机器学习中所需要用到的数学知识:
微积分 线性代数 概率论 最优化方法
1.导数
求导公式
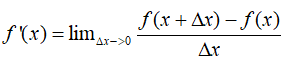
(一元)左导数与右导数都存在且相等,此处的导数才存在。
基本函数求导:
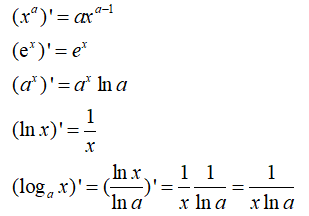
两个重要极限:
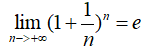 单调有界的序列必定收敛
单调有界的序列必定收敛
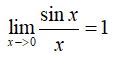 夹逼定理
夹逼定理
导数四则运算:

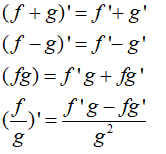
复合函数求导:
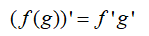
高阶导数:
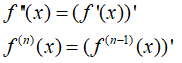
导数与函数单调性的关系:
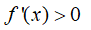 :函数在此点单调增
:函数在此点单调增
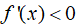 :函数在此点单调减
:函数在此点单调减
极值定理:
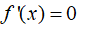 :(驻点)函数在此点是极值点,可能是极大值(二阶导小于零),也可能是极小值(二阶导大于零)可能是拐点(二阶导等于零)
:(驻点)函数在此点是极值点,可能是极大值(二阶导小于零),也可能是极小值(二阶导大于零)可能是拐点(二阶导等于零)
拐点是凹函数与凸函数的交替点。
导数与函数凹凸性的关系:
凸函数:函数内任意两点的连线,大于两点间的任一点的函数值。
凹函数:函数内任意两点的连线,小于两点间的任一点的函数值。
二阶导大于零,是凸函数。
二阶导小于零,是凹函数。
2.一元函数泰勒展开
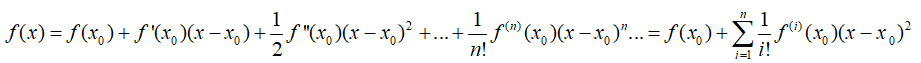
3.向量
向量与其运算:
向量分为行向量和列向量。
转置:行向量转置变为列向量,列向量转置变为行向量。
加法:对应位置分量相加
减法:对应位置分量相减
数乘:数与每个分量分别相乘
内积:两个向量的对应分量相乘再相加,两个向量转换为一个标量
a=(a1,a2,...,an),b=(b1,b2,...,bn)-------->a与b内积=a1b1+a2b2+...+anbn
向量的范数
L-P:L的P范数:
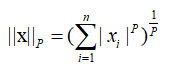 ,P一般取整数。
,P一般取整数。
L-1范数: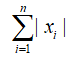
L-2范数: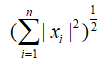
3.矩阵
矩阵与其运算
方阵,对称矩阵,单位矩阵,对角线
方阵:行数和列数相等,n阶方阵:行数和列数都为n
对称矩阵:关于主对角线对称相等
对角线:分为主对角线和副对角线
对角矩阵:只有对角线上有非零元素,其他位置都为零
单位矩阵:主对角线的元素全为1,其他位置全为0
矩阵的运算:加法,减法,数乘,转置
转置:行分量变为列分量
加法:对应元素相加
减法:对应元素相减
相乘:第一个矩阵的每一行与第二矩阵的每一列相乘再相加
数乘:数与每个元素相乘
逆矩阵
A:n阶方阵
I:n阶单位矩阵
若存在BA=I,则B为A的左逆。
若存在AB=I,则B为A的右逆。
结论:若一个矩阵A的逆矩阵存在,那么左逆=右逆。
A的行列式不等于零,可逆。|A| != 0
矩阵满秩就是可逆的。
满秩就是矩阵所有的行,所有的列都是线性无关的。
表示: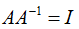
矩阵运算法则:
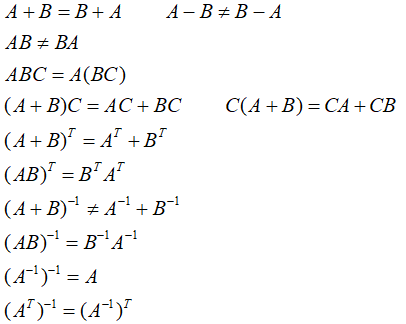
4.行列式
|A|------>a
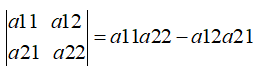
n阶行列式: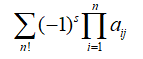 s为逆序数,j为1到n的全排列,所以是n的全排列个数相加
s为逆序数,j为1到n的全排列,所以是n的全排列个数相加
简便判定正负号方法,与主对角线方向相同为正,与副对角线方向相同为负。
5.偏导数与梯度
偏导数:
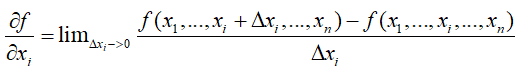
梯度(列向量):
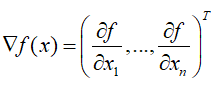
6.雅可比矩阵
X:n维向量 Y:m维向量
X----->Y:n维向量向m维向量的映射
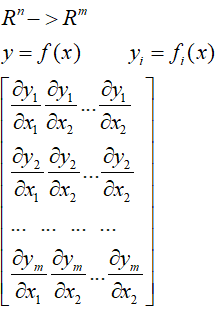
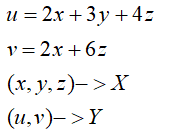
雅可比矩阵:
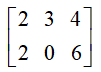
7.Hessian矩阵

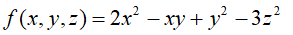
Hessian矩阵
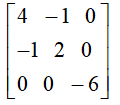
它是关于对角线对称的,混合求偏导一般与次序无关。(当f''xy与f''yx都连续时,求导结果与次序无关。)
Hessian矩阵与函数的性质有非常大的关系,它决定了函数的极值,与函数的凹凸性。
一元函数:f’(x)=0,可能是极值点,f’’(x)>0,是极小值,f’’(x)<0,极大值
多元函数: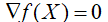 ,可能是极值点,Hession矩阵正定,极小值;Hession负定,极大值;Hession不定,再做判断。
,可能是极值点,Hession矩阵正定,极小值;Hession负定,极大值;Hession不定,再做判断。

否则就是不定。
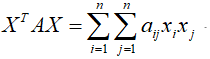
8.特征值与特征向量
针对方阵而言,不是方阵,就没有特征值与特征向量这么一说。
A为一个方阵,存在非零向量X,使得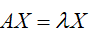 ,那么
,那么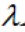 是A的特征值,X是属于特征值
是A的特征值,X是属于特征值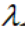 的特征向量。
的特征向量。
所有特征值之和等于方阵对角线之和(方阵的迹)。
所有特征值之积等于方阵行列式的值。
9.多元泰勒展开
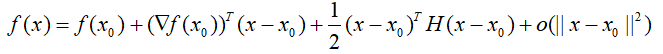
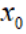 不是一个数,是一个向量,第三项相当于二分之一乘以一个二次型。
不是一个数,是一个向量,第三项相当于二分之一乘以一个二次型。
10.多元函数极值判别法则
,可能是极值点,Hession矩阵正定,极小值;Hession负定,极大值;Hession等于0,是鞍点。
11.特征值分解
对于一个矩阵A,存在一个正交变换,变换之后等于一个对角矩阵。
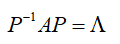
正交矩阵: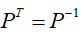 ,正交矩阵所有的行向量与列向量是相互正交的,两个向量正交就是这两个向量内积等于0,自身内积等于1,换句话说,两个向量是垂直的,且为单位长度。
,正交矩阵所有的行向量与列向量是相互正交的,两个向量正交就是这两个向量内积等于0,自身内积等于1,换句话说,两个向量是垂直的,且为单位长度。
P的求解,是求矩阵A的特征值,然后求特征值的特征向量,不同特征值的特征向量已经正交,同一特征值的不同特征向量不一定正交,用施密特正交化,使其正交,这些正交向量组成的矩阵就是P。
12.矩阵和向量求导
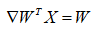
推导:
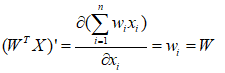
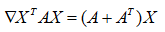
推导:
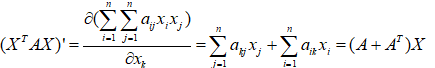
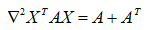
推导:
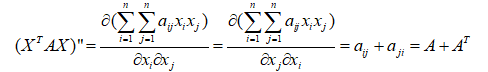
