MapReduce是分布式、并行、离线的计算框架









Wordcount框架搭建(自己实现一个)











![]()
到此大概框架就是这样了。接下来就是实现此框架
一行数据执行一次map方法



对应reduce的输入阶段如下:




map阶段找到map,reduce阶段找到reduce。
接下来就是进行测试




![]()

![]()



无论map还是reduce都是要有输出
package qf.com.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/*
*类说明:自定义wordcount(词频统计)
*
*input
*
*words
hello qianfeng hello word
hi qianfeng hi world
best best best
*
*map阶段
*行偏移量:每一行的第一个字母距离该文件的首位置的距离
*
*
*Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*
* KEYIN 行偏移量(map阶段输入key类型)
* VALUEIN map阶段输入value类型
* KEYOUT map阶段输出key的类型
* VALUEOUT map阶段输出value的类型
*map阶段的输入数据:
*0 hello qianfeng hello word
*27 hi qianfeng hi world
*47 best best best
*
*map阶段的输出数据:
*best 1
*best 1
*best 1
*hello 1
*hello 1
*hi 1
*hi 1
*qianfeng 1
*qianfeng 1
*world 1
*world 1
*
*
*reduce阶段的输入:
*
*Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*
*KEYIN reduce阶段输入key类型(必须和map阶段的输出key类型相同)
*VALUEIN reduce阶段输入value类型(必须和map阶段的输出value类型相同)
*KEYOUT reduce阶段最终输出的key类型
*VALUEOUT reduce阶段最终输出的value类型
*
*reduce阶段的输入数据:
*best list<1, 1, 1>
*hello list<1, 1>
*hi list<1, 1>
*qianfeng list<1, 1>
*world list<1, 1>
*
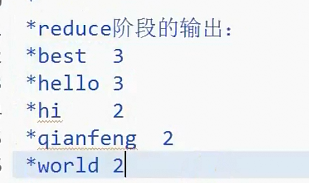
*reduce阶段的输出:
*best 3
*hello 2
*hi 2
*qianfeng 2
*world 2
*/
public class MyWordCount {
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
public static Text k = new Text();
public static IntWritable v = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//1.从输入数据中获取每一个文件中的每一行的值
String line = value.toString();
//2.对每一行的数据进行切分(有的不用)
String [] words = line.split(" ");
//3.循环处理
for (String word : words) {
k.set(word);
v.set(1);
//map阶段的输出 context上下文环境变量
context.write(k, v);//这个输出在循环里面 有一个输出一个
}
}
}
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
//1.自定义一个计数器
int counter = 0;
for (IntWritable i : values) {
counter += i.get();
}
//2.reduce阶段的最终输出
context.write(key, new IntWritable(counter));
//这个输出在循环外面 等统计完了这一个容器再输出
}
}
//驱动
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.获取配置对象信息
Configuration conf = new Configuration();
//2.对conf进行设置(没有就不用)
//3.获取job对象 (注意导入的包)
Job job = Job.getInstance(conf, "mywordcount");
//4.设置job的运行主类
job.setJarByClass(MyWordCount.class);
System.out.println("jiazai finished");
//5.对map阶段进行设置
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));//具体路径从控制台输入
System.out.println("map finished");
//6.对reduce阶段进行设置
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.out.println("reduce finished");
//7.提交job并打印信息
int isok = job.waitForCompletion(true) ? 0 : 1;
//退出job
System.exit(isok);
System.out.println("all finished");
}
}
