基本思路是
1、Scala的安装,
2、Spark的安装与配置。


1、打开Xshell ,将scala 与spark的安装包上传上去。

2、用ll命令查看,已经显示在里面了

3、接下来就是Scala的安装,安装目录也是放到data目录下。
将Scala解压到 指定目录下 (是当前目录下用 ./ 的data 里面)
![]() 回车。
回车。
4、进到data 里面,就发现多了一个Scala的文件夹

5、 进去,将Scala的当前路径拷贝下来。

6、先回到home目录下, 然后通过编辑命令编辑.bash_profile 文件
![]()
7、进入到.bash_profile 文件后,添加Scala的路径进去,并且将他的bin目录也添加进去
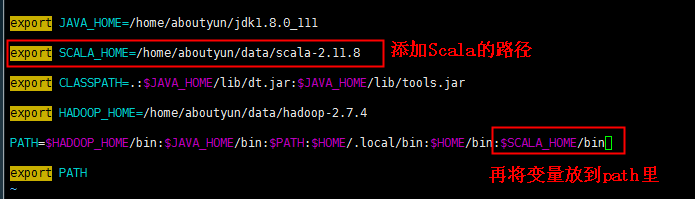
然后保存退出。
8、然后通过source 命令让他生效 ![]()
9、然后用 scala -version 进行验证。

10、把刚刚主节点上安装的Scala 配置文件,复制到所有从节点上。
先回到home下 ,输入命令 cd ~
![]()
scp -r data/scala-2.11.8 aboutyun@slave1:~/data/

同时也复制到 slave2的home目录下面的data文件夹里面
scp -r data/scala-2.11.8 aboutyun@slave2:~/data/
到此为止,就已经完成了。
注意:关于.bash_profile后面还需要进行配置Spark ,所以等到配置完Spark后再统一分发到从节点
避免重复。
到这里就可以开始Spark的安装了
1、先解压spark安装包,到 指定的 data下面
![]() 回车
回车
2、解压完后,通过进入data文件夹。通过查看命令,看到其已经解压到里面了

3、解压完后,就进行配置spark。(因为没有spark-env.sh文件,而是用它的template复制过来的
下面的.xml是写错了)

4、拷贝后,用编辑命令进入文件里面,进行配置添加几个环境变量

JAVA_HOME=/home/aboutyun/jdk1.8.0_111 SCALA_HOME=/home/aboutyun/scala-2.11.8 SPARK_MASTER_IP=192.168.1.10 HADOOP_CONF_DIR=/home/aboutyun/data/hadoop-2.7.4/etc/hadoop
# shuffled以及RDD的数据存放目录,用于写中间数据
SPARK_LOCAL_DIRS=/home/aboutyun/data/spark_data
# worker端进程的工作目录,包括worker的日志以及临时存储空间,默认:${SPARK_HOME}/work
SPARK_WORKER_DIR=/home/aboutyun/data/spark_data/spark_works
配置如下图所示:

配置完了,然后将 最后一个路径拷贝出来,等下需要创建
通过下面的命令,对指定文件夹进行创建
![]() 回车
回车

到此为止,spark 的env就已经配置完了。
5、接下来就是配置spark的slave
先进入spark的conf里面

因为没有slave这个文件,所以需要从template里面拷贝出来一个 用 cp 命令 cp slave.template slave
然后 进入编辑 vi slave

6、将 主节点,从节点都加上 ,然后保存退出
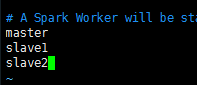
到这来就配置完了,接下来就是Spark默认的配置文件了
因为Spark应用启动的时候,需要读取一些配置文件。
7、同理,配置spark-defaults.conf 文件。但是没有,所以需要将他们拷贝一个出来
![]()
然后,进入编辑命令 vi spark-defaults.conf 然后对其文件进行编辑

复制进去。 保存退出。
8、然后继续配置spark的环境变量

将此路径放到 .bash_profile文件中
先回到home目录下, 然后通过编辑 .bash_profile
![]()
不仅要配置SPARK_HOME路径,还需要配置它的bin和sbin

然后保存退出。
然后为了使环境变量生效,所以需要输入 source .bash_profile 命令 回车
9、接下来就是将安装包目录分发到其他节点。
使用命令 复制 data/spark-2.0.2-bin-hadoop2.7 到 aboutyun用户的 slave1节点 的home目录下的 data/下面
scp -r data/spark-2.0.2-bin-hadoop2.7 aboutyun@slave1:~/data/
![]() 回车。
回车。
同样的也要复制给slave2
因为配置scala的时候没有把环境变量拷过去,而现在呢,可以将spark 与scala一起拷过去
输入命令 scp .bash_profile aboutyun@slave1:~/ 回车
scp .bash_profile aboutyun@slave2:~/ 回车
如图所示

拷贝完成后。
10、拷贝完后,进入到分别进入到slave1 ,slave2里面执行生效
![]()
![]()
到这来基本的配置就配置完了,文件也分发完了。接下来就是可以启动集群了,。
11、启动集群。 是进去到spark 的sbin目录下去启动集群
先进入到data目录下面的 spark目录里面
![]()
然后再进入它的sbin目录

然后就可以启动了(需要启动两个脚本,一个是master ,一个是slaves) 如图所示


启动完后,可以通过 http://master:8080/ 访问

起来了,一般是通过这个界面进行spark的查看。
到此为止 Spark的安装已经可以了。
Scala的安装配置
1、
ll 看出是否已经上传压缩包上来了
tar -zxvf scala-2.11.8.tgz -C ./data/
tar -zxvf 需要解压的文件 -C 到制定的文件夹或者目录
进入到scala
将其路径拷贝出来,退出回到home下,进入.bash_profile 文件进行编辑,
添加scala进去。并且将其bin也添加进去。 $SCALA_HOME/bin 然后保存退出。
只要对.bash_profile 文件进行了修改,都需要对其进行source 一下,确保文件生效
source .bash_profile
然后通过scala -version 验证版本号。
接着就是将scala的配置文件,从主节点复制到从节点
scp -r data/scala-2.11.8 aboutyun@slave1:~/data/
将data/scala-2.11.8文件 -r 递归复制整个目录到 aboutyun用户下的 slave1的节点 的home目录下面的 data下面
同时复制到第二个节点下面
scp -r data/scala-2.11.8 aboutyun@slave2:~/data/
到此,则将整个scala的解压包复制到从节点上了。
但是它的.bash_profile文件则还没有进行复制,因为后续要装spark后再一次复制过去。
接下来就是spark安装配置
先解压spark安装包,到指定的data目录下面,
tar -zxvf spark-.... -C data/
解压后,通过ll查看
-----------------
在这里还需要对spark的文件进行配置一下。
解压完后,进入到spark-2...目录下面的conf目录下的配置文件里面
要配置 spark-env.sh ,slaves(配置节点),spark-defaults.conf 主要是配置这三个文件
1、第一个因为没有spark-env.sh 而是从它对应的template进行复制, 命令是
cp spark-env.sh.template spark-env.sh 然后进行编辑该文件
JAVA_HOME=/home/aboutyun/jdk1.8.0_111
SCALA_HOME=/home/aboutyun/data/scala-2.11.8
SPARK_MASTER_IP=192.168.1.10
HADOOP_CONF_DIR=/home/aboutyun/data/hadoop-2.7.4/etc/hadoop
SPARK_LOCAL_DIRS=/home/aboutyun/data/spark_data
SPARK_WORKER_DIR=/home/aboutyun/data/spark_data/spark_works
现进行编辑,然后保存退出。同时将最后一个路径拷贝出来,因为要给它创建文件夹
mkdir -p /home/aboutyun/data/spark_data/spark_works(路径)
到这里,spark的env配置完成。
2、同时也是因为没有slaves,是通过拷贝slaves.template
cp slaves.template slaves 然后进入编辑该文件脚本
添加 主节点和所有从节点。
master
slave1
slave2
然后保存退出。
3、就是需要配置一些spark启动时候的配置文件了
同时也是因为没有spark-default.conf文件,也是通过拷贝spark-default.conf.template而得
cp spark-default.conf.template spark-default.conf 然后进入编辑该脚本
添加对应的信息。
spark.master spark://master:7077
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.eventLog.enabled true
spark.eventLog.dir file:///data/spark_data/history/event-log
spark.history.fs.logDirectory file:///data/spark_data/history/spark-events
spark.eventLog.compress true
然后保存退出。
------------------
接下来就是配置Spark的环境变量
进入 解压后的spark 文件夹 ,拷贝其当前路径。
然后退出,回到home目录下面,进入编辑 .bash_profile文件
将其spark_home粘贴进去,并且 将其bin与sbin 都进行粘贴上去
$SPARK_HOME/bin:$SPARK_HOME/sbin ,然后保存退出,
然后接着就是将安装包目录分发到各个从节点(也就是用复制命令)
scp -r data/spark-.... aboutyun@slave1:~/data 回车
scp -r data/spark-2... aboutyun@slave2:~/data 回车
到此,spark的安装包目录以及分发完毕
接着就是要将他们的配置文件分发到从节点去
scp .bash_profile aboutyun@slave1:~/ 回车
scp .bash_profile aboutyun@slave2:~/ 回车
拷贝完后,分别进入到各个从节点上去执行生效命令 source .bash_profile
到这里,文件也分发完了。然后就可以启动集群了
注意点是,要在主节点上进行测试 ,也就是在master上测试
进入到spark的 sbin目录 下面
然后就输入 ./start-master.sh
./start-slaves.sh
启动弯这两个脚本之后,用jps验证一下。就可以看到了
最后可以通过 http://master:8080/进行访问。 或者将master改为主机ip
到此,spark的安装就可以了
