索引是什么:是一个排序的列表,存储索引字段的值和这个数据对应的物理地址,使用索引字段查询时,不用扫描全表匹配,直接通过索引表找到改行数据对应的物理地址,然后找到对应的数据;
优点:因索引采用B+数的实现,减少I/O操作次数,增加查询效率
缺点:需要额外的硬盘空间,增、删、改有额外操作
分类:
- 主键索引,即主键
- 唯一索引,字段设置唯一约束时就已经存在,或者 alter table table_name add unique index_name("column");
- 一般索引,表中普通的字段作为索引: alter table table_name add index index_name("column"); 组合索引:
- 多个字段组合作为索引: alter table table_name add index index_name("columnA","columnB","columnC");
- 或者多个字段的前几个字符作为索引: alter table table_name add index index_name("columnA(3)","columnB(4)","columnC(5)"); //三个字段的前3,4,5个字符作为索引
- 遵循“最左前缀”,按照检索字段使用的频率排序,频率高的放左面;直接使用columnB,columnC起不到索引的作用
- 全文索引:
- 创建:alter table table_name add fulltext index index_name("column");
- 查询:select * from table match(index_name) against("xxx");
数据结构:
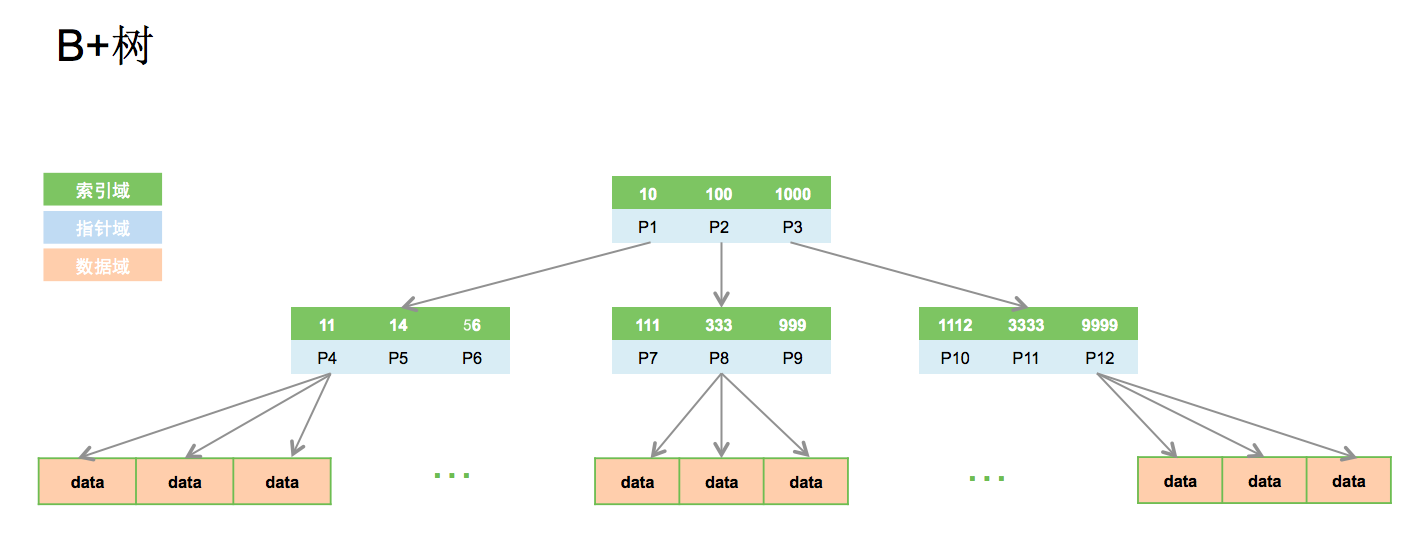
SELECT * FROM tab WHERE index_column="中国"; index_column的数据就是存在绿色索引域中的,数字,字符串都可以,data就是对应的那行数据。
索引域:图中的Px
为什么采用B+树(个人理解)
- 相对于二叉树:二叉树每个节点最多有两个子节点,B类树单个节点可容纳很多关键字,同时有很多子节点,降低了树高,判断/IO读取次数大大减少(不好理解,索引数据本身也在硬盘上)
- 相对于B-数:B+数的非子节点只存索引,不存数据,仅仅读取索引而不是直接的数据,消耗IO较少;B+树非子节点的关键字数和子节点指针数相等,相同数据量的情况下,B+数的书高更矮,减少IO
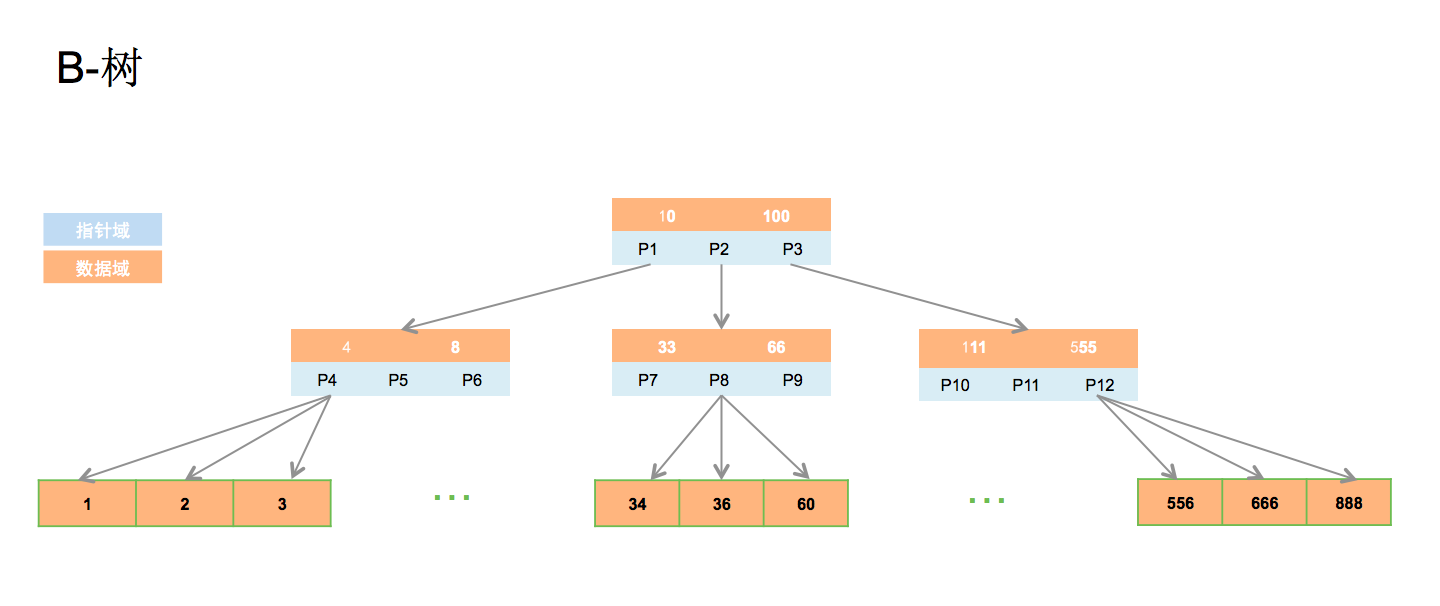
B-树: