原创不易,转载请标明地址,或者直接附上我的博客首页https://georgedage.blog.csdn.net/
文中有些并没有解释过于清楚,本篇更适合有基础的同学阅读,思考,思考,思考。
千亿级实时搜索,要满足的条件
》高并发,要能支持百万级以上的并发
》实时性,响应时间不超过3秒
那么我们考虑,这样的情况下,使用数据库是否可以?
Mysql / pgsql / db2 / Oracle
首先先说出我们的结论,那就是不可以,那么为什么呢?请听我细细给你叨唠,本篇博客通过由浅入深,并且根据一个个问题去探讨,或许你看完之后会有一点想法,不过如果有不妥之处,欢迎指出。
我们经常浏览博客,新闻,商品等,存储这些数据的表应当具有什么样的字段呢?

提出问题:
在数据库中如何做到下面的查询?以新闻表为例

或许对于稍微掌握点数据库知识的同僚们,这些都不是问题!
那么,请看问题二!
当数据量变大时,这四个查询都变慢了,该如何优化?
我们都知道,数据库的常用数据库优化方法为:
》建索引
》分区表
由此提出问题三。
建索引对“查询标题与钓鱼岛有关的新闻”和“查询与苍老师有 关的新闻”有效果吗?
或许对索引有点基本概念的同僚们,会想,没关系呀。
嗯,好,那我问你,为什么呢?
(⊙o⊙)…(⊙o⊙)…(⊙o⊙)…
所以我们需要理解索引的原理是什么?
索引的原理是什么
即: 对列值创建排序存储,数据结构={列值、行地址}。在有序数据列表中就可以利用二分查找快速找到要查找的行的地址,再根据地址直接取行数据。
或许这样看会有点抽象,这里我们可以补充一下自己的基础知识,当然也是面试中经常问到的。
数组,链表,树,二叉树,红黑树,mysql的b+tree

对于b+tree:
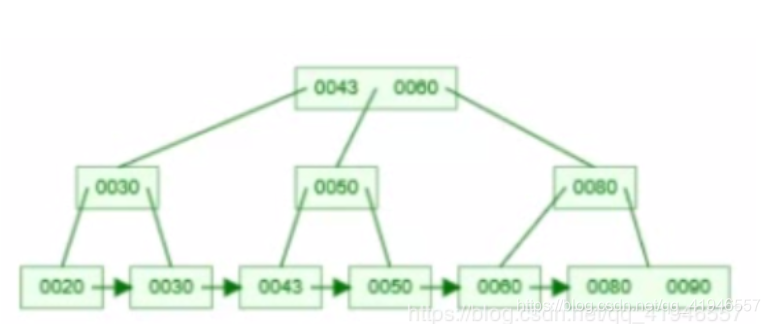
b+tree,叶子存储数据,节点关键值
这里补充一道面试题:大剑无锋之简单说一下聚簇索引和非聚簇索引?【面试推荐】
然后根据索引的原理进一步思考索引!
索引的排序,是怎么排的?
》数值列
》时间列
》文本列
这里相信学过语言基础的都知道,编码字符集的应用。
就像汉字,在计算机中的存储也是二进制,所以也就是我们常说的字典序。详细这里不做过多的阐述。
在新闻标题列上建索引,当我们查询标题=‘钓鱼岛’ ,数据库会怎么去查?
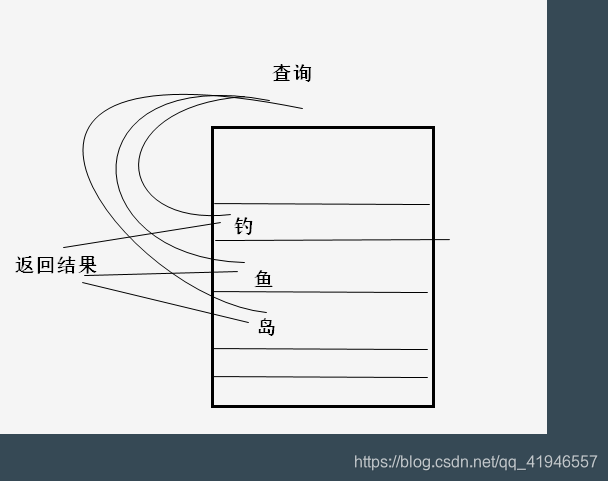
但是我们查询的是这样一个字段呢?
或者说数据库中有这样一个字段,“中国拥有钓鱼岛”
如果走索引,这个是会被忽视的查询不到,所以需要全局进行查询。
【补充】这里我在网上看到有说到覆盖索引可以解决类似问题,不过这个我并没有进行研究呢,后续补上!
如果要对查询出来的结果进行相关度排名,数据库能否做到?

如果要对搜索的新闻字段设置不同的权重,比如新闻标题中包含这三个关键字的新闻的
相关性就远高于新闻内容中包含这三个字。数据库能否做到?
最后我们得出结论
结论:
数据库适合结构化数据的精确查询,而不适合半结构化、非结构化数据的模糊查询及灵活搜索(特别是数据量大时),无法提供想要的实时性。
【补充】

