文章目录
一.流概念的细分
流的概念
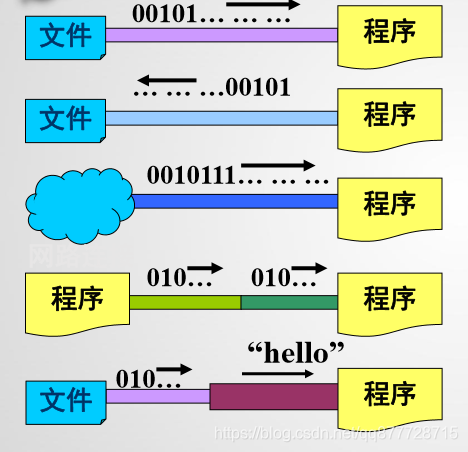
- 流(Stream)是一个抽象的概念,当
程序需要读取数据的时候,就会开启一个通向数据源的流,数据源可以是文件,内存,或是网络连接。反过来,当程序需要写入数据的时候,就会开启一个通向目的地的流。 javaIO流相关的类位于 java.io包中
流的分类
1.流的方向
- 按
流的方向,可以分为输入流/输出流
| 类型 | 说明 |
|---|---|
| 输入流 | 数据流向是数据源到程序(以InputStream、Reader结尾的流)。 |
| 输出流 | 数据流向是程序到目的地(以OutputStream、Writer结尾的流)。 |
2.数据单元
- 按处理的
数据单元可以分为字节流/字符流
| 类型 | 说明 |
|---|---|
| 字节流 | 以字节为单位获取数据,命名上以Stream结尾的流一般是字节流,如FileInputStream、FileOutputStream。字节流可以处理任何一切形式的数据源,包括音频,视频,图片,纯文本,Word,Excel等等 |
| 字符流 | 以字符为单位获取数据,命名上以Reader/Writer结尾的流一般是字符流,如FileReader、FileWriter。字符流只能处理字符串,纯文本等。 Java中的字符是Unicode编码,一个字符占用两个字节。 |
3.处理对象
- 按
处理对象不同可以分为节点流/处理流(也叫过滤流、包装流)
| 类型 | 说明 |
|---|---|
| 节点流 | 可以直接从数据源或目的地读写数据,如FileInputStream、FileReader、DataInputStream等。( 没有节点流,处理流发挥不了任何作用。) |
| 处理流 | 不直接连接到数据源或目的地,是”处理流的流”。通过对已有的节点流进行包装,提高性能或提高程序的灵活性。如BufferedInputStream、BufferedReader等。处理流也叫 包装流/过滤流。 |
4.I/O类型
- 按
I/O类型来分类
| 类型 | 说明 |
|---|---|
| 文件流 | 对文件进行读、写操作 :FileReader、FileWriter、FileInputStream、FileOutputStream |
| 缓冲流 | 在读入或写出时,数据可以基于缓冲批量读写,以减少I/O的次数:BufferedReader、BufferedWriter、BufferedInputStream、BufferedOutputStream |
| 内存流 | 1.从/向内存数组读写数据: CharArrayReader、 CharArrayWriter、ByteArrayInputStream、ByteArrayOutputStream 2.从/向内存字符串读写数据 StringReader、StringWriter、StringBufferInputStream |
| 转换流 | 按照一定的编码/解码标准将字节流转换为字符流,或进行反向转换(Stream到Reader,Writer的转换类):InputStreamReader、OutputStreamWriter |
| 对象流 | 字节流与对象实例相互转换,实现对象的序列化 :ObjectInputStream、ObjectOutputStream 注意: 1.读取顺序和写入顺序一定要一致,不然会读取出错。 2.在对象属性前面加 transient关键字,则该对象的属性不会被序列化 |
| 打印流 | 只有输出,没有输入,在整个IO包中,打印流是输出信息最方便的类,分为 PrintWriter(字符打印流)、PrintStream(字节打印流) |
| DataConversion数据流 | 按基本数据类型读/写,可以字节流与基本类型数据相互转换:DataInputStream、DataOutputStream |
| 过滤流 | 在数据进行读或写时进行过滤:FilterReader、FilterWriter、FilterInputStream、FilterOutputStream |
| 合并流 | 把多个输入流按顺序连接成一个输入流 :SequenceInputStream |
| 操作ZIP包流 | ZipInputStream可以读取zip格式的流,ZipOutputStream可以把多份数据写入zip包 |
| 操作JAR包流 | JarInputStream/JarOutputStream,派生自ZipInputStream/ZipOutputStream,它增加的主要功能是直接读取jar文件里面的MANIFEST.MF文件。因为本质上jar包就是zip包,只是额外附加了一些固定的描述文件。 |
| 管道流 | 线程交互的时候使用,管道输出流可以连接到管道输入流,以创建通信管道。管道输出流是管道的发送端。通常数据由某个线程写入管道输出流,并由其他线程从连接的管道输入流读取。注意,管道输出流和输入流需要对接。: PipedReader、PipedWriter、PipedInputStream、PipedOutputStream |
| Counting计数 | 在读入数据时对行记数 :LineNumberReader、LineNumberInputStream |
| 推回输入流 | 通过缓存机制,进行预读 :PushbackReader、PushbackInputStream |
| 接收和响应客户端请求流 | servletinputstream:用来读取客户端的请求信息的输入流 servletoutputstream:可以将数据返回到客户端 |
| 随机读取写入流 | RandomAccessFile 既可以读取文件内容,也可以向文件输出数据,RandomAccessFile 对象包含一个记录指针,标识当前读写处的位置,可以控制记录指针从IO任何位置读写文件 |
| 加密流 | 对流加密/解密 CipherOutputStream 由一个 OutputStream 和一个 Cipher 组成 ,write() 方法在将数据写出到基础 OutputStream 之前先对该数据进行处理(加密或解密) , 同样CipherInputStream是由InputStream和一个Cipher组成,read()方法在读入时,对数据进行加解密操作. |
| 数字签名流 | DigestInputStream : 最大的特点是在读取的数据的时候已经调用MessageDigest实例的update方法,当数据从底层的数据流中读取之后就只可以直接调用MessageDigest实例的digest()方法了,从而完成对输入数据的摘要加密 DigestOutputStream :最大的特点是在向底层的输出流写入数据的时候已经调用MessageDigest实例的update方法,并作为MessageDigest的输入数据,之后就可以直接调用MessageDigest实例的digest()方法完成加密过程;同样的,是否对数据加密也是由该流的on(boolean b)方法进行控制的,如果设置成false,那么在写出数据的过程中便不会将数据传给update方法,那么此时它跟普通的输出流就没有任何区别了。 |
CipherInputStream和CipherOutputStream与DigestInputStream/DigestOutputStream/类似,只是后者更为彻底,它们不用在显示地调用传入的Cipher对象的update和doFinal方法,加密或解密过程在读写数据的同时已经隐式地完成了
5.数据源
- 按
数据源分类
| 数据源形式 | InputStream | OutputStream | Reader | Writer |
|---|---|---|---|---|
| ByteArray(字节数组) | ByteArrayInputStream | ByteArrayOutputStream | 无 | 无 |
| File(文件) | FileInputStream | FileOutputStream | FileReader | FileWriter |
| Piped(管道) | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter |
| Object(对象) | ObjectInputStream | ObjectOutputStream | 无 | 无 |
| String (字符串) | StringBufferInputStream | 无 | StringReader | StringWriter |
| CharArray(字符数组) | 无 | 无 | CharArrayReader | CharArrayWriter |
- 使用字节流还是使用字符流
- 字节流读取数据时,读到一个字节就返回一个字节。
字符流使用了字节流读到一个或多个字节(中文对应的字节是两个,UTF-8码表中是三个)时,先去查指定的编码表,将查到的字符返回 - 硬盘上的所有文件都是以
字节流的形式进行传输或者保存的,字符只是在内存中才会形成的,所以在开发中,字节流使用广泛。但是如果只是处理存文本数据,优先考虑使用字符流。
- 字节流读取数据时,读到一个字节就返回一个字节。
二.IO流体系
IO体系图
下图基于Java 1.8制作,其中需要注意的是StringBufferInputStream和LineNumberInputStream已被废弃。
- StringBufferInputStream : 该类无法准确的将字符转换为字节,推荐用
StringReader来取代使用。 - LineNumberInputStream : 该类错误地认为字节能恰当地表示字符,推荐使用
字符流的类来取代,即LineNumberReader。
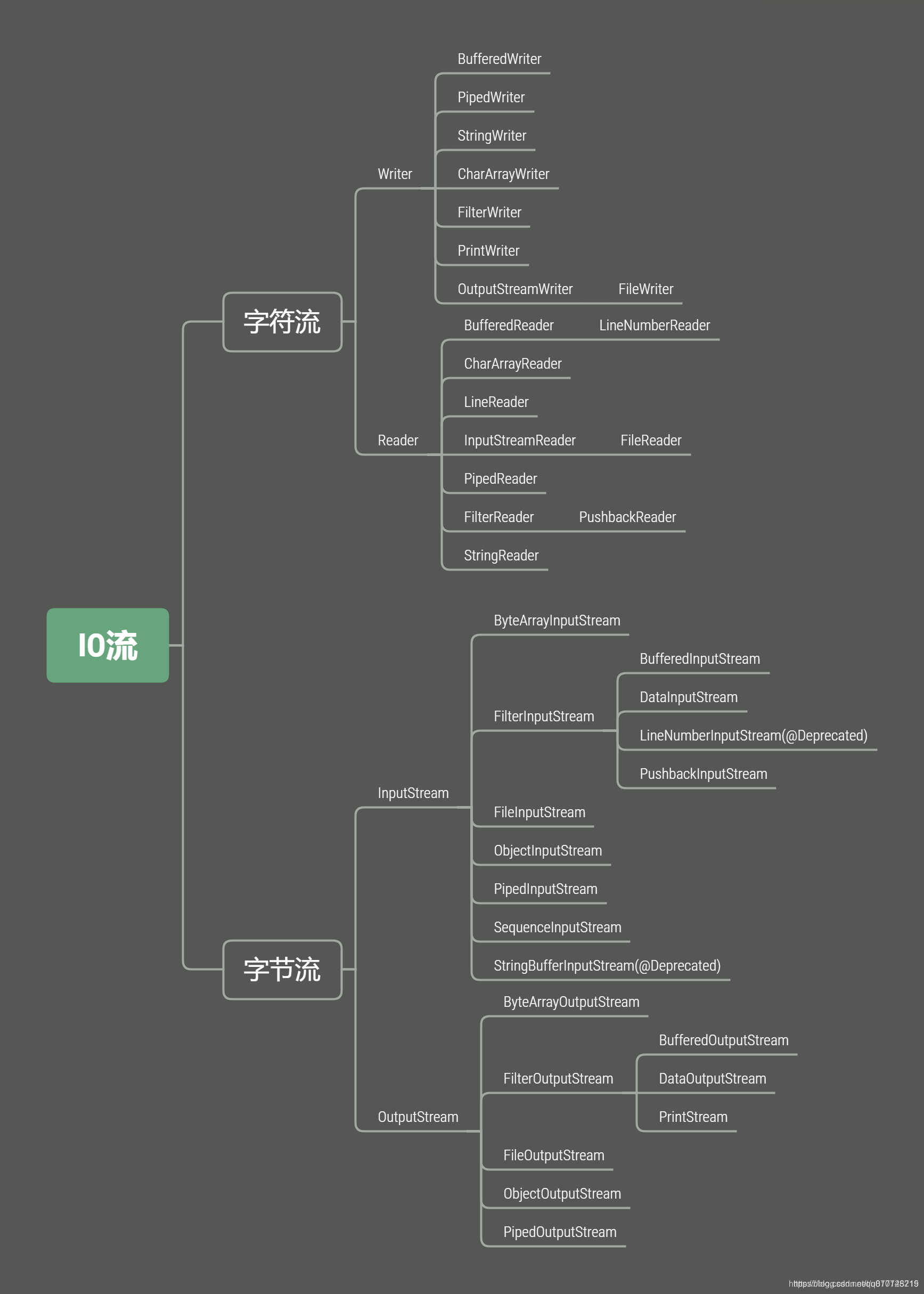
从图中可以发现IO流是成对出现的,有有输入流就会有对应的输出流
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
|---|---|---|---|---|
抽象基类 |
InputStream | OutputStream | Reader | Writer |
| 访问文件 | FileInputStream | FileOutputStream | FileReader | FileWriter |
| 访问数组 | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter |
| 访问管道 | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter |
| 访问字符串 | StringReader | StringWriter | ||
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| 转换流 | InputStreamReader | OutputStreamWriter | ||
| 对象流 | ObjectInputStream | ObjectOutputStream | ||
抽象基类 |
FilterInputStream | FilterOutputStream | FilterReader | FilterWriter |
| 打印流 | PrintStream | PrintWriter | ||
| 推回输入流 | PushbackInputStream | PushbackReader | ||
| 特殊流 | DataInputStream | DataOutputStream |
注:表中
粗体所表示的类代表节点流,斜体表示的类代表抽象基类,无法直接创建实例。其他的为处理流
IO流的主要类
在整个Java.io包中最重要的就是5个类和一个接口。
- 5个类指的是
| 类 | 说明 |
|---|---|
| File | 表示一个文件或者目录,可以获取文件或目录相关属性,以及创建文件或目录 |
| InputStream | 字节输入流父类,单位为字节,定义了所有字节输入流的基本操作 |
| OutputStream | 字节输出流父类,单位为字节,定义了所有字节输出流的基本操作 |
| Reader | 字符输入流父类,单位为字符,定义了所有字符输入流的基本操作 |
| Writer | 字符输出流父类,单位为字符,定义了所有字符输出流的基本操作 |
Java中所有流流均是由它们派生出来的:
JDK1.4版本开始引入了新I/O类库,它位于java.nio包中,新I/O类库利用通道和缓冲区等来提高I/O操作的效率
- 一个接口指的是
| 类 | 说明 |
|---|---|
| Serializable | 序列化/反序列化对象需要实现 Serializable接口 |
- Java I/O主要包含三个部分:
| 部分 | 说明 |
|---|---|
| 流式部分 | IO的主体部分 |
| 非流式部分 | 主要包含一些辅助流式部分的类,如:File类、RandomAccessFile类和FileDescriptor等类 RandomAccessFile(随机读取和写入流)可以从文件的任意位置进行读写) |
| 其他类 | 文件读取部分的与安全相关的类,如:SerializablePermission类,以及与本地操作系统相关的文件系统的类,如:FileSystem类和Win32FileSystem类和WinNTFileSystem类 |
-
RandomAccessFile描述
- 是Java输入/输出流体系中功能最丰富的文件内容访问类,
既可以读取文件内容,也可以向文件输出数据。 - 与普通的输入/输出流不同的是,RandomAccessFile
支持跳到文件任意位置读写数据 - RandomAccessFile对象包含一个
记录指针,标识当前读写处的位置,当程序创建一个新的RandomAccessFile对象时,该对象的文件记录指针对于文件头(也就是0处),当读写n个字节后,文件记录指针将会向后移动n个字节,RandomAccessFile可以通过seek()方法自由移动记录指针
- 是Java输入/输出流体系中功能最丰富的文件内容访问类,
-
RandomAccessFile通过两个方法来操作文件记录指针
- long getFilePointer():返回文件记录指针的当前位置
- void seek(long pos):将文件记录指针定位到pos位置
-
RandomAccessFile类在创建对象时,除了指定文件本身,还需要指定一个
mode参数
该参数指定RandomAccessFile的访问模式,该参数有如下四个值:- r:以只读方式打开指定文件。如果试图对该RandomAccessFile指定的文件执行写入方法则会抛出IOException
- rw:以读取、写入方式打开指定文件。如果该文件不存在,则尝试创建文件
- rws:以读取、写入方式打开指定文件。相对于rw模式,还要求对文件的内容或元数据的每个更新都同步写入到底层存储设备,默认情形下(rw模式下),是使用buffer的,只有cache满的或者使用RandomAccessFile.close()关闭流的时候儿才真正的写到文件
- rwd:与rws类似,只是仅对文件的内容同步更新到磁盘,而不修改文件的元数据
三.常用的io流的用法
字节流和字符流的操作方式基本一致,只是操作的数据单元不同——字节流的操作单元是字节,字符流的操作单元是字符。所以字节流和字符流就整理在一起了。
InputStream和Reader
-
InputStream(字节输入流)和Reade(字符输入流),不是一个接口,而是所有输入流的抽象父类,本身并不能创建对象来执行输入,但它是所有输入流的模板,它的方法是所有输入流都可使用的方法。 -
在
InputStream里面包含如下3个方法。
| 方法 | 说明 |
|---|---|
| int read() | 从输入流中读取单个字节(相当于从水管中取出一滴水),返回所读取的字节数据(字节数据可直接转换为int类型) |
| int read(byte[] b) | 从输入流中最多读取b.length个字节的数据,并将其存储在字节数组b中,返回实际读取的字节数。 |
| int read(byte[] b,int off,int len) | 从输入流中最多读取len个字节的数据,并将其存储在字节数组b中,放入字节数组b中时,并不是从数组起点开始,而是从off位置开始,返回实际读取的字节数 |

- 在
Reader里面包含如下3个方法。
| 方法 | 说明 |
|---|---|
| int read() | 从输入流中读取单个字符(相当于从水管中取出一滴水),返回所读取的字符数据(字节数据可直接转换为int类型) |
| int read(char[] b) | 从输入流中最多读取b.length个字符的数据,并将其存储在字符数组b中,返回实际读取的字符数 |
| int read(char[] b,int off,int len) | 从输入流中最多读取len个字符的数据,并将其存储在字符数组b中,放入字符数组b中时,并不是从数组起点开始,而是从off位置开始,返回实际读取的字符数 |
- InputStream和Reader提供的一些移动指针的方法:
| 方法 | 说明 |
|---|---|
| void mark(int readAheadLimit) | 在记录指针当前位置记录一个标记(mark) |
| boolean markSupported() | 判断此输入流是否支持mark()操作,即是否支持记录标记 |
| void reset() | 将此流的记录指针重新定位到上一次记录标记(mark)的位置(定位到对此输入流最后调用mark方法时的位置) |
| long skip(long n) | 记录指针向前移动n个字节/字符 (忽略输入流中的n个字节/字符,返回值是实际忽略的字节数, 跳过一些字节来读取) |
- InputStream和Reader的其他方法:
| 方法 | 说明 |
|---|---|
| void close() | 关闭此输入流并释放与该流相关联的所有系统资源,关闭后此对象则不能使用 |
int available() 字节流输入流方法 |
返回不受阻塞地从此输入流每次读取的字节数 ( 每次返回输入流中剩余可以读取的字节数。注意:若输入阻塞,当前线程将被挂起,如果InputStream对象调用这个方法的话,它只会返回0,这个方法必须由继承InputStream类的子类对象调用才有用) |
-
InputStream和Reader的理解

-
对于InputStream和Reader而言,它们把输入设备(
计算机系统之间进行信息交换的主要装置之一。键盘,鼠标,摄像头,扫描仪,光笔,手写输入板,游戏杆,语音输入)抽象成为一个”水管“,水管的每个“水滴”依次排列,字节流和字符流的处理方式相似,只是处理的输入/输出单位不同而已。 -
输入流使用
隐式的记录指针来表示当前正准备从哪个“水滴”开始读取,当程序从InputStream或者Reader里取出一个或者多个“水滴”后,记录指针自动向后移动;除此外,InputStream和Reader里面都提供了方法来控制记录指针的移动。 -
InputStream和Reader都是将输入数据抽象成如上图所示的
水管 -
可以通过·read()方法每次读取
一个”水滴“ -
可以通过
read(char[] b)或者read(byte[] b)方法来读取多个“水滴”。 -
当使用
字节/字符数组作为read()方法中的形参, 可以理解为使用一个“竹筒”到上图所示的水管中取水 -
read(char[] b)方法的形参可以理解成一个”竹筒“,程序每次调用输入流read(char[] b)或read(byte[] b)方法,就相当于用“竹筒”从输入流中取出一筒“水滴”,程序得到“竹筒”里面的”水滴“后,转换成相应的数据即可; -
程序多次重复这个“取水”过程,直到最后。程序如何判断取水取到了最后呢?如果
read(char[] b)或者read(byte[] b)方法返回-1,即表明到了输入流的结束点。 -
在调用InputStream的
read()方法读取数据时,我们说read()方法是阻塞(Blocking)的。它的意思是,对于下面的代码int n; n = input.read(); // 必须等待read()方法返回才能执行下一行代码 int m = n;执行到第二行代码时,必须等read()方法返回后才能继续往下执行。
因为读取IO流相比执行普通代码,速度会慢很多,因此,无法确定read()方法调用到底要花费多长时间。
OutputStream和Writer
OutputStream(字节输出流)和Writer(字符输出流),不是一个接口,而是所有输出流的抽象父类,本身并不能创建对象来执行输入,但它是所有输出流的模板,它的方法是所有输出流都可使用的方法。
- 在
OutputStream里面包含如下3个方法。
| 方法 | 说明 |
|---|---|
| void write(int c) | 将指定的字节输出到输出流中 |
| void write(byte[] b) | 将字节数组b中的数据输出到指定输出流中。 |
| void write(byte[] b, int off,int len ) | 将字节数组b中从off位置开始,长度为len的字节输出到输出流中。 |
- 在
Writer里面包含如下3个方法。
| 方法 | 说明 |
|---|---|
| void write(int c) | 将指定的字符输出到输出流中 |
| void write(char[] b) | 将字符数组b中的数据输出到指定输出流中。 |
| void write(char[] b, int off,int len ) | 将字符数组b中从off位置开始,长度为len的字符输出到输出流中。 |
因为字符流直接以字符作为操作单位,所以Writer可以用字符串来代替字符数组,即以String对象作为参数。
Writer里面还包含如下两个方法。
| 方法 | 说明 |
|---|---|
| void write(String str) | 将str字符串里包含的字符输出到指定输出流中。 |
| void write (String str, int off, int len) | 将str字符串里面从off位置开始,长度为len的字符输出到指定输出流中 |
- OutputStream和OutputStream的其他方法:
| 方法 | 说明 |
|---|---|
| flush() | 刷新该流的缓冲区,但并没有关闭该流,刷新之后还可以继续使用该流对象进行数据操作。 |
| close() | 关闭此输入流并释放与该流相关联的所有系统资源,,并在关闭之前先刷新该流,关闭之后流对象不可再被使用。 |
- 输入流的close()具备刷新功能
(会在关闭时调用flush),在关闭流之前,就会先刷新一次缓存区,将缓冲区的字节全都刷新到文件上,再关闭流- 一般情况下可以直接使用close()方法直接关闭该流,但是当数据量比较大的时候,可以使用flush()方法
- 为什么要有flush()方法?
-
因为向磁盘、网络写入数据的时候,出于效率的考虑,操作系统
并不是输出一个字节就立刻写入到文件或者发送到网络,而是把输出的字节先放到内存的一个缓冲区里(本质上就是一个byte[]数组),等到缓冲区写满了,再一次性写入文件或者网络。 -
对于很多IO设备来说,
一次写一个字节和一次写1000个字节,花费的时间几乎是完全一样的,所以OutputStream有个flush()方法,能强制把缓冲区内容输出。 -
通常情况下,我们不需要调用这个flush()方法,因为缓冲区写满了OutputStream会自动调用它,并且,在调用close()方法关闭OutputStream之前,也会自动调用flush()方法。
-
在某些情况下,我们必须
手动调用flush()方法。如:-
小明正在开发一款在线聊天软件,当用户输入一句话后,就通过OutputStream的write()方法写入网络流。小明测试的时候发现,发送方输入后,接收方根本收不到任何信息,怎么肥四?
-
原因就在于
写入网络流是先写入内存缓冲区,等缓冲区满了才会一次性发送到网络。如果缓冲区大小是4K,则发送方要敲几千个字符后,操作系统才会把缓冲区的内容发送出去,这个时候,接收方会一次性收到大量消息。 -
解决办法就是
每输入一句话后,立刻调用flush(),不管当前缓冲区是否已满,强迫操作系统把缓冲区的内容立刻发送出去
-
-
实际上,
InputStream也有缓冲区。如,从FileInputStream读取一个字节时,操作系统往往会一次性读取若干字节到缓冲区,并维护一个指针指向未读的缓冲区。然后,每次我们调用int read()读取下一个字节时,可以直接返回缓冲区的下一个字节,避免每次读一个字节都导致IO操作。当缓冲区全部读完后继续调用read(),则会触发操作系统的下一次读取并再次填满缓冲区。因此,和InputStream一样,OutputStream的write()方法也是阻塞的。
- OutputStream和Writer的理解
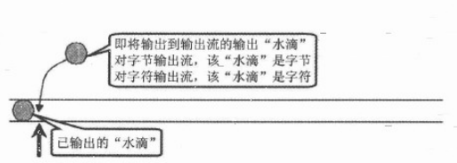
- 对于OutputStream和Writer而言,它们同样把输出设备
(用于接收计算机数据的输出显示,以数字、字符、图像、声音等形式表现, 如: 显示器、打印机、绘图仪、影像输出系统、语音输出系统、磁记录设备)抽象成一个”水管“,只是这个水管里面没有任何水滴,如上图所示: - 当执行输出时,程序相当于
依次把“水滴”放入到输出流的水管中 - 输出流同样用
隐示指针来标识当前水滴即将放入的位置,每当程序向OutputStream或者Writer里面输出一个或者多个水滴后,记录指针自动向后移动。
处理流优点
上面输入输出流两图显示了java Io的基本概念模型,除此之外,Java的处理流模型则体现了Java输入和输出流设计的灵活性。处理流的功能主要体现在以下两个方面。
- 性能的提高:主要以增加
缓冲的方式来提供输入和输出的效率。 - 操作的便捷:处理流可能提供了一系列便捷的方法来
一次输入和输出大批量的内容,而不是输入/输出一个或者多个“水滴”。 - 处理流可以·“嫁接”·在·任何已存在的流·的基础之上,这就允许Java应用程序采用相同的代码,透明的方式来访问不同的输入和输出设备的数据流。

常见IOException异常类
- public class EOFException :
非正常到达文件尾或输入流尾时,抛出这种类型的异常。 - public class FileNotFoundException:
当文件找不到时,抛出的异常。 - public class InterruptedIOException:
当I/O操作被中断时,抛出这种类型的异常
使用try(resource)来保证InputStream正确关闭
-
InputStream和OutputStream都是通过close()方法来关闭流。关闭流就会释放对应的底层资源。
-
程序在运行的过程中,打开了一个文件进行读写,完成后要及时地关闭,以便让操作系统把资源释放掉,否则,应用程序占用的资源会越来越多,不但白白占用内存,还会影响其他应用程序的运行。因此,我们需要用try … finally来保证输入输出流无论是否发生异常,都要关闭资源
-
与JDBC编程一样,程序里面打开的文件IO资源不属于内存的资源,
垃圾回收机制无法回收该资源,所以应该显式的关闭打开的IO资源。Java 1.7改写了所有的IO资源类,它们都实现了AutoCloseable接口,因此都可以通过自动关闭资源的try-catch-resource语句来关闭这些Io流。
/**
* @param srcPath 源文件路径
* @param destPath 拷贝文件路径
*/
public static void copyFile(String srcPath, String destPath, Integer length) {
File srcFile = new File(srcPath);// 源头
File destFile = new File(destPath);//目的地
if (srcFile.isDirectory() || destFile.isDirectory() || length == null) {// 参数校验
return;
}
// 1.7后所有实现AutoCloseable接口后的资源,都可以放在try(....)中,try-catch后自动关闭资源
try (
InputStream fis = new FileInputStream(srcFile);
OutputStream fos = new FileOutputStream(destFile);
) {
byte[] bytes = new byte[length];//缓冲容器
int rs = -1;//保存每次输入流读取的字节长度,与bytes长度有关
while ((rs = fis.read(bytes)) != -1) {
System.out.println("剩余大小==>"+fis.available()+"kb" +"==>"+(fis.available()/1024/1024)+"M");
fos.write(bytes);
}
fos.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
四.拓展
1.通过装饰器模式重写IO流
Java的IO标准库可以通过一个“基础”组件再叠加各种“附加”功能组件的模式,称之为Filter模式(或者装饰器模式:Decorator)。为InputStream和OutputStream增加功能:
- 可以把一个InputStream和任意个FilterInputStream组合;
- 可以把一个OutputStream和任意个FilterOutputStream组合。
编写一个CountInputStream,它的作用是对输入的字节进行计数:
public class Main {
public static void main(String[] args) throws IOException {
byte[] data = "hello, world!".getBytes("UTF-8");
try (CountInputStream input = new CountInputStream(new ByteArrayInputStream(data))) {
int n;
while ((n = input.read()) != -1) {
System.out.println((char)n);
}
System.out.println("Total read " + input.getBytesRead() + " bytes");
}
}
}
class CountInputStream extends FilterInputStream {
private int count = 0;
CountInputStream(InputStream in) {
super(in);
}
public int getBytesRead() {
return this.count;
}
public int read() throws IOException {
int n = in.read();
if (n != -1) {
this.count ++;
}
return n;
}
public int read(byte[] b, int off, int len) throws IOException {
int n = in.read(b, off, len);
this.count += n;
return n;
}
}
2.操作Zip
ZipInputStream是一种FilterInputStream,它可以·直接读取zip包的内容·:
另一个JarInputStream是从ZipInputStream派生,它增加的主要功能是直接读取jar文件里面的MANIFEST.MF文件。因为本质上jar包就是zip包,只是额外附加了一些固定的描述文件。
- 读取zip包
- 创建一个ZipInputStream,通常是传入一个FileInputStream作为数据源,然
- 循环调用getNextEntry(),直到返回null,表示zip流结束。
- 一个ZipEntry表示一个压缩文件或目录,如果是压缩文件,我们就用read()方法不断读取,直到返回-1:
@Test
public void testReadZipToFile() {
String srcPath = "test.zip";
readZipToFile(srcPath,"zip-",1024);
}
/**
* 读取压缩包文件 输出到指定位置
* @param srcPath 压缩包位置
* @param outPath 输出压缩包文件位置
* @param length 每次读取大小
*/
public static void readZipToFile(String srcPath, String outPath, int length) {
FileOutputStream fos = null;
try (
ZipInputStream zip = new ZipInputStream(new FileInputStream(srcPath));
) {
ZipEntry entry = null;
while ((entry = zip.getNextEntry()) != null) {
String name = entry.getName();//当前文件名字
fos = new FileOutputStream(outPath + name);
//非目录
if (!entry.isDirectory()) {
int len = -1;
byte[] bytes = new byte[length];
while ((len = zip.read(bytes)) != -1) {
fos.write(bytes,0,len);
}
fos.flush();
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
- . 写入zip包
- 我们要先创建一个ZipOutputStream,通常是包装一个FileOutputStream,
- 每写入一个文件前,先调用putNextEntry(),然后用write()写入byte[]数据
- 写入完毕后调用closeEntry()结束这个文件的打包。
@Test
public void testWriteFileToZip() {
String outPath = "test.zip";
File[] files = {new File("a.jpg"), new File("baidu.html"), new File("test444.txt")};
writeFileToZip(outPath, files);
}
/**
* 将多个文件推入压缩包中
* 1.我们要先创建一个ZipOutputStream,通常是包装一个FileOutputStream,
