特征工程是机器学习,甚至是深度学习中最为重要的一部分,也是课本上最不愿意讲的一部分。特征工程是data science中最有创造力的一部分。因为往往和具体的数据相结合,很难优雅的系统的讲好。所以课本上会讲一下理论知识比较扎实的归一化,降维等部分,而忽略一些很dirty hand的特征工程技巧。
Kaggle上有一句非常经典的话,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已,而这恰恰是课堂上最为缺失,一门需要在实践中学习的手艺。
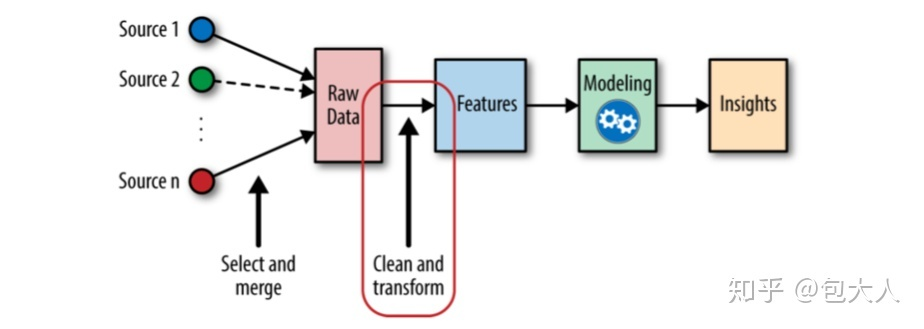
简单来说,如下图所示,特征工程就是通过X,创造新的X'。基本的操作包括,衍生(升维),筛选(降维)。说起来简单,实际中,衍生和筛选都是困难重重,甚至需要非常专业的专家知识。
特征工程主要分成以下几个部分:
-
data exploration:拿到数据的第一步当然是看看数据是怎么样的,也就是看看里面有什么特征,这些特征什么意思,看看数据是不是结构化的,是不是有空缺数据,用一些图形看看数据长什么样?看看有哪些特征是数值化的(又分为连续和离散的),哪些数值是
-
feature cleaning:这一步要做的是在数据理解的基础上,得到一个比较整齐的数据,把未结构化的数据结构化,填充空值,对数据标准化。但是这并不能保证我们的数据和模型是强相关的,我们还不能吧这些数据用在模型中,还需要后续的处理。
-
feature engineering:
- 特征构造:构建未有的特征,从我们已有的特征中构建未有的特征
- 特征转换:
-
feature selection:去掉坏的特征,有些特征和我们的模型不相关,有些特征是有关联的,只需要保留一个就可以了。
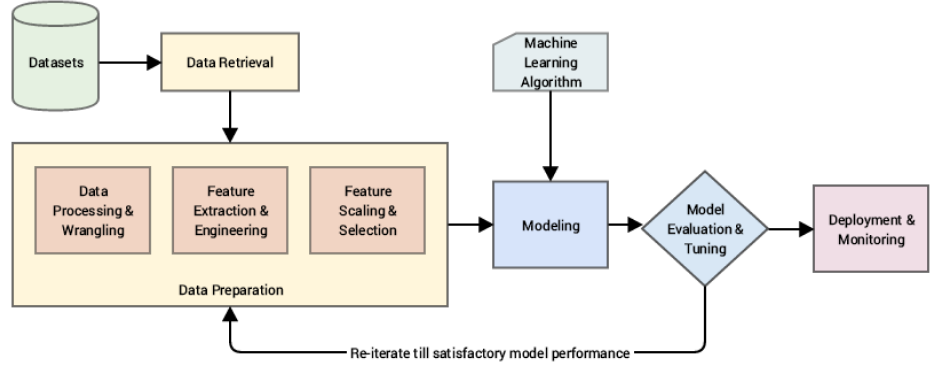
一个典型的机器学习过程: