上一节介绍了输入/输出流的4个抽象基类,并介绍了4个访问文件的节点流的用法。通过上面示例程序不难发现,4个基类使用起来有些烦琐。如果希望简化编程,这就需要借助于处理流了。
1、处理流的用法
使用处理流时的典型思路是,使用处理流来包装节点流,程序通过处理流来执行输入出功能,让节点流与底层的I/O设备、文件交互。
实际识别处理流非常简单,只要流的构造器参数不是一个物理节点,而是已经存在的流,那么这种流就一定是处理流;而所有节点流都是直接以物理 IO 节点作为构造器参数的。
提示:关于使用处理流的优势,归纳起来就是两点:①对开发人员来说,使用处理流进行输入/输出操作更简单;②使用处理流的执行效率更高.
下面程序使用 PrintStream 处理流来包装 OutputStream,使用处理流后的输出流在输出时将更加方便。
public class PrintStreamTest { public static void main(String[] args) { try (FileOutputStream fos = new FileOutputStream("test.txt"); PrintStream ps = new PrintStream(fos)) { // 使用PrintStream执行输出 ps.println("普通字符串"); // 直接使用PrintStream输出对象 ps.println(new PrintStreamTest()); } catch (IOException ioe) { ioe.printStackTrace(); } } }
上面程序中的两行粗体字代码先定义了一个节点输出流 FileOutputStream,然后程序使用 PrintStream 包装了该节点输出流,最后使用 PrintStream 输出字符串、输出对象......PrintStream 的输出功能非常强大,前面程序中一直使用的标准输出 System.out 的类型就是 PrintStream。
提示:由于 PrintStream 类的输出功能非常强大,通常如果需要输出文本内容,都应该将输出流包装成 PrintStream 后进行输出。
从前面的代码可以看出,程序使用处理流非常简单,通常只需要在创建处理流时传入一个节点流作为构造器参数即可,这样创建的处理流就是包装了该节点流的处理流。
注意:在使用处理流包装了底层节点流之后,关闭输入/输出流资源时,只要关闭最上层的处理流即可。关闭最上层的处理流时,系统会自动关闭被该处理流包装的节点流。
2、输入/输出流体系
Java 的输入/输出流体系提供了近40个类,这些类看上去杂乱而没有规律,但如果将其按功能进行分类,则不难发现其是非常规律的。下图显示了Java 输入/输出流体系中常用的流分类。
从图中可以看出,Java 的输入/输出流体系之所以如此复杂,主要是因为 Java 为了实现更好的设计,它把流按功能分成了许多类,而每类中又分别提供了字节流和字符流(当然有些流无法提供字节流,有些流无法提供字符流),字节流和字符流里又分别提供了输入流和输出流两大类,所以导致整个输入/输出流体系格外复杂。
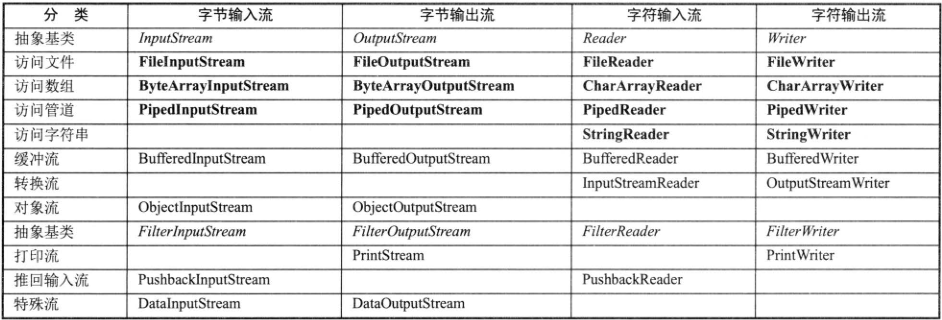
注意:粗体字标出的类代表节点流,必须直接与指定的物理节点关联;斜体字标出的类代表抽象基类,无法直接刨建实例。
通常来说,字节流的功能比字符流的功能强大,因为计算机里所有的数据都是二进制的,而字节流可以处理所有的二进制文件一一但问题是,如果使用字节流来处理文本文件,则需要使用合适的方式把这些字节转换成字符,这就增加了编程的复杂度。所以通常有一个规则:如果进行输入/输出的内容是文本内容,则应该考虑使用字符流:如果进行输入/输出的内容是二进制内容,则应该考虑使用字节流。
上图仅仅总结了输入/输出流体系中位于 java.io 包下的流,还有一些诸如 AudioInputStream、CipherInputStream、DeflaterInputStream、ZipInputStream 等具有访问音频文件、加密/解密、压缩/解压等功能的字节流,它们具有特殊的功能,位于 JDK 的其他包下。
上图还列出了一种以数组为物理节点的节点流,字节流以字节数组为节点,字符流以字符数组为节点;这种以数组为物理节点的节点流除在创建节点流对象时需要传入一个字节数组或者字符数组之外,用法上与文件节点流完全相似。与此类似的是,字符流还可以使用字符串作为物理节点,用于实现从字符串读取内容,或将内容写入字符串(用StringBuffer充当字符串)的功能。下面程序示范了使用字符串作为物理节点的字符输入/输出流的用法。
