【简单理解】自然语言处理-平滑方法(Smoothing)
简单介绍平滑策略
平滑策略的引入,主要使为了解决语言模型计算过程中出现的零概率问题。零概率问题又会对语言模型中N-gram模型的Perplexity评估带来困难。
零概率问题,就是在计算实例的概率时,如果某个量x,在观察样本库(训练集)中没有出现过,那么该量概率为0,进而会导致整个实例的概率结果是0。
举例:在文本分类的问题中,在计算一句话的概率时,的当一个词语没有在训练样本中出现,该词语的概率为0,使用连乘计算文本出现概率时也为0。这是不合理的,不能因为一个事件没有观察到就武断的认为该事件的概率是0。
主流平滑方法
- Additive smoothing
- Good-Turing estimate
- Jelinek-Mercer smoothing (interpolation)
Additive smoothing
Add-one smoothing
也叫拉普拉斯平滑,下面以 bigram model 为例给出加 1 平滑的模型。
MLE estimate:

Add-1 estimate:

加1平滑通常情况下是一种不算很好的算法,与其他平滑方法相比显得非常差,然而我们可以把加 1 平滑用在其他任务中,如文本分类,或者非零计数没那么多的情况下。
Additive smoothing
对加 1 平滑的改进就是把 1 改成 δ,且 0<δ≤10<δ≤1。
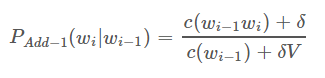
Good-Turing smoothing
基本思想: 用观察计数较高的 N-gram 数量来重新估计概率量大小,并把它指派给那些具有零计数或较低计数的 N-gram
Idea: reallocate the probability mass of n-grams that occur r+1 times in the training data to the n-grams that occur r times.
一般情况下,我们选出现过一次的概率,也就是 Things seen once 这一概念:
Things seen once: 使用刚才已经看过一次的事物的数量来帮助估计从来没有见过的事物的数量。举个例子,假设你在钓鱼,然后抓到了 18 条鱼,种类如下:10 carp, 3 perch, 2 whitefish, 1 trout, 1 salmon, 1 eel,那么
下一条鱼是 trout 的概率是多少?
很简单,我们认为是 1/18
那么,下一条鱼是新品种的概率是多少?
不考虑其他,那么概率是 0,然而根据 Things seen once 来估计新事物,概率是 3/18
在此基础上,下一条鱼是 trout 的概率是多少?
肯定就小于 1/18,那么怎么估计呢?
在 Good Turing 下,对每一个计数 r,我们做一个调整,变为 r*,公式如下,其中 nrnr 表示出现过 r 次的 n-gram。
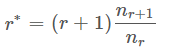
然后,我们就有
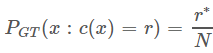
所以,c=1时,
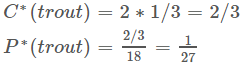
问题
然后,问题来了,如果怎么办?这在 r 很高的情况下很常见,因为在对计数进行计数时(counts of counts),会出现 “holes”。即使没有这个 hole,对很高的 r 来说,
也是有噪音的(noisy)。
所以,我们应该这样来看 :
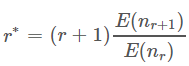
Interpolation(差值)
差值,简单来讲,就是把不同阶的模型结合起来:
用线性差值把不同阶的 N-gram 结合起来,这里结合了 trigram,bigram 和 unigram。用 lambda 进行加权:

