1.简单说一下红黑树
由于TreeMap是由红黑树实现的,所以我们先说一下什么是红黑树。
首先,红黑树是一种自平衡的二叉查找树,是一种高效的二叉查找树,其具有良好的效率,它可在O(logN)的时间内完成查找、增加删除等操作。
学过二叉查找树的同学都知道,普通的二叉查找树在极端情况下可退化成链表,此时的增删查效率都会比较低下。
为了避免这种情况,就出现了一些自平衡的查找树,比如 AVL,红黑树等。这些自平衡的查找树通过定义一些性质,将任意节点的左右子树高度差控制在规定范围内,以达到平衡状态。
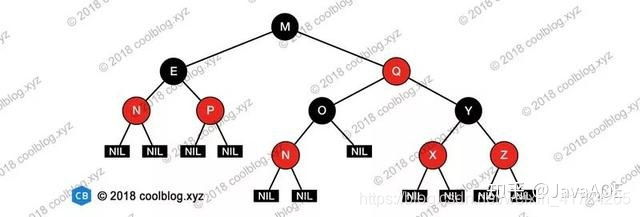
红黑树通过如下的性质定义实现自平衡:
节点是红色或黑色。
根是黑色。
所有叶子都是黑色(叶子是NIL节点)。
每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点(简称黑高)。
2.Map体系
还是放上这个图:
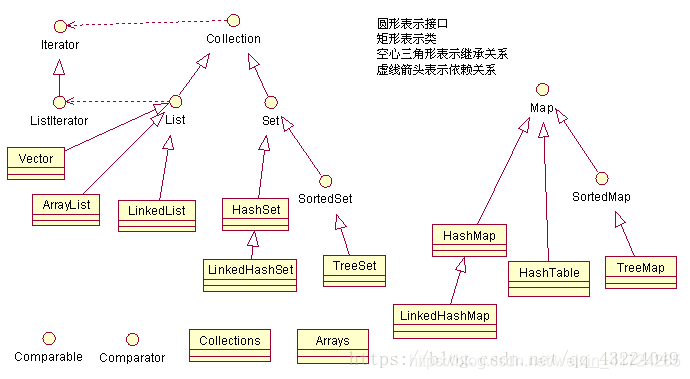
首先,我们需要明确HashMap、HashSet、TreeMap、TreeSet的区别与联系:
注意:Map是提供key到value的映射关系的,我们可以理解为是用来存储键值对的。
而Set是用来存储对象的。我们可以理解为是用来存储键的。当然,每一个Set在底层都会维护一个Map进行支持。
3.Hashtable、HashMap、TreeMap有什么不同?
Hashtable 是早期 Java 类库提供的一个哈希表实现,本身是同步的,不支持 null 键和值,由于同步导致的性能开销,所以已经很少被推荐使用。
HashMap 是应用更加广泛的哈希表实现,行为上大致上与 HashTable 一致,主要区别在于 HashMap 不是同步的,支持 null 键和值等。通常情况下,HashMap 进行 put 或者 get 操作,可以达到常数时间的性能,所以它是绝大部分利用键值对存取场景的首选,比如,实现一个用户 ID 和用户信息对应的运行时存储结构。
TreeMap 则是基于红黑树的一种提供顺序访问的 Map,和 HashMap 不同,它的 get、put、remove 之类操作都是 O(log(n))的时间复杂度,具体顺序可以由指定的 Comparator 来决定,或者根据键的自然顺序来判断。