public class StringNodeTest { public static void main(String[] args) { String src = "从明天起,做一个幸福的人\n" + "喂马,劈柴,周游世界\n" + "从明天起,关心粮食和蔬菜\n" + "我有一所房子,面朝大海,春暖花开\n" + "从明天起,和每一个亲人通信\n" + "告诉他们我的幸福\n"; char[] buffer = new char[32]; int hasRead = 0; try (StringReader sr = new StringReader(src)) { // 采用循环读取的访问读取字符串 while ((hasRead = sr.read(buffer)) > 0) { System.out.print(new String(buffer, 0, hasRead)); } } catch (IOException ioe) { ioe.printStackTrace(); } try ( // 创建StringWriter时,实际上以一个StringBuffer作为输出节点 // 下面指定的20就是StringBuffer的初始长度 StringWriter sw = new StringWriter()) { // 调用StringWriter的方法执行输出 sw.write("有一个美丽的新世界,\n"); sw.write("她在远方等我,\n"); sw.write("哪里有天真的孩子,\n"); sw.write("还有姑娘的酒窝\n"); System.out.println("----下面是sw的字符串节点里的内容----"); // 使用toString()方法返回StringWriter的字符串节点的内容 System.out.println(sw.toString()); } catch (IOException ex) { ex.printStackTrace(); } } }
上面程序与前面使用 FileReader 和 FileWriter 的程序基本相似,只是在创建 StringReader 和 StringWriter 对象时传入的是字符串节点,而不是文件节点。由于 String 是不可变的字符串对象,所以 StringWriter 使用 StringBuffer 作为输出节点。
上图列出了4个访问管道的流:Pipedlnputstream、PipedOutputStream、PipedReader、PipedWriter,它们都是用于实现进程之间通信功能的,分别是字节输入流、字节输出流、字符输入流和字符输出流。
上图中的4个缓冲流则增加了缓冲功能,增加缓冲功能可以提高输入、输出的效率,增加缓冲功能后需要使用 flush() 才可以将缓冲区的内容写入实际的物理节点。
上图中的对象流主要用于实现对象的序列化。
3、转换流
输入/输出流体系中还提供了两个转换流,这两个转换流用于实现将字节流转换成字符流,其中 InputStreamReader 将字节输入流转换成字符输入流,OutputStreamWriter 将字节输出流转换成字符输出流。
下面以获取键盘输入为例来介绍转换流的用法。Java 使用 System.in 代表标准输入,即键盘输入,但这个标准输入流是 InputStream 类的实例,使用不太方便,而且键盘输入内容都是文本内容,所以可以使用 InputStreamReader 将其转换成字符输入流,普通的 Reader 读取输入内容时依然不太方便,可以将普通的 Reader 再次包装成 BufferedReader,利用 BufferedReader 的 readLine() 方法可以一次读取一行内容。如下程序所示。
public class KeyinTest { public static void main(String[] args) { try ( // 将Sytem.in对象转换成Reader对象 InputStreamReader reader = new InputStreamReader(System.in); // 将普通Reader包装成BufferedReader BufferedReader br = new BufferedReader(reader)) { String line = null; // 采用循环方式来一行一行的读取 while ((line = br.readLine()) != null) { // 如果读取的字符串为"exit",程序退出 if (line.equals("exit")) { System.exit(1); } // 打印读取的内容 System.out.println("输入内容为:" + line); } } catch (IOException ioe) { ioe.printStackTrace(); } } }
上面程序中的粗体字代码负责将 System.in 包装成 BufferedReader,BufferedReader 流具有缓冲功能,它可以一次读取一行文本一一以换行符为标志,如果它没有读到换行符,则程序阻塞,等到读到换行符为止。运行上面程序可以发现这个特征,在控制台执行输入时,只有按下回车键,程序才会打印出刚刚输入的内容。
提示:由于 BufferedReader 具有一个 readLine() 方法,可以非常方便地一次读入一行内容,所以经常把读取文本内容的输入流包装成 BufferedReader,用来方便地读取输入流的文本内容。
4、推回输入流
在输入/输出流体系中,有两个特殊的流与众不同,就是 PushbackInputStream 和 PushbackReader,它们都提供了如下三个方法。
- void unread(byte[]/char[] buf):将一个字节/字符数组内容推回到推回缓冲区里,从而允许重复读取刚刚读取的内容。
- void unread(byte[]/char[] b, int off, int len):将一个字节/字符数组里从 off 开始,长度为 len 字节/字符的内容推回到推回缓冲区里,从而允许重复读取刚刚读取的内容。
- void unread(int b):将一个字节/字符推回到推回缓冲区里,从而允许重复读取刚刚读取的内容。
细心的人可能已经发现了这三个方法与 InputStream 和 Reader 中的三个 read() 方法一一对应,没错,这三个方法就是 PushbackInputStream 和 PushbackReader 的奥秘所在。
这两个推回输入流都带有一个推回缓冲区,当程序调用这两个推回输入流的 unread() 方法时,系统将会把指定数组的内容推回到该缓冲区里,而推回输入流每次调用 read() 方法时总是先从推回缓冲区读取,只有完全读取了推回缓冲区的内容后,但还没有装满 read() 所需的数组时才会从原输入流中读取。
下图显示了这种推回输入流的处理示意图。
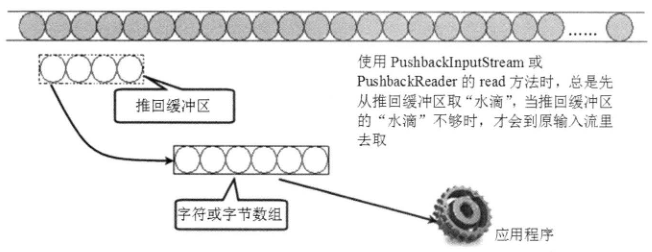
根据上面的介绍可以知道,当程序创建一个 PushbackInputStream 和 PushbackReader 时需要指定推回缓冲区的大小,默认的推回缓冲区的长度为1。如果程序中推回到推回缓冲区的内容超出了推回缓冲区的大小,将会引发 Pushback buffer overflow 的 IOException 异常。
注意:虽然上图中的推回缓冲区的长度看似比 read() 方法的数组参数的长度小,但实际上,推回缓冲区的长度与 read() 方法的数组参数的长度没有任何关系,完全可以更大。
下面程序试图找出程序中的"new PushbackReader"字符串,当找到该字符串后,程序只是打印出目标字符串之前的内容。
public class PushbackTest { public static void main(String[] args) { try ( // 创建一个PushbackReader对象,指定推回缓冲区的长度为64 PushbackReader pr = new PushbackReader(new FileReader("PushbackTest.java"), 64)) { char[] buf = new char[32]; // 用以保存上次读取的字符串内容 String lastContent = ""; int hasRead = 0; // 循环读取文件内容 while ((hasRead = pr.read(buf)) > 0) { // 将读取的内容转换成字符串 String content = new String(buf, 0, hasRead); int targetIndex = 0; // 将上次读取的字符串和本次读取的字符串拼起来, // 查看是否包含目标字符串, 如果包含目标字符串 if ((targetIndex = (lastContent + content).indexOf("new PushbackReader")) > 0) { // 将本次内容和上次内容一起推回缓冲区 pr.unread((lastContent + content).toCharArray()); // 重新定义一个长度为targetIndex的char数组 if (targetIndex > 32) { buf = new char[targetIndex]; } // 再次读取指定长度的内容(就是目标字符串之前的内容) pr.read(buf, 0, targetIndex); // 打印读取的内容 System.out.print(new String(buf, 0, targetIndex)); System.exit(0); } else { // 打印上次读取的内容 System.out.print(lastContent); // 将本次内容设为上次读取的内容 lastContent = content; } } } catch (IOException ioe) { ioe.printStackTrace(); } } }
上面程序中的粗体字代码实现了将指定内容推回到推回缓冲区,于是当程序再次调用 read() 方法时,实际上只是读取了推回缓冲区的部分内容,从而实现了只打印目标字符串前面内容的功能。