MapReduce自定义数据类型
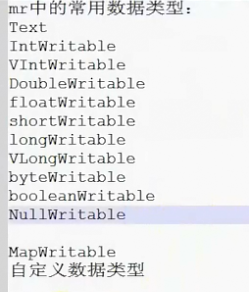










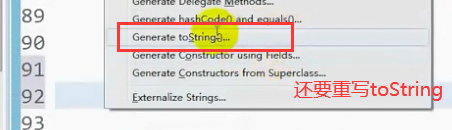

到此,自定义的类型已经OK了。
package qf.com.mr;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/*
*类说明:
*1.自定义数据类型需要实现Writable(不能排序)、或者WritableComparable(可排序)
*2.实现该实现的方法 write readFields compareTo
*3.方法write readFields 里面的字段个数和顺序要一致 类型要匹配
*4.可以重写toString equal hashcode等方法
*
*
*
*Top-N
数据
hello qianfeng hello qianfeng qianfeng is best qianfeng is better
hadoop is good
spark is nice
取统计后的前三名:
qianfeng 4
is 3
hello 2
*/
public class TopNWritable implements WritableComparable<TopNWritable>{
public String word;
public int counter;
public TopNWritable() {
}
public TopNWritable(String word, int counter) {
super();
this.word = word;
this.counter = counter;
}
/**
* 序列化
*/
public void write(DataOutput out) throws IOException {
out.writeUTF(this.word);
out.writeInt(this.counter);
}
/**
* 反序列化
*/
public void readFields(DataInput in) throws IOException {
this.word = in.readUTF();
this.counter = in.readInt();
}
public int compareTo(TopNWritable o) {
return o.counter - this.counter;//倒排
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public int getCounter() {
return counter;
}
public void setCounter(int counter) {
this.counter = counter;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + counter;
result = prime * result + ((word == null) ? 0 : word.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
TopNWritable other = (TopNWritable) obj;
if (counter != other.counter)
return false;
if (word == null) {
if (other.word != null)
return false;
} else if (!word.equals(other.word))
return false;
return true;
}
@Override
public String toString() {
return "[" + word + "\t" + counter + "]";
}
}
MapReduce的top-N


统计完数据后,再调用刚刚自己写的方法进行获取前几名





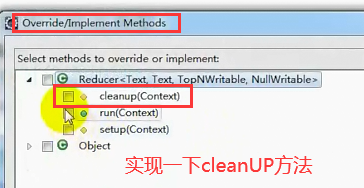


导出jar包,放到home目录下面,然后就是造数据 ![]()

![]()
![]()

