提到mysql的索引,想必很多人都能说上几句:提高查询效率、优化sql的方式。但是索引的底层实现到底是什么?索引是如何存储的?我们将逐一进行说明。本文涉及到内容包括 什么是索引、mysql中操作索引的语法、索引的物理结构、索引的优缺点、索引的数据结构等。
什么是索引
MySQL官方对索引的定义为:索引(Index)是帮助mysql高效的获取数据的数据结构。可简单理解为排好序的快速查找数据结构。 也就是说数据库除了维护数据本身之外,还维护着一个满足特定查找算法的数据结构。这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引。
操作索引语法
创建
ALTER TABLE 表名 ADD [UNIQUE] INDEX 索引名(字段名);
或
CREATE INDEX 索引名 ON 表名(字段名);
删除
DROP INDEX 索引名 ON 表名
查看
show INDEX FROM 表名
索引的物理结构
1.数据库文件存储的位置:window系统在my.ini配置文件中;Linux系统在/etc/my.cnf文件中 的 dataDir参数对应的数据目录中。
2.每一个数据库对应一个文件夹
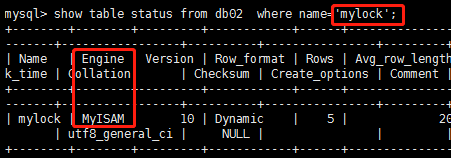
(1)MYISAM引擎:每一个表(table_name)
table_name.MYI:存放的是数据表对应的索引信息和索引内容
table_name.FRM:存放的是数据表的结构信息
table_name.MYD:存放的是数据表的内容
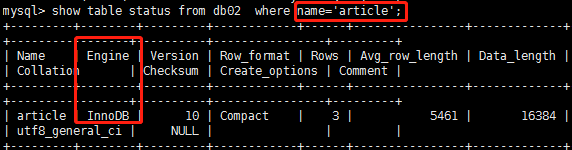
(2)InnoDB引擎:每一个表(table_name)
table_name.frm:存放的是数据表的结构信息
数据文件和索引文件都是统一存放在ibdata文件中
3.索引文件都是额外存在的,对索引的查询和维护都是需要消耗IO的
InnoDB引擎表:

MYISAM引擎
索引的优缺点
优势
类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本;
通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。

劣势
索引本身也是表,因此会占用存储空间,一般来说,索引表占用的空间的数据表的1.5倍;
索引表的维护和创建需要时间成本,这个成本随着数据量增大而增大。构建索引会降低数据表的修改操作(删除,添加,修改)的效率,因为在修改数据表的同时还需要修改索引表。
索引的数据结构
我们知道Mysql索引的底层数据结构使用的是B+Tree的结构。那么为什么使用B+Tree,而不使用我们熟悉的二叉树或红黑树呢,我们来了解一下。
二叉树简介:
二叉查找树也称为有序二叉查找树,满足二叉查找树的一般性质,是指一棵空树具有如下性质:
1、任意节点左子树不为空,则左子树的值均小于根节点的值;
2、任意节点右子树不为空,则右子树的值均大于于根节点的值;
3、任意节点的左右子树也分别是二叉查找树;
4、没有键值相等的节点;
假设索引数据是1到6的有序数字,那么如果利用二叉树作为索引数据结构,会形成怎样的结构呢?
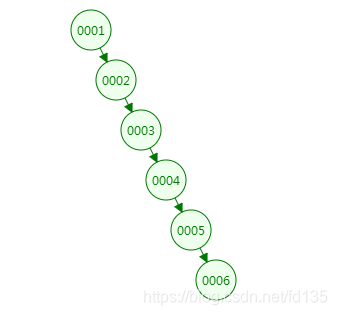
那么二叉查找树完全退化成了线性结构。显然这个二叉树的查询效率就很低,因此若想最大性能的构造一个二叉查找树,需要这个二叉树是平衡的,从而引出了一个新的定义-平衡二叉树AVL。
AVL树简介
AVL树是带有平衡条件的二叉查找树,一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡,左右子树树高不超过1,和红黑树相比,它是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过1)。不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转是非常耗时的,由此我们可以知道AVL树适合用于插入删除次数比较少,但查找多的情况。那么同样的数据在AVL树会形成怎样的结构呢?
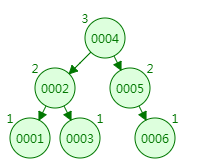
AVL树和普通二叉树相比,若想检索6这个索引,检索效率大大提高了,但是由于AVL是一个强平衡的二叉树,需要不断的旋转来维持。很显然在应用到索引的数据结构上还是效率很低的。那么我们可能会想到红黑树,一种弱平衡的二叉树,来减少旋转。
红黑树简介
一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是red或black。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍。它是一种弱平衡二叉树(由于是若平衡,可以推出,相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,它的旋转次数变少,所以对于搜索、插入、删除操作多的情况下,我们就用红黑树。
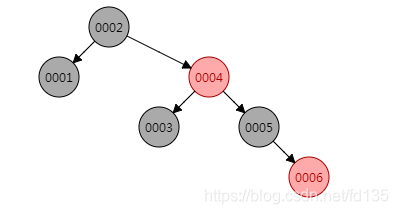
由上图可以看到,虽然红黑树较AVL树降低了旋转的频率,较二叉树来说降低了树的深度,提高了查询的效率。但是我们设想若这种有序的数据是大数据量的,红黑树的效率提升也还是没有那么明显。所以mysql最后选择的是一种接近于B-Tree的数据结构B+Tree,那么为什么没有选择B-Tree呢?
B-Tree简介
B/B+树是为了磁盘或其它存储设备而设计的一种平衡多路查找树(相对于二叉,B树每个内节点有多个分支),与红黑树相比,在相同的的节点的情况下,一颗B/B+树的高度远远小于红黑树的高度。B/B+树上操作的时间通常由存取磁盘的时间和CPU计算时间这两部分构成,而CPU的速度非常快,所以B树的操作效率取决于访问磁盘的次数,关键字总数相同的情况下B树的高度越小,磁盘I/O所花的时间越少。
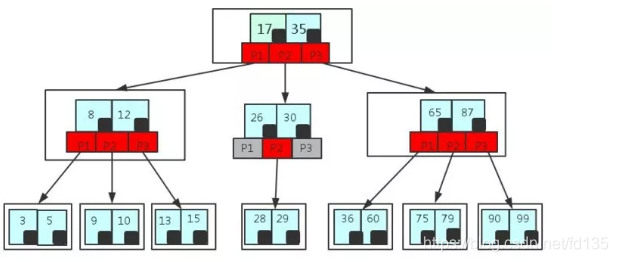
这里只是一个简单的B-Tree树,在实际中B树节点中关键字很多的,上面的图中比如35节点,35代表一个key(索引),而小黑块代表的是这个key所指向的内容在内存中实际的存储位置,是一个指针。叶子节点的指针是空的。节点中数据索引从左到右递增排序。
我们可以发现B树较红黑树相比,就是在同一层增加了索引的个数从而降低树的深度,来增加的检索效率。但是我们发现B-Tree每个节点都会有存储索引和数据的data,因为mysql默认每个节点的大小为16k,那么这就会限制每层节点的索引个数。正是由于这个原因,Mysql最终使用的是B+Tree的数据结构。
B+Tree简介
B+树是应文件系统所需而产生的一种B树的变形树(文件的目录一级一级索引,非叶子节点不存储data,只存储索引,目的可以存放更多的索引,叶子节点包含所有的索引字段,叶子节点用指针链接,提高区间访问的性能。
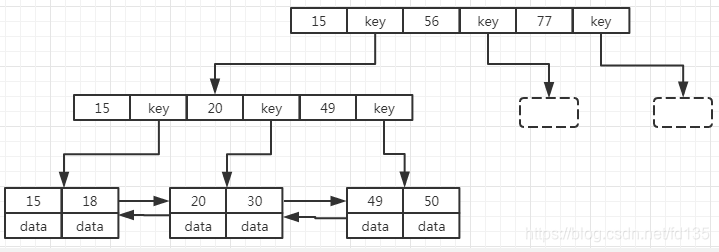
不同存储引擎下B+Tree的存储方式
在innodb中,存在两种索引类型,第一种是主键索引:在索引内容中,直接保存其他数据行信息;第二种是其他索引(辅助索引):在索引内容中保存的是指向主键索引的引用,所以在使用innodb的时候,尽量使用主键索引,速度非常快。
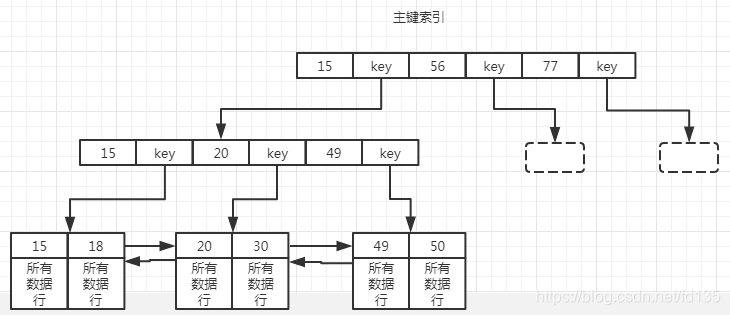
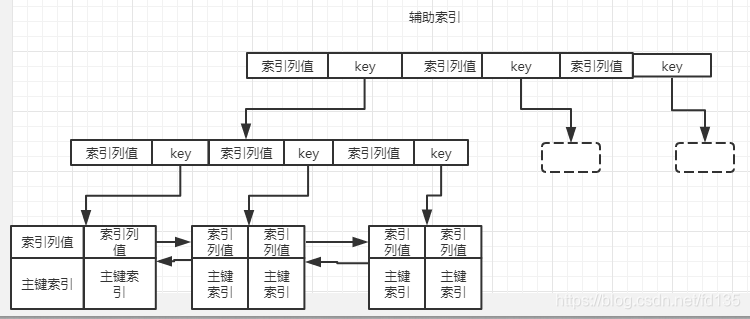
在MyIsam中主键索引和辅助索引的存储方式是一样的。
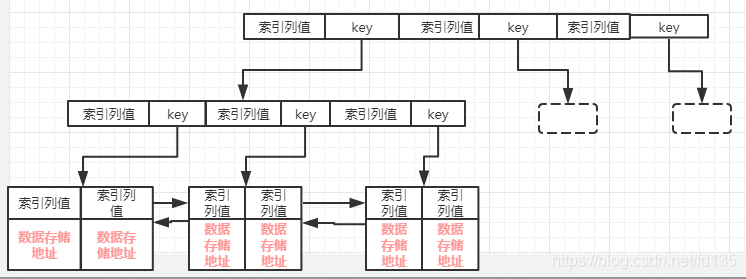
聚集索引和非聚集索引
下图可以形象的说明聚簇索引和非聚簇索引的区别
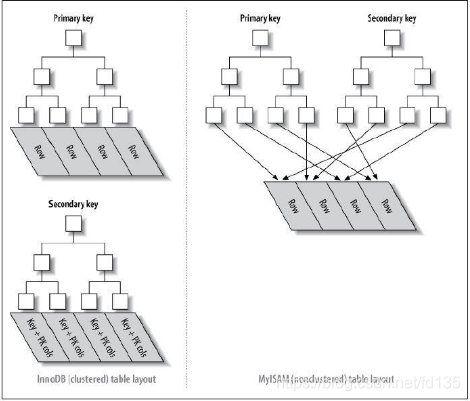
从上图中可以看到聚簇索引的辅助索引的叶子节点的data存储的是主键的值,主索引的叶子节点的data存储的是数据本身,也就是说数据和索引存储在一起,并且索引查询到的地方就是数据(data)本身,那么索引的顺序和数据本身的顺序就是相同的;
而非聚簇索引的主索引和辅助索引的叶子节点的data都是存储的数据的物理地址,也就是说索引和数据并不是存储在一起的,数据的顺序和索引的顺序并没有任何关系,也就是索引顺序与数据物理排列顺序无关。
参考链接:
https://mp.weixin.qq.com/s/_qYwHCrKLuTPksif5rRsPQ
https://blog.csdn.net/tongdanping/article/details/79878302
