随着现在越来越多的学python的在爬取一些网站的数据,有一些知名的网站有着反爬虫,所以有的时候爬虫比较困难
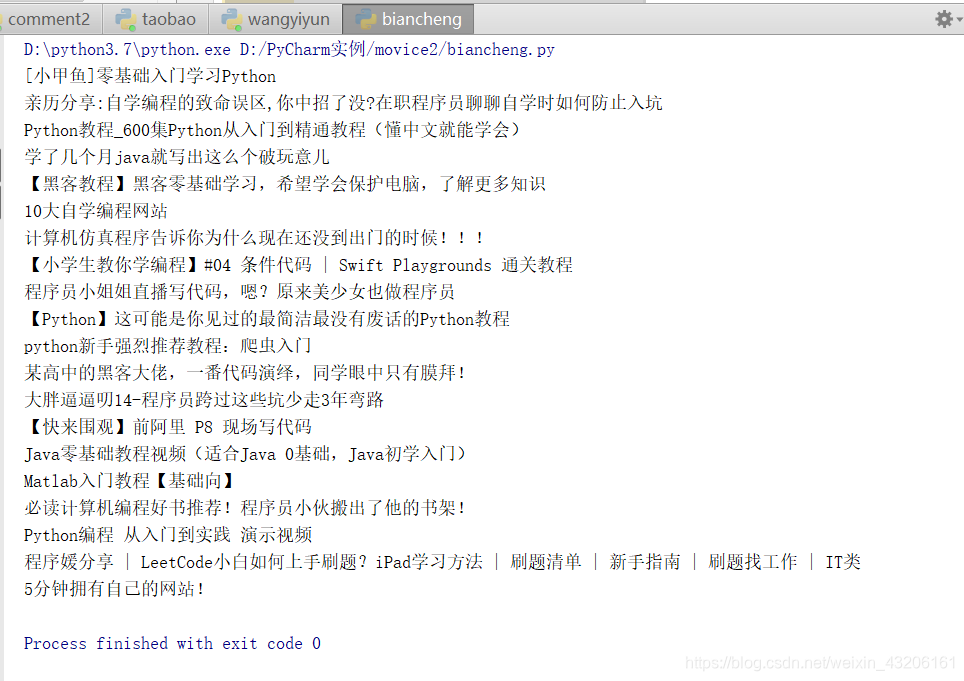
import requests
import bs4
res = requests.get(“https://search.bilibili.com/all?keyword=%E7%BC%96%E7%A8%8B&from_source=nav_search_new&order=totalrank&duration=0&tids_1=0”)
res.text
soup = bs4.BeautifulSoup(res.text,“html.parser”)
titles = soup.find_all(“li”,class_=“video-item matrix”)
for each in titles:
print(each.a[‘title’])
https://blog.csdn.net/weixin_43206161
爬取一些数据

猜你喜欢
转载自blog.csdn.net/weixin_43206161/article/details/104201359
今日推荐
周排行