13.奇异值分解(SVD)
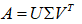
A:是一个m*n的矩阵
U:是一个m*m的正交矩阵(A*A的转置的特征向量构成的)
V:是一个n*n的正交矩阵(A的转置*A的特征向量构成的)
中间是一个(m*n的)对角阵,不是严格意义上的对角阵(不是方阵),对角线上有非零元素,其他元素都为零
14.随机事件与概率
随机事件:可能发生也可能不发生的事件
概率:事件发生的可能性大小
概率等于1,必然事件
概率等于0,不可能事件
15.条件概率与贝叶斯公式
条件概率:
P(B|A):A发生的条件下,B发生的概率
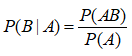
如果两个事件独立,P(AB)=P(A)P(B)
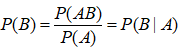
贝叶斯公式:
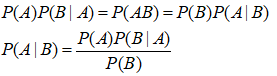
A是因,B是果,则P(B|A)是先验概率,P(A|B)是后验概率。
16.随机变量
离散型随机变量的概率值:
1.0<=P(x=xi)<=1
2.对P(x=xi)求和等于1,是完备的
连续型随机变量的概率值:
概率密度函数f(x)有以下性质:
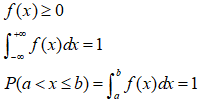
概率分布函数F(x)可以有如下表示:
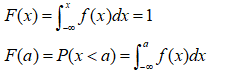
17.数学期望与方差
数学期望:
离散型: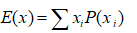
连续型: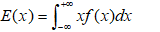
方差:
离散型: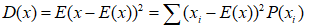
离散值减去它的期望的平方,再求期望
连续型: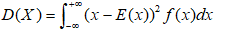
18,常用概率分布
均匀分布: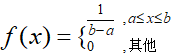
正态分布(高斯分布):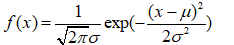
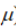 :均值,
:均值,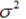 :方差,
:方差, :标准差
:标准差
二项分布(伯努利二项分布):x的取值只有0,1
P(x=1)=p, P(x=0)=1-p, 0<p<1
19.随机向量(联合概率密度函数,联合概率分布函数)
X=(x1,x2,...,xn)
连续型:
二维联合概率密度函数:
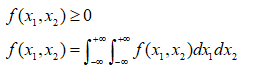
二维联合概率分布函数:
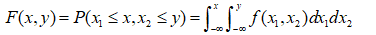
20.协方差
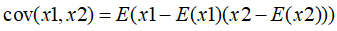
协方差表示两个向量之间的相关性,值越大,相关性越强。
独立同分布:两组变量都属于同一种分布,但是相互之间是独立的。
21.多维正态分布
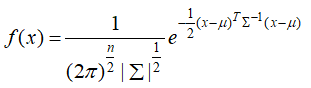
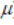 :均值向量
:均值向量 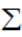 :协防差矩阵
:协防差矩阵
22.最大似然估计
x服从某种分布,求解该分布的未知变量。
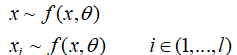
(1)每个xi都服从f这种分布,抽取l个事件,这些事件服从独立同分布
(2)这l个事件的联合概率密度等于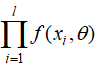 ,因为这些情况是现实中存在的,最大化这个概率,求解
,因为这些情况是现实中存在的,最大化这个概率,求解 。
。
最大化求解过程,要求导,连乘求导不好,取对数,再最大化,因为概率大于等于0,一般大于0,取对数没问题,又对数函数是个增函数,所以对数函数最大化,效果相同。