到此,获取前几个的也就OK了。
package qf.com.mr;
import java.io.IOException;
import java.util.TreeSet;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/*
*类说明:Top-N
*就是求前几名
....
*/
public class TopNDemo implements Tool {
/**
* map阶段
*
* @author HP
*
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String words[] = line.split(" ");
for (String s : words) {
context.write(new Text(s), new Text(1 + ""));
}
}
}
/**
* reduce阶段
*/
public static class MyReducer extends Reducer<Text, Text, TopNWritable, NullWritable> {
public static final int TOP_N = 3;
//定义一个最终输出结果
TreeSet<TopNWritable> ts = new TreeSet<TopNWritable>();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int counter = 0;
for (Text t : values) {
counter += Integer.parseInt(t.toString());
}
//构造最终输出类型
TopNWritable tn = new TopNWritable(key.toString(), counter);
//将tn对象添加到ts
ts.add(tn);
//如果ts里面的数据个数大于TOP_N的时候将移除最后一个(最大的在上面)
if(ts.size() > TOP_N) {
ts.remove(ts.last());
}
//context.write(tn, NullWritable.get());
}
@Override
protected void cleanup(Context context)
throws IOException, InterruptedException {
//循环打印ts中的元素
for (TopNWritable tn : ts) {
context.write(tn, NullWritable.get());
}
}
}
public void setConf(Configuration conf) {
// 对conf的属性设置
conf.set("fs.defaultFS", "hdfs://qf");
conf.set("dfs.nameservices", "qf");
conf.set("dfs.ha.namenodes.qf", "nn1, nn2");
conf.set("dfs.namenode.rpc-address.qf.nn1", "hadoop01:9000");
conf.set("dfs.namenode.rpc-address.qf.nn2", "hadoop02:9000");
conf.set("dfs.client.failover.proxy.provider.qf",
"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
}
public Configuration getConf() {
return new Configuration();
}
public int run(String[] args) throws Exception {
// 1.获取配置对象信息
Configuration conf = new Configuration();
// 2.对conf进行设置(没有就不用)
// 3.获取job对象 (注意导入的包)
Job job = Job.getInstance(conf, "job");
// 4.设置job的运行主类
job.setJarByClass(TopNDemo.class);
// set inputpath and outputpath
setInputAndOutput(job, conf, args);
// System.out.println("jiazai finished");
// 5.对map阶段进行设置
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// System.out.println("map finished");
// 6.对reduce阶段进行设置
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(TopNWritable.class);
job.setOutputValueClass(NullWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
}
// 主方法
public static void main(String[] args) throws Exception {
int isok = ToolRunner.run(new Configuration(), new TopNDemo(), args);
System.out.println(isok);
}
/**
* 处理参数的方法
*
* @param job
* @param conf
* @param args
*/
private void setInputAndOutput(Job job, Configuration conf, String[] args) {
if (args.length != 2) {
System.out.println("usage:yarn jar /*.jar package.classname /* /*");
return;
}
// 正常处理输入输出参数
try {
FileInputFormat.addInputPath(job, new Path(args[0]));
FileSystem fs = FileSystem.get(conf);
Path outputpath = new Path(args[1]);
if (fs.exists(outputpath)) {
fs.delete(outputpath, true);
}
FileOutputFormat.setOutputPath(job, outputpath);
} catch (Exception e) {
e.printStackTrace();
}
}
}
MapReduce的二次排序


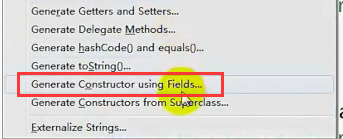
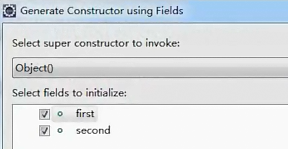


到此,自定义数据类型就可以了。
然后写一个Delme![]()




也就是首先写一个自定义类型,然后写一个MapReduce,Map端的输出key是自定义数据类型
现在就可以导jar包,将包拉到home目录下,上传到根目录下。
创造数据
![]()
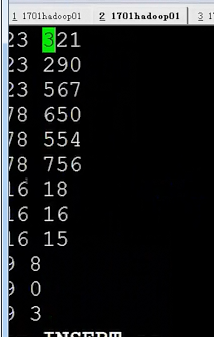
![]()
![]()

到此,排序就搞定了。
package qf.com.mr;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/*
*类说明:自定义类型
*/
public class SecondaryWritable implements WritableComparable<SecondaryWritable>{
public int first;
public int second;
public SecondaryWritable(int first, int second) {
super();
this.first = first;
this.second = second;
}
public SecondaryWritable() {
}
public int getFirst() {
return first;
}
public void setFirst(int first) {
this.first = first;
}
public int getSecond() {
return second;
}
public void setSecond(int second) {
this.second = second;
}
public void write(DataOutput out) throws IOException {
out.writeInt(this.first);
out.writeInt(this.second);
}
public void readFields(DataInput in) throws IOException {
this.first = in.readInt();
this.second = in.readInt();
}
public int compareTo(SecondaryWritable o) {
int tmp = 0;
tmp = this.first - o.first;//升序
if(tmp != 0) {
return tmp;
}
return this.second - o.second;
}
@Override
public String toString() {
return "SecondaryWritable [first=" + first + ", second=" + second + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + first;
result = prime * result + second;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
SecondaryWritable other = (SecondaryWritable) obj;
if (first != other.first)
return false;
if (second != other.second)
return false;
return true;
}
}
package qf.com.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/*
*类说明:
....
*/
public class SecondaryDemo implements Tool{
/**
* map阶段
*
*/
public static class MyMapper extends Mapper<LongWritable, Text, SecondaryWritable, Text>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String words [] = line.split(" ");
SecondaryWritable sw = new SecondaryWritable(Integer.parseInt(words[0]),Integer.parseInt(words[1]));
context.write(sw, new Text(words[1]));
}
}
/**
* reduce阶段
*/
public static class MyReducer extends Reducer<SecondaryWritable, Text, SecondaryWritable, Text>{
@Override
protected void reduce(SecondaryWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
//输出分隔符
context.write(new SecondaryWritable(), new Text("----------"));
//直接输出
context.write(key, new Text(""));
}
}
public void setConf(Configuration conf) {
// 对conf的属性设置
conf.set("fs.defaultFS", "hdfs://qf");
conf.set("dfs.nameservices", "qf");
conf.set("dfs.ha.namenodes.qf", "nn1, nn2");
conf.set("dfs.namenode.rpc-address.qf.nn1", "hadoop01:9000");
conf.set("dfs.namenode.rpc-address.qf.nn2", "hadoop02:9000");
conf.set("dfs.client.failover.proxy.provider.qf", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
}
public Configuration getConf() {
return new Configuration();
}
public int run(String[] args) throws Exception {
// 1.获取配置对象信息
Configuration conf = new Configuration();
// 2.对conf进行设置(没有就不用)
// 3.获取job对象 (注意导入的包)
Job job = Job.getInstance(conf, "job");
// 4.设置job的运行主类
job.setJarByClass(SecondaryDemo.class);
//set inputpath and outputpath
setInputAndOutput(job, conf, args);
// System.out.println("jiazai finished");
// 5.对map阶段进行设置
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// System.out.println("map finished");
// 6.对reduce阶段进行设置
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(SecondaryWritable.class);
job.setOutputValueClass(Text.class);
return job.waitForCompletion(true) ? 0 : 1;
}
//主方法
public static void main(String[] args) throws Exception {
int isok = ToolRunner.run(new Configuration(), new SecondaryDemo(), args);
System.out.println(isok);
}
/**
* 处理参数的方法
* @param job
* @param conf
* @param args
*/
private void setInputAndOutput(Job job, Configuration conf, String[] args) {
if(args.length != 2) {
System.out.println("usage:yarn jar /*.jar package.classname /* /*");
return ;
}
//正常处理输入输出参数
try {
FileInputFormat.addInputPath(job, new Path(args[0]));
FileSystem fs = FileSystem.get(conf);
Path outputpath = new Path(args[1]);
if(fs.exists(outputpath)) {
fs.delete(outputpath, true);
}
FileOutputFormat.setOutputPath(job, outputpath);
} catch (Exception e) {
e.printStackTrace();
}
}
}
MapReduce多表的join连接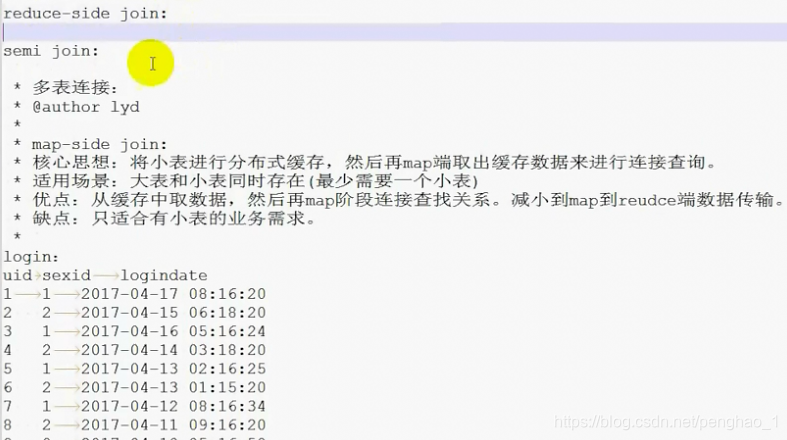

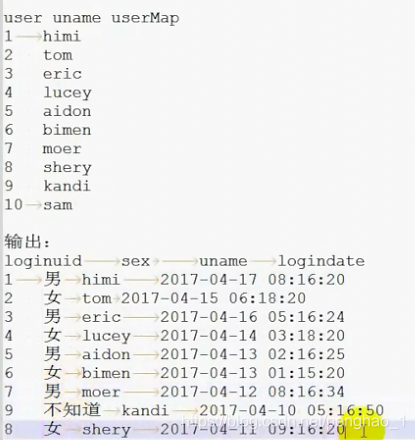

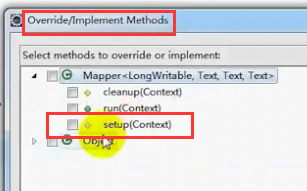
添加setUp,执行map之前先执行setup






然后就可以导出jar包,然后拷贝到home目录下
![]()
![]()


到此,多表关联就OK了。
package qf.com.mr;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import com.google.common.collect.Multiset.Entry;
/*
*类说明:多表连接
....
*/
public class MultiTableJoinDemo implements Tool{
/**
* map阶段
*
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text>{
public Map<String, String> sexMap = new ConcurrentHashMap<String, String>();
public Map<String, String> userMap = new ConcurrentHashMap<String, String>();
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
//首先获取缓存文件路径
Path [] paths = context.getLocalCacheFiles();
for (Path path : paths) {
//获取文件名字
String fileName = path.getName();
BufferedReader br = null;
String str = null;
if(fileName.equals("sex")) {//文件名为sex
br = new BufferedReader(new FileReader(new File(path.toString())));
while((str = br.readLine()) != null) {
String strs[] = str.split("\t");
sexMap.put(strs[0], strs[1]);
}
//关闭流
br.close();
}else if(fileName.equals("user")){
br = new BufferedReader(new FileReader(new File(path.toString())));
while((str = br.readLine()) != null) {
String strs[] = str.split("\t");
userMap.put(strs[0], strs[1]);
}
br.close();
}
}
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String fields [] = line.split("\t");
//fields[0] 就是uid
if(userMap.containsKey(fields[0])) {
context.write(new Text(fields[0] + "\t"
+ sexMap.get(fields[1]) + "\t"
+ userMap.get(fields[0]) + "\t"
+ fields[2]),
new Text(""));
}
/**
*
*/
/*for(Entry<String, String> S : sexMap.entrySet()) {
context.getCounter("login sex key" + ":" + fields[1], "sexmap key" + S.)
}*/
}
}
/**
* reduce阶段
*/
/*public static class MyReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
}
}*/
public void setConf(Configuration conf) {
// 对conf的属性设置
conf.set("fs.defaultFS", "hdfs://qf");
conf.set("dfs.nameservices", "qf");
conf.set("dfs.ha.namenodes.qf", "nn1, nn2");
conf.set("dfs.namenode.rpc-address.qf.nn1", "hadoop01:9000");
conf.set("dfs.namenode.rpc-address.qf.nn2", "hadoop02:9000");
conf.set("dfs.client.failover.proxy.provider.qf", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
}
public Configuration getConf() {
return new Configuration();
}
public int run(String[] args) throws Exception {
// 1.获取配置对象信息
Configuration conf = new Configuration();
// 2.对conf进行设置(没有就不用)
// 3.获取job对象 (注意导入的包)
Job job = Job.getInstance(conf, "job");
// 4.设置job的运行主类
job.setJarByClass(MultiTableJoinDemo.class);
//set inputpath and outputpath
setInputAndOutput(job, conf, args);
// System.out.println("jiazai finished");
// 5.对map阶段进行设置
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置缓存数据
job.addCacheFile(new URI(args[2]));
job.addCacheFile(new URI(args[3]));
// System.out.println("map finished");
// 6.对reduce阶段进行设置
/* job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);*/
return job.waitForCompletion(true) ? 0 : 1;
}
//主方法
public static void main(String[] args) throws Exception {
int isok = ToolRunner.run(new Configuration(), new MultiTableJoinDemo(), args);
System.out.println(isok);
}
/**
* 处理参数的方法
* @param job
* @param conf
* @param args
*/
private void setInputAndOutput(Job job, Configuration conf, String[] args) {
if(args.length != 4) {
System.out.println("usage:yarn jar /*.jar package.classname /* /*");
return ;
}
//正常处理输入输出参数
try {
FileInputFormat.addInputPath(job, new Path(args[0]));
FileSystem fs = FileSystem.get(conf);
Path outputpath = new Path(args[1]);
if(fs.exists(outputpath)) {
fs.delete(outputpath, true);
}
FileOutputFormat.setOutputPath(job, outputpath);
} catch (Exception e) {
e.printStackTrace();
}
}
}
