - 0.2;
end2.建一个二维的粒子群算法文件twodimension.m,内容如下:
D=2; %维数 一般是自变量个数 此时速度与位置都用两个变量表示
w = 1; %动力常量
NP=12; %种群规模 D的五倍到十倍
%学习因子c1 c2 范围在0-4
c1 = 1.5;
c2 = 1.5;
gen_max=1000; %最大进化代数
bounds_p=ones(D,2); %定义位置的取值边界
bounds_p(:,1)=-100; %取值下界
bounds_p(:,2)=100; % 取值上界
bounds_v=ones(D,2); %定义速度的取值边界
bounds_v(:,1)=-100; %取值下界
bounds_v(:,2)=100; % 取值上界
%%
x=ones(NP,1)*bounds_p(:,1)'+(ones(NP,1)*(bounds_p(:,2)'-bounds_p(:,1)')) .*(rand(NP,D));%初始种群位置信息,使位置都位于最大值与最小值间,最后形成NP行2列的矩阵
v=ones(NP,1)*bounds_v(:,1)'+(ones(NP,1)*(bounds_v(:,2)'-bounds_v(:,1)')) .*(rand(NP,D));%初始种群速度信息,使位置都位于最大值与最小值间,最后形成NP行2列的矩阵
count=1; %进化代数
cost=zeros(NP,1); %存放个体的适应值,初始化为NP行一列的零矩阵
cost(1)=fitnessrevisemodel(x(1,:)); %计算第一个个体适应值
fitness_zbest=cost(1); %存放全局最优值,假设第一个个体便是最优值
zbest=x(1,:); %存放全局对应最优值的解
for i2=2:NP %计算初始种群中的最优值和最优值对应的解
cost(i2)=fitnessrevisemodel(x(i2,:));
if(cost(i2)<= fitness_zbest)
fitness_zbest=cost(i2);
zbest=x(i2,:);
end
end
gbest = x; %存放个体最优值,因为此时个体仅仅产生了一次,所以就取当前这一次为最优值
fitness_gbest = cost; %存放个体最优适应值,因为此时个体仅仅产生了一次,所以就取当前这一次为最优适应值
%粒子群算法
while(count<gen_max) %循环终止条件是达到最大的进化代数
for i2=1:NP
%速度更新
v(i2,:) = w * v(i2, :) + c1 * rand * (gbest(i2, :) - x(i2, :)) + c2 * rand * (zbest - x(i2, :)); %速度更新公式,考虑个体最优值与总体最优值
v(i2, find(v(i2, :) > 100)) = 100; %如果第i2个个体的速度(用一行两列矩阵表示,这一行任一列大于100均要改变)大于最大速度100,即改为100
v(i2, find(v(i2, :) < -100)) = -100; %如果第i2个个体的速度(用一行两列矩阵表示,这一行任一列小于-100均要改变)小于最小速度100,即改为-100
% %位置更新
x(i2, :) = x(i2, :) + v(i2, :); %速度更新公式
x(i2, find(x(i2, :) > 100)) = 100;
x(i2, find(x(i2, :) < -100)) = -100;
%
%自适应变异(避免算法陷入局部最优)
if rand > 0.8
k = ceil(2 * rand);
x(i2, k) = rand;
end
%
%因为上述的x的第i2个个体更新,所以第i2个个体适应值也要更新
cost(i2) = fitnessrevisemodel(x(i2, :));
%
% %如果个体适应值小于即优于原来该最优个体适应值
if cost(i2) < fitness_gbest(i2)
gbest(i2, :) = x(i2, :); %更新该个体最优值
fitness_gbest(i2) = cost(i2); %更新个体最优适应值
end
% %如果个体适应值比总体最优适应值小,更新
if cost(i2) < fitness_zbest
zbest = cost(i2, :); %存放新的全局最优值
fitness_zbest = cost(i2); %存放新的全局最优适应值
end
end
yy(count) = fitness_zbest; %记录每一次迭代后的新的全局最优适应值,理论上迭代结束后,最后一次的yy(count)即为所求值
count = count + 1;
end
plot(yy);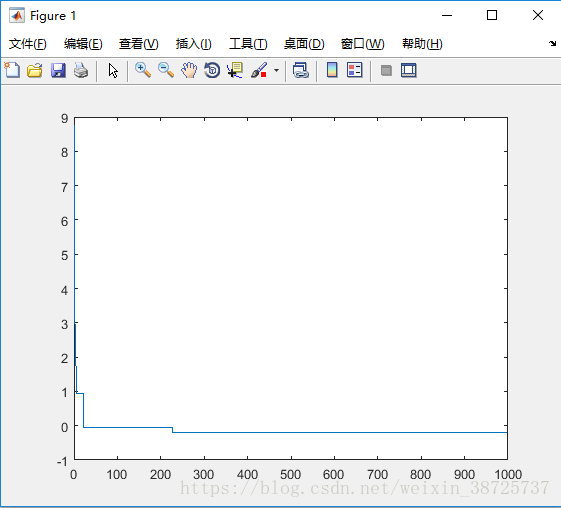
综上所述,我们还可以查看博客地址:https://blog.csdn.net/LSGO_MYP/article/details/70945873
这里对自适应变异用在粒子群算法中有涉及。