前言
你看到这篇是我最大的荣幸,这是本人根据往年试卷和考点自己出的一套复习卷子,也可以当做是押题卷吧,为了帮助一些已经在实习缺乏复习时间的同学成功应付考试。事实证明这套卷效果不错,预测对了一半以上试卷原题考点,认识的同学里在这份试卷的帮助下一天就复习完了,最后拿到了七十多分顺利过关。
因为单单复习考点可能会比较无聊,我认为在做题中可以更快把握考试要点,活跃大脑增强记忆。这份卷子旨在帮助大家复习,而不是说只做这卷子就能通过考试。
一、填空
- 在三层模型中,云计算常常被分为 基础设施作为服务(IaaS),平台作为服务(PaaS
),软件作为服务 (SaaS)。 - 云计算的虚拟化技术有哪些:服务器虚拟化、存储虚拟化、网络虚拟化
- 常用高维度数据可视化技术分类:散点图矩阵,平行坐标,降维投影,雷达图
- 大数据来源:对现实世界的测量,人类的记录和计算机生成的数据
- 数据质量的维度:精确性,一致性,完整性,时效性,实体同一性
- 数据缺失值填充方法:删除,统一填充,统计填充,预测填充
【以上在考试时都出现了,并且还出现了特征选择和特征提取的填空】
二、概念题
- 大数据概念并列举4V或5V特征
海量数据或巨量数据,其规模巨大到无法通过目前主流的计算机系统在合理时间内获取、存储、管理、处理并提炼以帮助使用者决策。
Volume:数据量大;
Variety:种类和来源多样化;
Value:数据价值密度相对较低;
Velocity:数据增长速度快;
(可选)Veracity:数据的准确性和可信赖度,即数据的质量。 - 云计算概念及特点
定义:云计算是一种商业计算模型。它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务。云计算是通过网络按需提供可动态伸缩的廉价计算服务。
特点:超大规模,虚拟化,高可靠性、通用性,高可伸缩性,极其廉价,按需服务
【考试时还考了Vector Space Model定义】
三、计算题

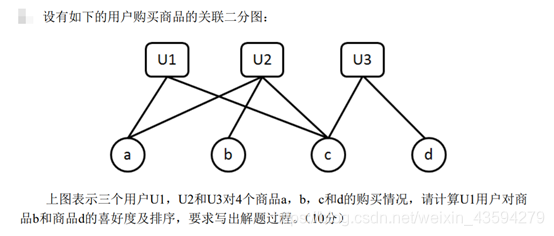
假设当且仅当u和i发生关联时r(u,i)=1,否则r(u,i)=0
使用UserBase和ItemBase其中一种求解即可。
3. 精确度、召回率和F1值的计算
【考试时还出了朴素贝叶斯计算的大题,压根没复习,真是被老师摆了一道】
四、 解答与分析题
-
HDFS简介及其特点
HDFS作为Hadoop的分布式文件系统,其功能为数据的存储、管理和出错处理。它是类似于GFS的开源版本,设计的目的是用于可靠地存储大规模的数据集,并提高用户访问数据的效率。
特点:适合大数据存储和处理;
集群规模可动态扩展;
能有效保证数据一致性
数据吞吐量大,跨平台移植性好。 -
NoSQL数据库可以分为哪四大类?分别简述其特点。
分为键值对,列族,文档和图数据库四类。
以Redis为代表的键值对数据库主要应用于处理大量数据的高访问负载,查找速度快但数据无结构化;
以HBase为代表的列族数据库以列簇式存储,将同一列数据存在一起,查找速度快,可扩展性强,但功能相对局限;
以MongoDB为代表的文档数据库应用于Web应用,其对数据结构要求不严格,表结构可变同时也导致查询性能不高,缺乏统一查询语法。
以Neo4j为代表的图数据库主要用于社交网络和推荐系统,专注于构建关系图谱,利用图结构模型和算法,不足之处就是需对整个图做计算,故不易使用分布式集群计算。 -
请列举典型的分布式文件系统,并简要描述。
HDFS,是Hadoop的分布式文件系统,其功能是数据的管理、存储和出错处理。HDFS适合大文件存储,集群可动态扩展,能有效保证数据一致性,数据吞吐量大,跨平台移植性好。
Ceph是一个高可用、易管理、开源的分布式存储系统,可以提供对象存储、块存储、文件存储服务,优势包括统一存储能力、可扩展性、可靠、自动化维护等。相对于离线批处理的HDFS,Ceph更倾向于成为一种高可扩展、高可用、高性能的实时分布式系统,对数据的写入尤其是随机写入支持更好。
ClusterFS是一个开源分布式系统,具有强大的横向扩展能力,通过扩展能够存储PB级数据及处理数千客户端。 -
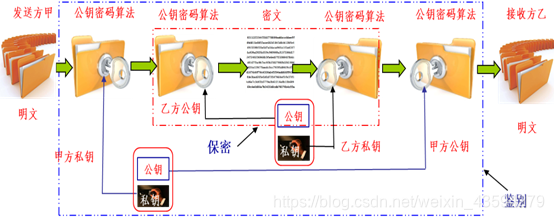
设计一个具有保密鉴别的公开密码模型
-
简述BSP模型的基本原理和BSP计算的主要步骤。
基本原理:
BSP模型是一种异步MIMD-DM模型,一种基于块同步的并行计算模型,块内异步并行,块间显式同步。
计算的主要步骤:
从垂直上看,由一系列串行的超步组成,类似串行程序结构
从水平上看,在每一个超步中,所有的进程并行进行局部计算
局部计算:每个处理器只对存储在本地内存的数据进行计算
全局通讯:处理器群相互交换数据,由一方发起推送和获取操作
栅栏同步:当一个处理器遇到栅栏,会等到其他处理器也都到达为止。 -
批量计算、流式计算、图计算等概念和含义
批量计算主要面向离线计算场景,计算的数据是静态数据,数据在计算之前已经获取并保存,在计算过程中不会发生变化,实时性要求不高,计算被允许计算一段时间而不必立即返回结果。批量大数据通常由计算请求输入接口,计算管控节点和若干计算执行节点共同组成。典型例子是Map Reduce
流式计算:主要面向在线计算场景,计算的数据是动态数据,数据在计算过程中不断的到来,计算前无法预知数据的到来时刻和到来顺序,也无法预先将数据进行存储。实时性要求高。因此流式计算就是对流式数据实时分析,从而获取有价值的实时信息
图计算:研究物件与物件之间的关系,并进行整体的刻画、计算和分析的一种技术。
- YARN设计思路(体系架构)
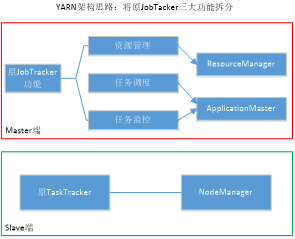
记住图,按着图说八九不离十
总结
知识点很多,要考高分确实有些困难,要对老师所讲过的东西都记一遍,这也是强调上课听课的重要性,有的人觉得大学上课很无聊,可是上课听课却是效率性价比最高的,我不敢保证你每次上完课都能听懂或者在期末还能记住知识点,但是到最后你复习一定比别人轻松,因为这些知识很早就存在于你的大脑,你可以很快回忆起要点,不会一上来就一堆很陌生的名称。
最后恭祝你能考出好成绩,加油!