* 2.每写入一个文件前,先调用putNextEntry(),然后用write()写入byte[]数据
* 3.写入完毕后调用closeEntry()结束这个文件的打包。
* 4.上面的代码没有考虑文件的目录结构。如果要实现目录层次结构,new ZipEntry(name)传入的name要用相对路径
*
* @param outPath 输出文件路径
* @param files 要压缩的多个文件
*/
public static void writeFileToZip(String outPath, File[] files) {
try (
ZipOutputStream zip = new ZipOutputStream(new FileOutputStream(outPath));
) {
for (File file : files) {
zip.putNextEntry(new ZipEntry(file.getName()));
zip.write(getFileDataAsBytes(file, 1024));//根据文件名获取当前文件的所有字节数公共方法
zip.closeEntry();
}
System.out.println("执行成功");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 获取制定文件对象字节数组
*
* @param srcPath 源文件路径
* @return byte[]
*/
public static byte[] getFileDataAsBytes(File srcPath, int length) {
try (
InputStream fis = new FileInputStream(srcPath);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
) {
int len = -1;
byte[] bytes = new byte[length];
while ((len = fis.read(bytes)) != -1) {
bos.write(bytes, 0, len);
}
bos.flush();
return bos.toByteArray();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
上面的代码没有考虑文件的目录结构。如果要实现目录层次结构,new ZipEntry(name)传入的name要用相对路径
3.使用getResourceAsStream()读取classpath资源避免文件路径依赖
很多Java程序启动的时候,都需要读取配置文件。例如,从一个.properties文件中读取配置:
String conf = "C:\\conf\\default.properties";
try (InputStream input = new FileInputStream(conf)) {
// TODO:
}
这段代码要正常执行,必须在C盘创建conf目录,然后在目录里创建default.properties文件。但是,在Linux系统上,路径和Windows的又不一样。因此,从磁盘的固定目录读取配置文件,不是一个好的办法。
- 有没有路径无关的读取文件的方式呢?
我们知道,Java存放.class的目录或jar包也可以包含任意其他类型的文件,例如:
配置文件,例如.properties;
图片文件,例如.jpg;
文本文件,例如.txt,.csv;
……
从classpath读取文件就可以避免不同环境下文件路径不一致的问题:如果我们把default.properties文件放到classpath中,就不用关心它的实际存放路径。
- 在
classpath中的资源文件,路径总是以/开头,我们先获取当前的Class对象,然后调用getResourceAsStream()就可以直接从classpath读取任意的资源文件: - 调用
getResourceAsStream()需要特别注意的一点是如果资源文件不存在,它将返回null。因此,我们判断检查返回的InputStream是否为null,如果为null,表示资源文件在classpath中没有找到:
try (InputStream input = getClass().getResourceAsStream("/default.properties")) {
if (input != null) {
// TODO:
}
}
如果我们把默认的配置放到jar包中,再从外部文件系统读取一个可选的配置文件,就可以做到既有默认的配置文件,又可以让用户自己修改配置:
Properties props = new Properties();
props.load(new FileReader("/default.properties"));// classPath下的默认配置文件
props.load(new FileReader("./conf.properties"));//从外部文件系统读取一个可选的配置文件
这样读取配置文件,应用程序启动就更加灵活。
4.何为NIO,和传统Io有何区别?
- 传统输入输出流中读写数据时,如果没有读取/写入有效的数据,程序将在此处阻塞该线程的执行。因此,
传统的输入输出流都是阻塞式的进行输入输出。 - 不仅如此,
传统输入输出流都是通过字节的移动来处理的(即使我们不直接处理字节流,但底层实现还是依赖于字节处理),就是说面向流的输入和输出一次只能处理一个字节,因此面向流的输入和输出系统效率通常不高。 - 从JDk1.4开始,java提供了一系列改进的输入和输出处理的新功能,这些功能被统称为
新IO(NIO)。新增了许多用于处理输入和输出的类,这些类都被放在java.nio包及其子包下,并且对原io的很多类都以NIO为基础进行了改写。新增了满足NIO的功能。 - NIO采用了
内存映射对象的方式来处理输入和输出,NIO将文件或者文件的一块区域映射到内存中,这样就可以像访问内存一样来访问文件了。通过这种方式来进行输入/输出比传统的输入输出要快的多。
