这个是要求,说实话GUI做起来太难受了,要是随便做下还可以,但是要是非常细节,那就是折磨人的,这个实现了Apriori算法和FP-Growth算法,说实话,我确实不会,都是百度的,再修改嘛。

from tkinter import *
import fp_growth_py3 as fpg
import tkinter.filedialog
# 获取关联规则的封装函数
from numpy import *
import pandas as pd
def run1():
#参考网站https://blog.csdn.net/qq_36523839/article/details/82191677
# 构造数据
def loadDataSet():
return [
['啤酒', '牛奶', '可乐'],
['尿不湿', '啤酒', '牛奶', '橙汁'],
['啤酒', '尿不湿'],
['啤酒', '可乐', '尿不湿'],
['啤酒', '牛奶', '可乐']
]
# a=[]
# raw = pd.read_excel('1.xlsx')
# # print(list(raw['购买商品']))
# return [raw['购买商品']]
# # a.append([int(b) for b in i.split(',')])
# # return a
# 将所有元素转换为frozenset型字典,存放到列表中
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
# 使用frozenset是为了后面可以将这些值作为字典的键
return list(map(frozenset, C1)) # frozenset一种不可变的集合,set可变集合
# 过滤掉不符合支持度的集合
# 返回 频繁项集列表retList 所有元素的支持度字典
def scanD(D, Ck, minSupport):
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid): # 判断can是否是tid的《子集》 (这里使用子集的方式来判断两者的关系)
if can not in ssCnt: # 统计该值在整个记录中满足子集的次数(以字典的形式记录,frozenset为键)
ssCnt[can] = 1
else:
ssCnt[can] += 1
numItems = float(len(D))
retList = [] # 重新记录满足条件的数据值(即支持度大于阈值的数据)
supportData = {} # 每个数据值的支持度
for key in ssCnt:
support = ssCnt[key] / numItems
if support >= minSupport:
retList.insert(0, key)
supportData[key] = support
return retList, supportData # 排除不符合支持度元素后的元素 每个元素支持度
# 生成所有可以组合的集合
# 频繁项集列表Lk 项集元素个数k [frozenset({2, 3}), frozenset({3, 5})] -> [frozenset({2, 3, 5})]
def aprioriGen(Lk, k):
retList = []
lenLk = len(Lk)
for i in range(lenLk): # 两层循环比较Lk中的每个元素与其它元素
for j in range(i+1, lenLk):
L1 = list(Lk[i])[:k-2] # 将集合转为list后取值
L2 = list(Lk[j])[:k-2]
L1.sort(); L2.sort() # 这里说明一下:该函数每次比较两个list的前k-2个元素,如果相同则求并集得到k个元素的集合
if L1==L2:
retList.append(Lk[i] | Lk[j]) # 求并集
return retList # 返回频繁项集列表Ck
# 封装所有步骤的函数
# 返回 所有满足大于阈值的组合 集合支持度列表
def apriori(dataSet, minSupport = 0.5):
D = list(map(set, dataSet)) # 转换列表记录为字典 [{1, 3, 4}, {2, 3, 5}, {1, 2, 3, 5}, {2, 5}]
C1 = createC1(dataSet) # 将每个元素转会为frozenset字典 [frozenset({1}), frozenset({2}), frozenset({3}), frozenset({4}), frozenset({5})]
L1, supportData = scanD(D, C1, minSupport) # 过滤数据
L = [L1]
k = 2
while (len(L[k-2]) > 0): # 若仍有满足支持度的集合则继续做关联分析
Ck = aprioriGen(L[k-2], k) # Ck候选频繁项集
Lk, supK = scanD(D, Ck, minSupport) # Lk频繁项集
supportData.update(supK) # 更新字典(把新出现的集合:支持度加入到supportData中)
L.append(Lk)
k += 1 # 每次新组合的元素都只增加了一个,所以k也+1(k表示元素个数)
return L, supportData
# dataSet = loadDataSet(a)
# L,suppData = apriori(dataSet)
# print(L)
# print(suppData)
def generateRules(L, supportData, minConf=0.7): # supportData 是一个字典
bigRuleList = []
for i in range(1, len(L)): # 从为2个元素的集合开始
for freqSet in L[i]:
# 只包含单个元素的集合列表
H1 = [frozenset([item]) for item in freqSet] # frozenset({2, 3}) 转换为 [frozenset({2}), frozenset({3})]
# 如果集合元素大于2个,则需要处理才能获得规则
if (i > 1):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf) # 集合元素 集合拆分后的列表 。。。
else:
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
# 对规则进行评估 获得满足最小可信度的关联规则
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
prunedH = [] # 创建一个新的列表去返回
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq] # 计算置信度
if conf >= minConf:
print(freqSet-conseq,'-->',conseq,'conf:',conf)
brl.append((freqSet-conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
# 生成候选规则集合
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > (m + 1)): # 尝试进一步合并
Hmp1 = aprioriGen(H, m+1) # 将单个集合元素两两合并
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1): #need at least two sets to merge
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
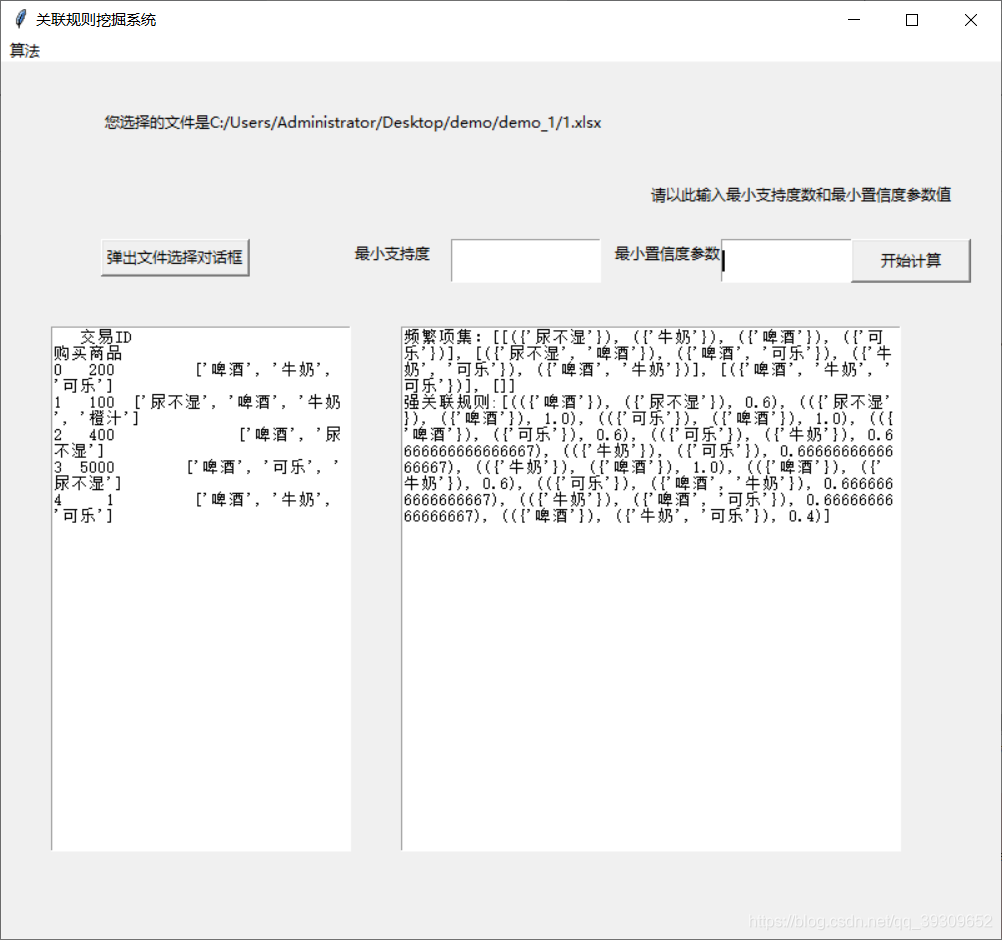
a = float(inp1.get())
b = float(inp2.get())
dataSet = loadDataSet()
print(dataSet)
L,suppData = apriori(dataSet,minSupport=a)
rules = generateRules(L,suppData,minConf=b)
print(rules)
L=str(L).replace('frozenset','')
rules=str(rules).replace('frozenset','')
result='频繁项集:'+str(L)+ '\n'+'强关联规则:'+str(rules)
# print(result)
txt.insert(END,result) # 追加显示运算结果
inp1.delete(0, END) # 清空输入
inp2.delete(0, END) # 清空输入
a=[]
def xz():
filename=tkinter.filedialog.askopenfilename()
if filename != '':
lb4.config(text='您选择的文件是'+filename)
raw = pd.read_excel(filename)
txt2.insert(END,raw)
print(list(raw['购买商品']))
for i in raw['购买商品']:
a.append([int(b) for b in i.split(',')])
else:
lb4.config(text='您没有选择任何文件')
# def run2(x, y):
# a = float(x)
# b = float(y)
# s = '%0.2f+%0.2f=%0.2f\n' % (a, b, a + b)
# txt.insert(END, s) # 追加显示运算结果
# inp1.delete(0, END) # 清空输入
# inp2.delete(0, END) # 清空输入
def cut():
pass
def cop():
def xz2():
filename=tkinter.filedialog.askopenfilename()
if filename != '':
lb42.config(text='您选择的文件是'+filename)
raw = pd.read_excel(filename)
txt22.insert(END,raw)
else:
lb42.config(text='您没有选择任何文件')
def run2():
a = float(inp12.get())
dataset = [
['啤酒', '牛奶', '可乐'],
['尿不湿', '啤酒', '牛奶', '橙汁'],
['啤酒', '尿不湿'],
['啤酒', '可乐', '尿不湿'],
['啤酒', '牛奶', '可乐']]
frequent_itemsets = fpg.find_frequent_itemsets(dataset, minimum_support=a, include_support=True)
print(type(frequent_itemsets)) # print type
result = []
for itemset, support in frequent_itemsets: # 将generator结果存入list
result.append((itemset, support))
result = sorted(result, key=lambda i: i[0]) # 排序后输出
for itemset, support in result:
print(str(itemset) + ' ' + str(support))
txt2.insert(END,str(itemset) + ' ' + str(support))
root2 = Tk()
root2.geometry('800x700')
root2.title('关联规则挖掘系统')
lb12 = Label(root2, text='请以此输入最小支持度数')
lb12.place(relx=0.4, rely=0.1, relwidth=0.8, relheight=0.1)
lb22 = Label(root2, text='最小支持度')
lb22.place(relx=0.35, rely=0.2)
inp12 = Entry(root2)
inp12.place(relx=0.45, rely=0.2,relwidth=0.15, relheight=0.05)
lb42 = Label(root2,text='')
lb42.place(relx=0.1, rely=0.05)
btn22=Button(root2,text='弹出文件选择对话框',command=xz2)
btn22.place(relx=0.1, rely=0.2)
# 方法-直接调用 run1()
btn12 = Button(root2, text='开始计算', command=run2)
btn12.place(relx=0.85, rely=0.2, relwidth=0.12, relheight=0.05)
# # 方法二利用 lambda 传参数调用run2()
# btn2 = Button(root, text='方法二', command=lambda: run2(inp1.get(), inp2.get()))
# btn2.place(relx=0.6, rely=0.4, relwidth=0.3, relheight=0.1)
# 在窗体垂直自上而下位置60%处起,布局相对窗体高度40%高的文本框
txt2 = Text(root2)
txt2.place(relx=0.4,rely=0.3, relheight=0.6,relwidth=0.5)
txt22 =Text(root2)
txt22.place(relx=0.05,rely=0.3, relheight=0.6,relwidth=0.3)
# mainmenu = Menu(root2)
# menuEdit = Menu(mainmenu) # 菜单分组 menuEdit
# mainmenu.add_cascade(label="算法",menu=menuEdit)
# menuEdit.add_command(label="Apriori",command=cut)
# menuEdit.add_command(label="FP-Growth",command=cop)
root2.config(menu=mainmenu)
root2.bind('Button-3',popupmenu) # 根窗体绑定鼠标右击响应事件
root.mainloop()
root = Tk()
root.geometry('800x700')
root.title('关联规则挖掘系统')
lb1 = Label(root, text='请以此输入最小支持度数和最小置信度参数值')
lb1.place(relx=0.4, rely=0.1, relwidth=0.8, relheight=0.1)
lb2 = Label(root, text='最小支持度')
lb2.place(relx=0.35, rely=0.2)
lb3 = Label(root, text='最小置信度参数')
lb3.place(relx=0.61, rely=0.2)
inp1 = Entry(root)
inp1.place(relx=0.45, rely=0.2,relwidth=0.15, relheight=0.05)
inp2 = Entry(root)
inp2.place(relx=0.72, rely=0.2,relwidth=0.15, relheight=0.05)
lb4 = Label(root,text='')
lb4.place(relx=0.1, rely=0.05)
btn2=Button(root,text='弹出文件选择对话框',command=xz)
btn2.place(relx=0.1, rely=0.2)
# 方法-直接调用 run1()
btn1 = Button(root, text='开始计算', command=run1)
btn1.place(relx=0.85, rely=0.2, relwidth=0.12, relheight=0.05)
# # 方法二利用 lambda 传参数调用run2()
# btn2 = Button(root, text='方法二', command=lambda: run2(inp1.get(), inp2.get()))
# btn2.place(relx=0.6, rely=0.4, relwidth=0.3, relheight=0.1)
# 在窗体垂直自上而下位置60%处起,布局相对窗体高度40%高的文本框
txt = Text(root)
txt.place(relx=0.4,rely=0.3, relheight=0.6,relwidth=0.5)
txt2 = Text(root)
txt2.place(relx=0.05,rely=0.3, relheight=0.6,relwidth=0.3)
mainmenu = Menu(root)
menuEdit = Menu(mainmenu) # 菜单分组 menuEdit
mainmenu.add_cascade(label="算法",menu=menuEdit)
# menuEdit.add_command(label="Apriori",command=cut)
menuEdit.add_command(label="FP-Growth",command=cop)
root.config(menu=mainmenu)
# root.bind('Button-3',popupmenu) # 根窗体绑定鼠标右击响应事件
root.mainloop()
print(a)
# [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
Exception in Tkinter callback
Traceback (most recent call last):
File "D:\sofewore\anaconda\lib\tkinter\__init__.py", line 1702, in __call__
return self.func(*args)
File "<ipython-input-3-1c37387ddf40>", line 308, in cop
root2.bind('Button-3',popupmenu) # 根窗体绑定鼠标右击响应事件
NameError: name 'popupmenu' is not defined
<class 'generator'>
['可乐'] 3
['可乐', '尿不湿'] 1
['啤酒'] 5
['啤酒', '可乐'] 3
['啤酒', '可乐', '尿不湿'] 1
['啤酒', '尿不湿'] 3
['啤酒', '尿不湿', '橙汁'] 1
['啤酒', '尿不湿', '牛奶'] 1
['啤酒', '尿不湿', '牛奶', '橙汁'] 1
['啤酒', '橙汁'] 1
['啤酒', '牛奶'] 3
['啤酒', '牛奶', '可乐'] 2
['啤酒', '牛奶', '橙汁'] 1
['尿不湿'] 3
['尿不湿', '橙汁'] 1
['尿不湿', '牛奶'] 1
['尿不湿', '牛奶', '橙汁'] 1
['橙汁'] 1
['牛奶'] 3
['牛奶', '可乐'] 2
['牛奶', '橙汁'] 1
[]