引用地址:http://blog.csdn.net/chuhang_zhqr/article/details/51060745
GMM是网上到处可见且用得最多的背景建模算法,论文上很多相关概率公式,又看了很多博客对于GMM的解释,直到现在还总是觉得很难理解其中的真谛,从各方面整理一下目前自己所理解的内容,如果有理解偏差,欢迎指正。
Mog2用的是自适应的高斯混合模型(Adaptive GMM,Gaussian Mixture Model),在OpenCV中开源了的几种背景提取算法MOG,MOG2,GMG的测试程序结果中,MOG2确实在前景连续性及运算时间上都脱颖而出,后面会给出比较结果。下面就结合OpenCV2.4.9的mog2源码和源码文档中指出的04年Zoran Zivkovic的三篇论文,简要串一串GMM的理论基础,MOG2的大致原理,在代码实现上的结构及MOG2 API的用法。
背景建模的思想由来
在监控系统中,拍摄背景通常是变化较少的固定场景。通常我们假定没有入侵物体的静态场景具有一些常规特性,可以用一个统计模型描述。GMM就是用高斯模型,而且是多个高斯模型的加权和混合在一起来模拟背景的特性。这样一旦已知这个背景模型,入侵物体就能通过标出场景图像中不符合这一背景模型的部分来检测到。这一过程被称为背景减除(Backgroundsubtraction),我猜OpenCV中各种背景建模方法的基类称作“BackgroundSubtractor”也源于此吧。
GMM模型参数估计的通常思路——GMM参数的EM估计
一旦背景以高斯混合模型来模拟了,现在确定这个模型变成了解出高斯混合模型公式中的一系列参数,在解参数时通常用的是EM演算法,EM演算法分两步:E-step和M-step。
关于EM算法的推导过程,链接的这个博客阐述的非常详细。
最大似然估计, EM算法理解上很有难度,涉及到最大似然估计上面链接也可以作为参考。
Mog2建模过程及各可调参数意义
上面说到GMM是用多个高斯模型的加权和来表示,假定是M个高斯分量,讨论M的取值是MOG2的作者研究的一个重点:在他之前Stauffer & Grimson取固定个数的高斯分量(M=4), Zoran则根据不同输入场景自动选择分量的个数。这样做的好处是在较简单的场景下,将只选出一个较重要的高斯分量,节省了后期更新背景时选属于哪一分量的时间,提高了速度。有两个测试结果为证:一是用OpenCV中测试程序对同一简单场景测试视频跑不同算法得到的运行时间如下表,明显mog2快很多;
| mog | mog2 | gmg | |
| 电脑1 | 26904 | 14386 | 25533 |
| 电脑2 | 26947 | 14578 | 28834 |
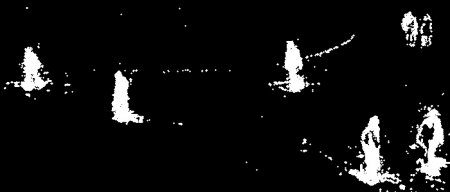
二是Zoran在讲背景更新的论文[i]的三个测试视频结果(图1, 摘自[1]中Fig.1第1,2列), 图中Traffic场景作为一个较简单的场景,背景变化不大,第二行中纯黑背景表示背景只用一个高斯分量,速度13ms较固定四个分量的19ms快了很多,而测试的Trees场景背景中包含树影晃动,背景浅灰色部分表示有多个高斯分量在更新,在这种场景自适应方法并没有优势。

对于整个图像的每个像素点都建立了一个GMM模型,建模过程中运用EM算法来求解参数组,一旦模型建立,后面每新来一帧都可以根据是否符合已建立的北京模型判断FG/BG,并会按论文中的参数更新公式更新GMM的所有参数。
OpenCV代码实现结构梳理
OpenCV中,各背景建模方法类继承关系如下图,BackgroundSubtractor是基类。
也给出一个博客,OpenCV中MOG2的代码结构梳理。
在mog2的使用中,初始化后,operator()函数是执行背景更新的主要函数,operator()内部实现主要是OpenCV的一个并行框架parallel_for_(),再深入实际是MOG2Invoker类的operator()实现了背景更新的具体数学运算。具体实现可以查看MOG2Invoker API文档。
Mog2.operator()
Parallel_for_()
Invoker.operator()
MOG2 API用法(how to use)
Mog,mog2,gmg的整体框架都一样,用法也很简单,可以根据openCV官方的tutorial来看。
[i] Efficient adaptivedensity estimation per image pixel for the task of background subtraction.
原文:
http://blog.csdn.net/chuhang_zhqr/article/details/51060745
在很多基础应用中背景检出都是一个非常重要的步骤。例如顾客统计,使用一个静态摄像头来记录进入和离开房间的人数,或者是交通摄像头,需要提取交通工具的信息等。在所有的这些例子中,首先要将人或车单独提取出来。
技术上来说,我们需要从静止的背景中提取移动的前景。如果你有一张背景(仅有背景不含前景)图像,比如没有顾客的房间,没有交通工具的道路等,那就好办了。我们只需要在新的图像中减去背景就可以得到前景对象了。但是在大多数情况下,我们没有这样的(背景)图像,所以我们需要从我们有的图像中提取背景。如果图像中的交通工具还有影子的话,那这个工作就更难了,因为影子也在移动,仅仅使用减法会把影子也当成前景。真是一件很复杂的事情。
1:BackgroundSubtractorMOG
这是一个以混合高斯模型为基础的前景/背景分割算法。它是 P.KadewTraKuPong和 R.Bowden 在 2001 年提出的。它使用 K(K=3 或 5)个高斯分布混合对背景像素进行建模。使用这些颜色(在整个视频中)存在时间的长短作为混合的权重。背景的颜色一般持续的时间最长,而且更加静止。一个像素怎么会有分布呢?在 x,y 平面上一个像素就是一个像素没有分布,但是我们现在讲的背景建模是基于时间序列的,因此每一个像素点所在的位置在整个时间序列中就会有很多值,从而构成一个分布。
在编写代码时,我们需要使用函数: cv2.createBackgroundSubtractorMOG()创建一个背景对象。这个函数有些可选参数,比如要进行建模场景的时间长度,高斯混合成分的数量,阈值等。将他们全部设置为默认值。然后在整个视频中我们是需要使用 backgroundsubtractor.apply() 就可以得到前景的掩模了。
2:BackgroundSubtractorMOG2
这个也是以高斯混合模型为基础的背景/前景分割算法。它是以 2004 年和 2006 年 Z.Zivkovic 的两篇文章为基础的。这个算法的一个特点是它为每一个像素选择一个合适数目的高斯分布。(上一个方法中我们使用是 K 高斯分布)。这样就会对由于亮度等发生变化引起的场景变化产生更好的适应。
和前面一样我们需要创建一个背景对象。但在这里我们我们可以选择是否检测阴影。如果detectShadows = T rue(默认值),它就会检测并将影子标记出来,但是这样做会降低处理速度。影子会被标记为灰色。
3:BackgroundSubtractorGMG
此算法结合了静态背景图像估计和每个像素的贝叶斯分割。这是 2012年Andrew_B.Godbehere, Akihiro_Matsukawa 和 Ken_Goldberg 在文章中提出的。它使用前面很少的图像(默认为前 120 帧)进行背景建模。使用了概率前景估计算法(使用贝叶斯估计鉴定前景)。这是一种自适应的估计,新观察到的
对象比旧的对象具有更高的权重,从而对光照变化产生适应。一些形态学操作如开运算闭运算等被用来除去不需要的噪音。在前几帧图像中你会得到一个黑色窗口。
对结果进行形态学开运算对与去除噪声很有帮助。

BackgroundSubtractorMOG 的结果
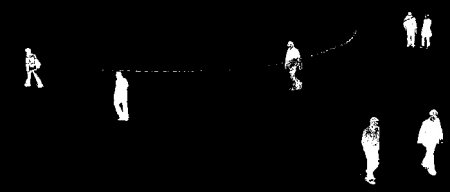
BackgroundSubtractorMOG2 的结果
灰色区域代表阴影

BackgroundSubtractorGMG 的结果
使用形态学开运算将噪音去除。